
This content originally appeared on Level Up Coding - Medium and was authored by Gregory Pabian
In a distributed system, microservices exchange information between one another, using predefined communication protocols. Some disruptions in data serialization might occur when software developers alter different microservices independently. In this article, I will revisit the most relevant practices for versioning serializers and spreading their changes throughout a system.

Communication Protocols
The OSI model establishes 7 abstraction layers for communication over the Internet. Microservices usually exchange information using the last, seventh layer, called the application layer, leveraging either preexisting protocols like HTTP or custom-made ones. I find it significant to note that the HTTP/2 protocol relies on the TCP protocol (the transport layer) which in turn relies on the IP protocol (the Internet layer) — this means that sharing information between two machines involves more work than meets the eye. I will not describe the fundamental differences between text and binary protocols here, but I want to stress that HTTP belongs to the family of the former, compared to both the TCP and the IP protocols, which belong to the family of the latter.
From this moment on I shall discuss serialization within the bounds of the HTTP protocol, mostly because of its popularity and applicability in distributed systems. Using the aforementioned protocol, a developer can transfer an information of a