
This content originally appeared on DEV Community and was authored by Ivan Juren
Inspired by Anton Putra style of benchmarks (if you love graphs half as much as I do, you gotta check this guy out!), I decided to dig deeper into one of Kafka producer's most underrated yet powerful settings — linger.ms.
In this post, we'll explore what linger.ms does and how it impacts end-to-end latency, CPU usage, compression efficiency, and produce/fetch rates.
🧠 What Is linger.ms and Why Is It Important?
Every message sent to Kafka isn't just the payload — it's wrapped with metadata (topic name, partition, key, timestamp, checksums, headers, etc.).
Sending messages one by one would therefore carry significant network and serialisation overhead.
To optimise this, Kafka producers can bundle multiple records into a single batch, reducing the per-message overhead and improving throughput.
Now, the key question becomes: how big should that batch be, and when should it be sent?
That's exactly where linger.ms comes into play.
linger.ms defines how long the Kafka producer should wait before sending a batch of records to the broker.
- If
linger.ms>0, the producer waits up to that duration to fill the batch — allowing more messages to accumulate and be sent together. - If
linger.ms=0, records are sent immediately when the batch is full or as soon as a message arrives.
The result? Fewer network calls, better compression efficiency, and lower CPU usage — at the cost of slightly higher latency.
The Tradeoff
-
Lower
linger.ms→ lower latency, more overhead, higher CPU cost, worse compression. -
Higher
linger.ms→ higher latency, less overhead, lower CPU cost, better compression.
It's all about balancing throughput and latency depending on your use case.
🔍 Methodology
To measure the impact, I set up a 3-broker Kafka cluster using Docker Compose with the following stack:
- Kafka 4.0.0 (KRaft mode)
- JMX Exporter → Prometheus → Grafana for metrics
- Spring Boot producer and consumer
- The producer sends JSON payloads (~400B each) to a topic (replication:3, min ISR:2, acks: all) with adjustable
linger.ms. - The consumer stores messages in memory and calculates the difference in time → end-to-end latency that's reported separately.
The latency is measured using timestamps on both sides (System.currentTimeMillis()), so it reflects true client-perceived delay — not just broker-side performance.
Disclaimers: I'm doing all of this on one machine. In production, you'd want brokers on separate racks to reduce the chance of them all going down at the same time. To keep things simple, there's only one producer and one consumer. Since usual Kafka workloads have multiple consumers interested in the same stream, producer-side optimisations this way might exaggerate the impact you'd expect in production.
Stay tuned for follow-ups where I'll cover impactful consumer-side properties!
📊 Results and Analysis
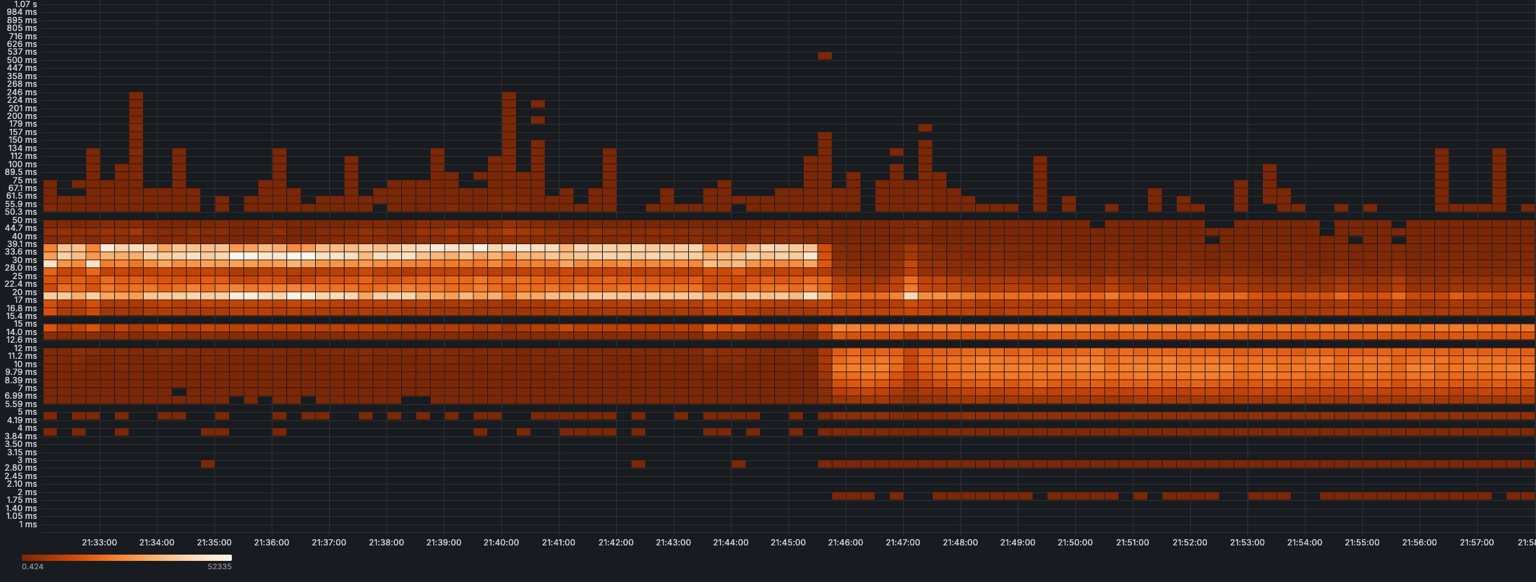
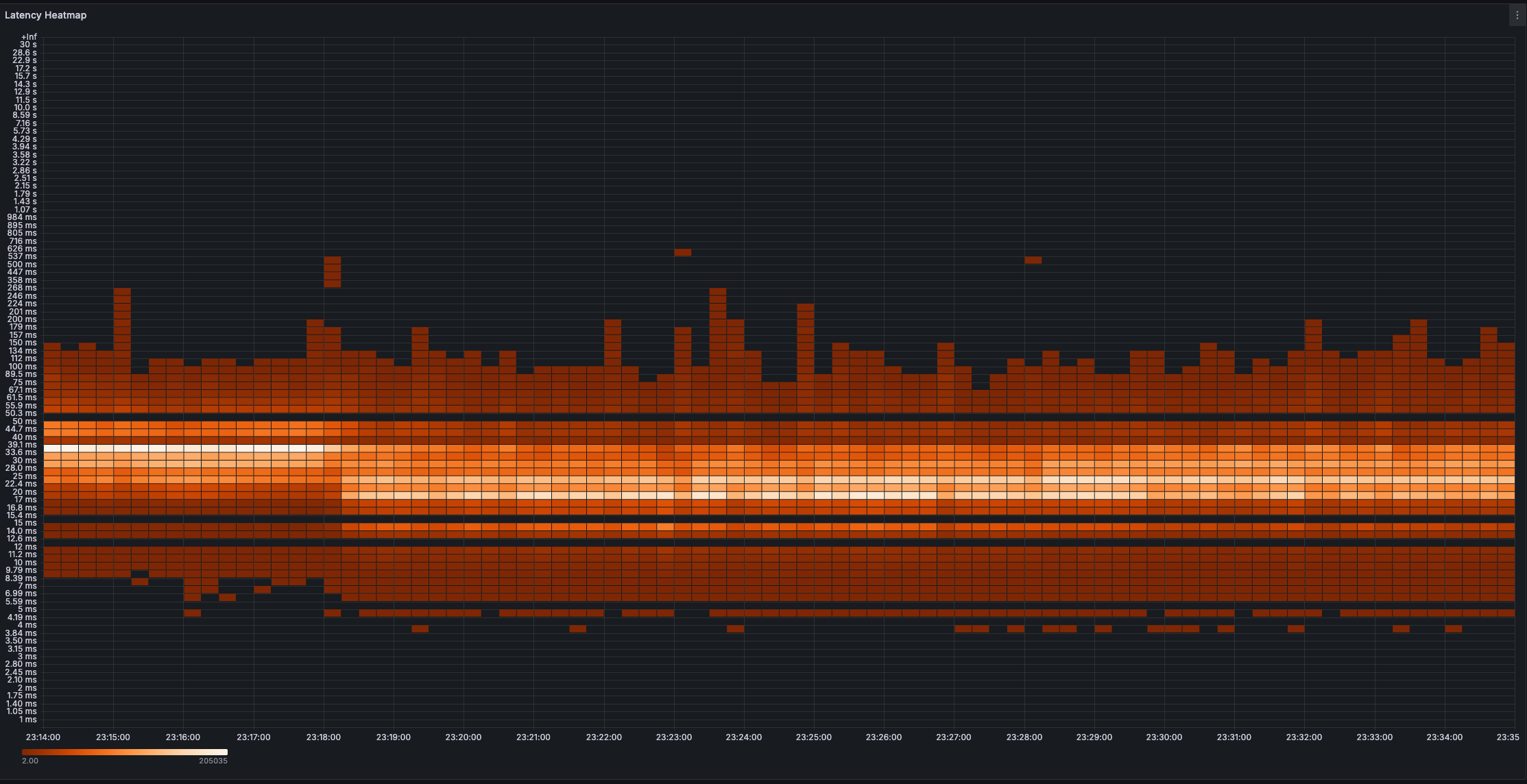
1️⃣ End-to-End Latency

Notice how decreasing linger.ms seems like a big win — the median latency drops from around 30 ms to 10 ms, perfectly
matching the 20 ms linger.ms we removed.
At first glance, that feels like a major improvement, but the long tail remains. The distribution still stretches into higher latencies, meaning not everything got faster. Usually, when deployed to the cloud with more distance between brokers, replication takes a bit longer. Since consumers are only served replicated messages, the effect on e2e latency isn't that big.
By the way, in Kafka clients 4.0, the default linger.ms is set to 5ms (from the old default of 0ms). Let's see why that might be a good idea.
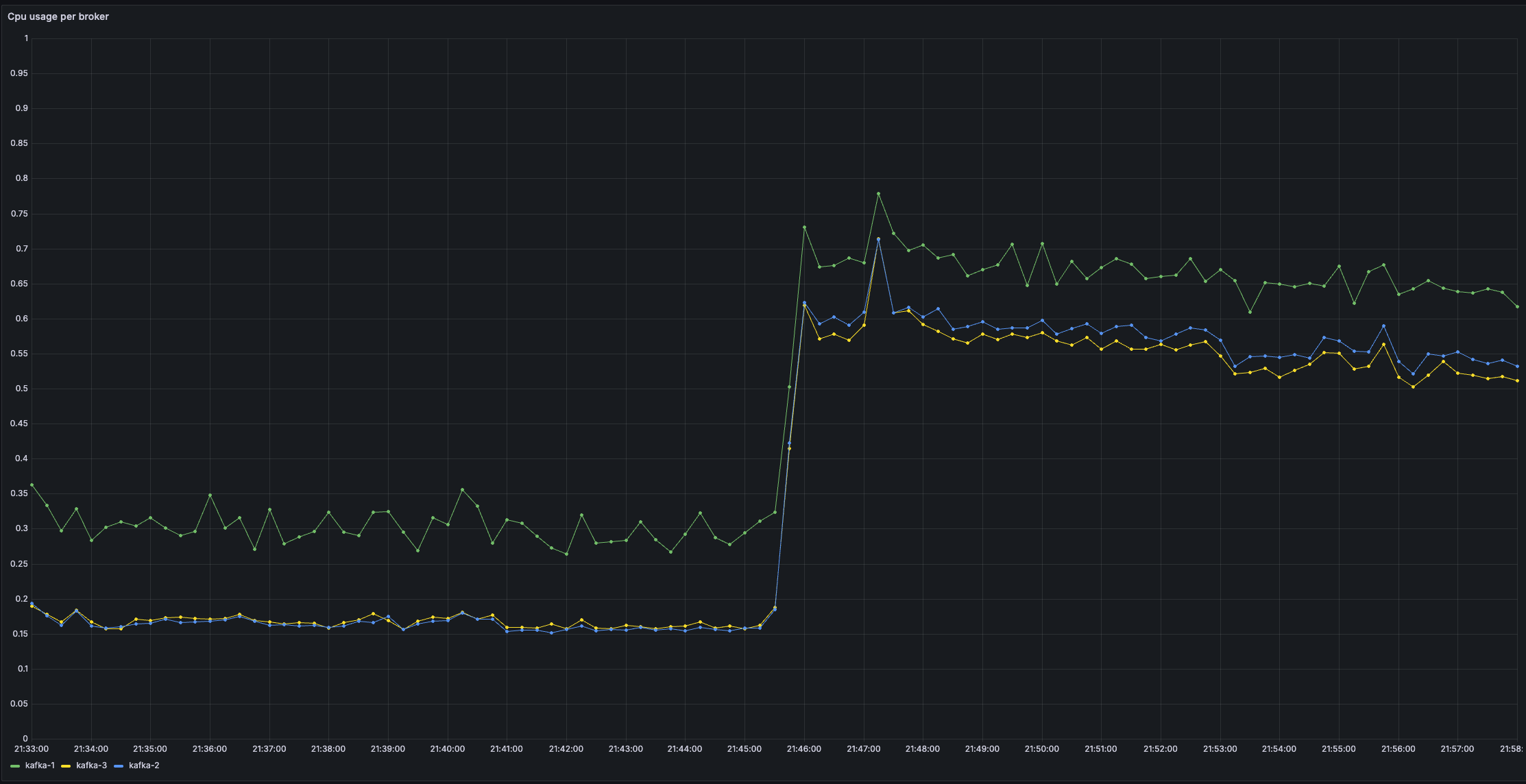
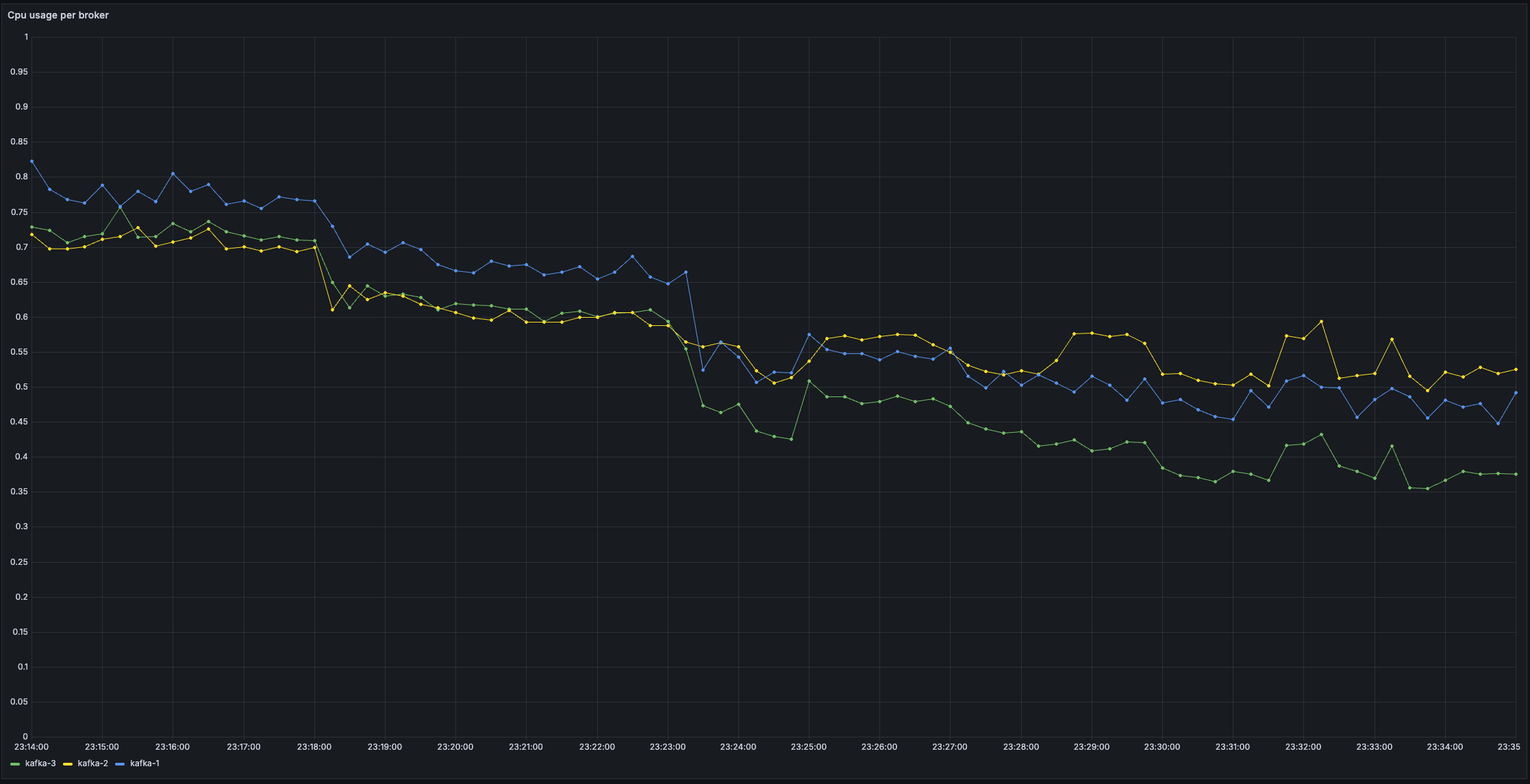
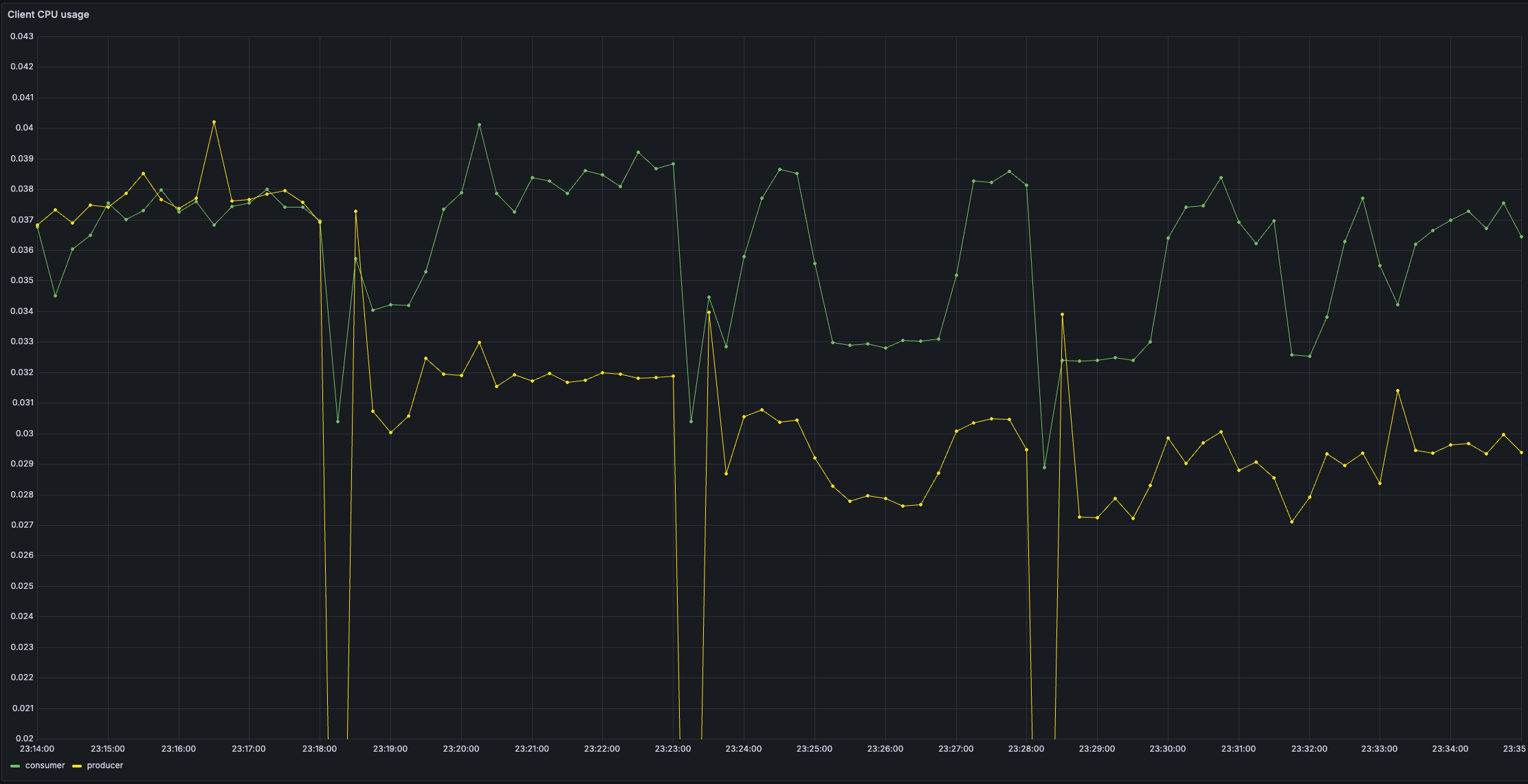
2️⃣ CPU Usage

Here's the CPU impact — and it's quite telling.
After decreasing linger.ms from 20 ms to 0, both the producer and brokers suddenly had to deal with many more, smaller batches. That means more frequent network calls, more compression operations, and generally more CPU churn.
With linger.ms=20, batching allowed Kafka to work smarter — fewer system calls, fewer packets, fewer yet better compressions per second.
At linger.ms=0, the producer becomes a bit of a machine gun, firing messages as soon as they arrive.
We could counter some of the consumer-side impact with settings like fetch.min.bytes, but let's leave that deep dive for another time. ⏳
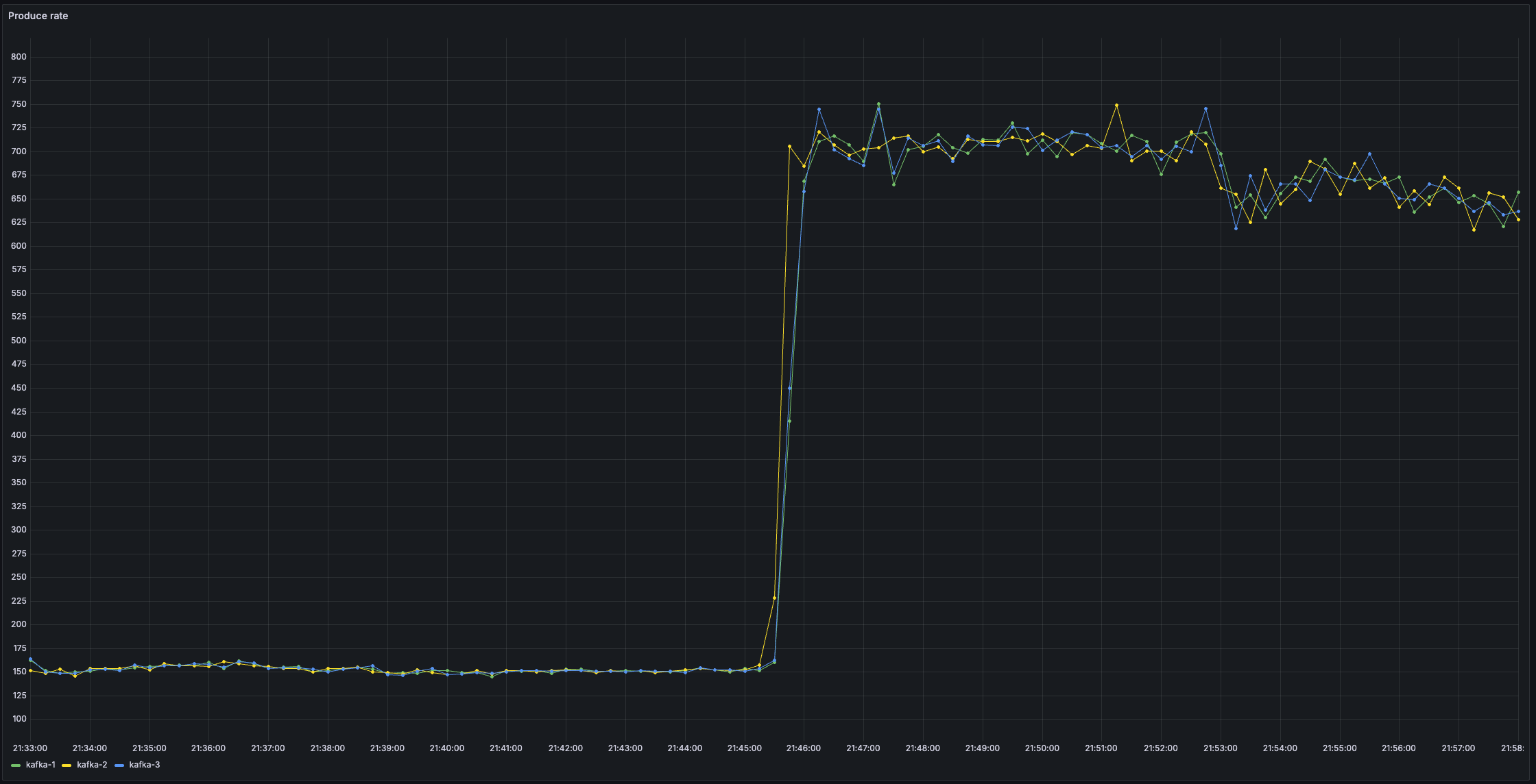
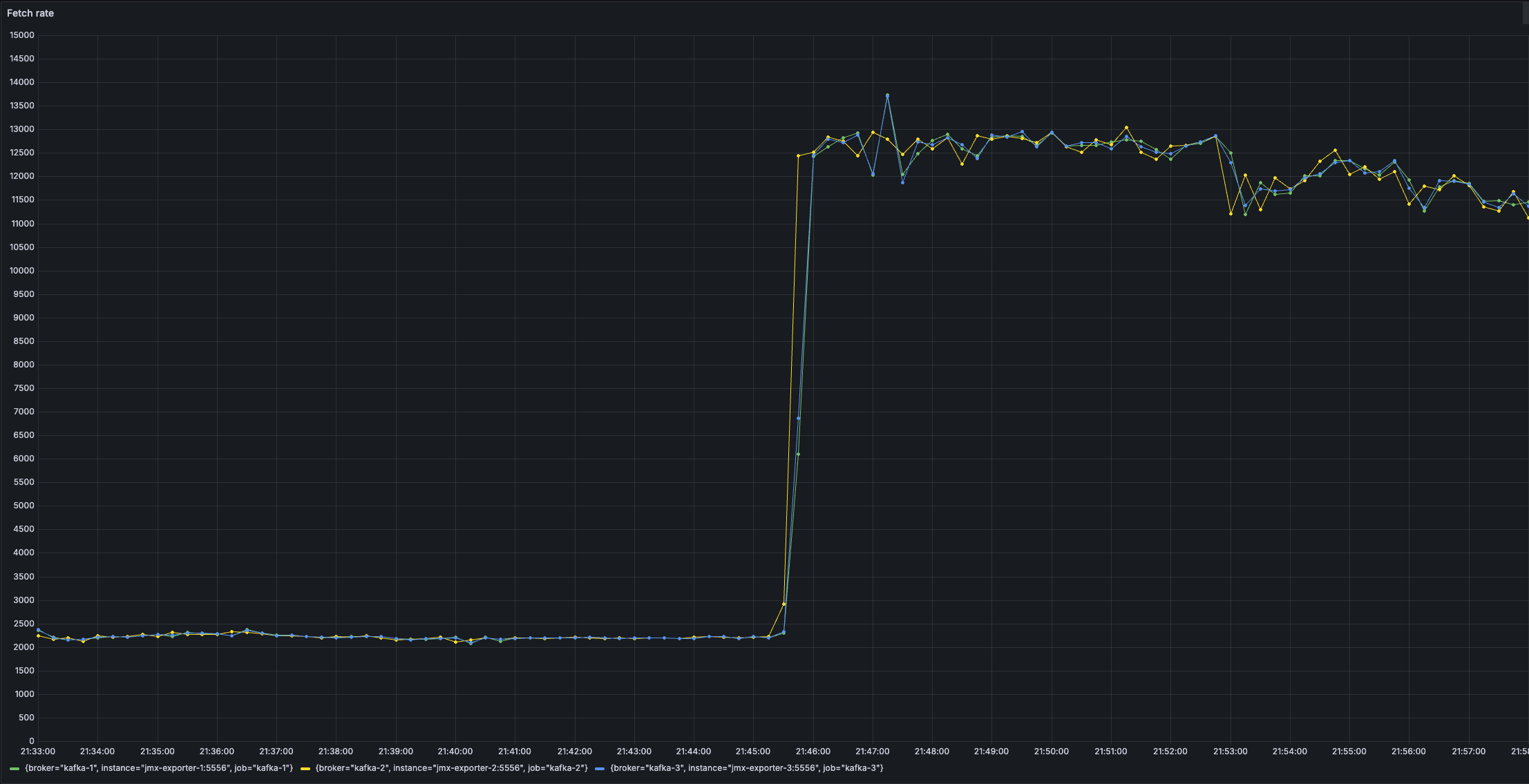
3️⃣ Produce/Fetch Count

Higer resolution picture

Higer resolution picture
The produce rate going up is the direct consequence of reducing linger.ms. Instead of batching to amortise the overhead, almost every event is a produce request. This is why CPU churn is so much higher.
On the other side, the fetch rate also rises. Given that the consumer by default waits until there's one byte ready (the Kafka broker returns data as soon as there is an event to be returned) and given that something lands all the time instead of once every 20ms, the consumer now has a lot more work as well.
fetch.min.bytes and fetch.max.wait.ms can be real lifesavers here. (Teasing the sequel once again 😉)
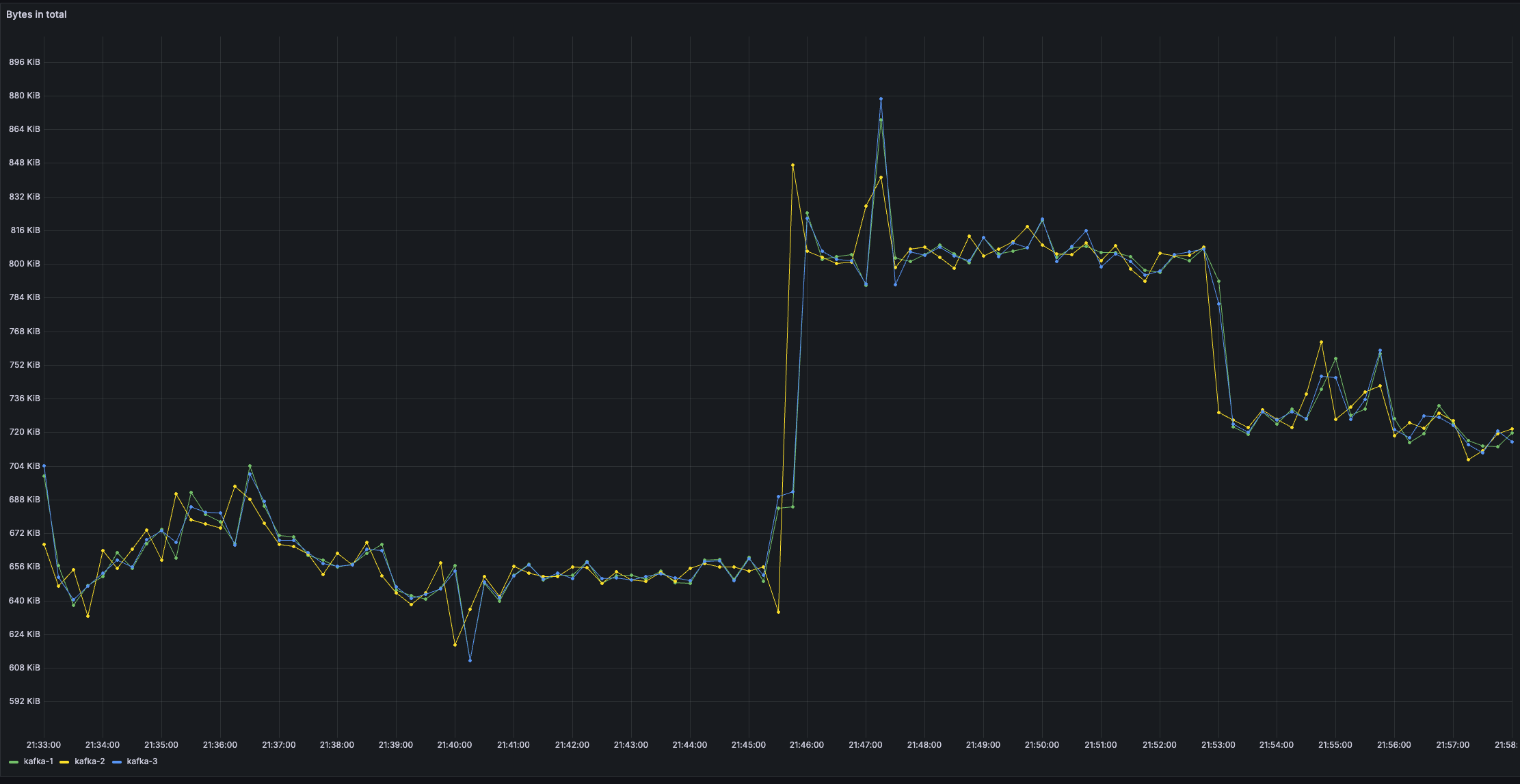
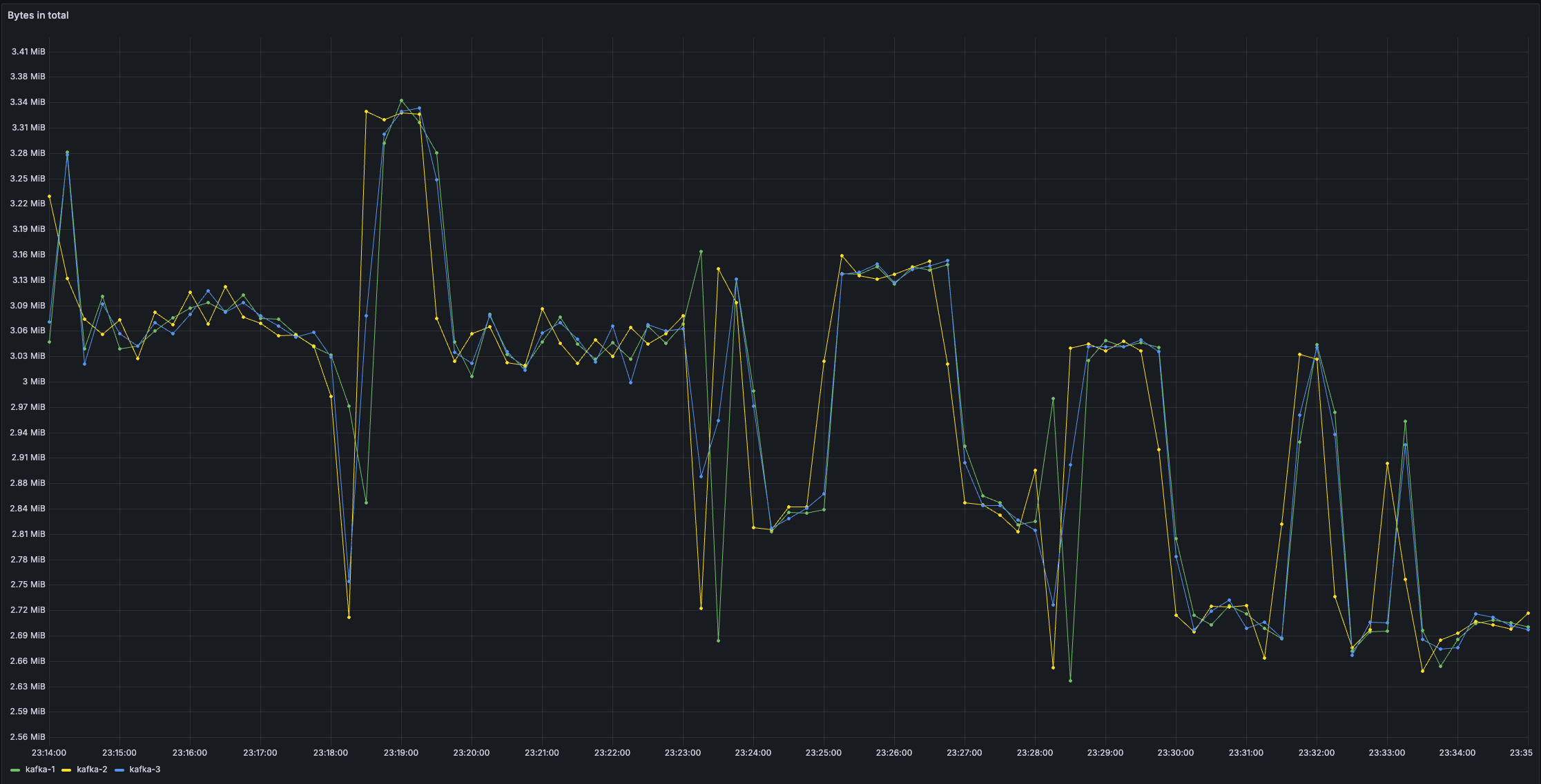
4️⃣ Bytes In Total

(Grand finale for the title metaphor 🎺🎺)
You can see an increase in bytes in across brokers after raising linger.ms.
Bigger batches mean better compression efficiency, but to have nice batches, you have to wait a little bit.
Compression algorithms work better with larger data blocks. Since data is stored and served as it arrives (check out Kafka zero copy), increasing linger.ms can reduce your storage and networking requirements. Pretty neat!
🧩 Summary
| Aspect | Lower linger.ms
|
Higher linger.ms
|
|---|---|---|
| Latency | ✅ Lower | 🚫 Higher |
| Broker CPU Load | 🚫 Higher | ✅ Lower |
| Client CPU Load | 🚫 Higher | ✅ Lower |
| Compression Ratio | 🚫 Worse | ✅ Better |
| Network Throughput | 🚫 Larger | ✅ Smaller |
🔥 Turning Up the Heat
So far, we've been working with a relatively modest message rate. But what happens when we really stress the system?
I ramped up the message volume 5x and ran a progressive test: starting with linger.ms=0, then after ~5 minutes switching to linger.ms=5, another 5 minutes at linger.ms=10, and finally 5 minutes at linger.ms=20.

Higer resolution picture

Higer resolution picture
Under high load, we can observe the following CPU gains:
-
Producer CPU drops by ~25% as you move from
linger.ms=0tolinger.ms=20 - Broker CPU drops by ~40% across the same range
Given that we're pushing 5x the messages, it seems that cpu usage is a function of the number of produceRequests more than the number of messages itself.
But here's the really interesting finding: end-to-end latency doesn't improve with lower linger.ms values under high load. In fact, it gets worse.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
When linger.ms=0, the e2e latency is actually higher than when linger.ms=5 or linger.ms=10. It's as bad or even worse than linger.ms=20. Why? Because all those network calls, compression operations, and context switches create so much overhead that the system itself becomes the bottleneck. You're not getting faster responses — you're just thrashing the CPU while simultaneously degrading throughput.
This is a crucial insight: at scale, lower linger.ms doesn't mean lower latency. The overhead of frequent small batches actually increases latency perception through system congestion, while also burning CPU cycles that could be spent on actual message processing.
For completeness, check out how compression becomes better, resulting in more compact data.

Higer resolution picture
{kind=link}
🚀 Key Takeaways
-
linger.msis a powerful lever for balancing throughput vs latency. - Setting it too low wastes CPU and bandwidth on small batches.
- Setting it too high hurts responsiveness — especially for latency-sensitive workloads.
- Tune it alongside
batch.sizefor your message volume and rate. -
Check your setup. The old default (before Kafka clients 4.0) was
linger.ms=0; the new default is 5ms. This switch alone can already have a nice impact on your Kafka bill. - If you have high load with lots of messages, adding some linger.ms might lower your e2e latency.
In other words — good things take time 😉
This content originally appeared on DEV Community and was authored by Ivan Juren
Ivan Juren | Sciencx (2025-10-29T08:53:49+00:00) Good Things (Compression) Take Time!. Retrieved from https://www.scien.cx/2025/10/29/good-things-compression-take-time/
Please log in to upload a file.
There are no updates yet.
Click the Upload button above to add an update.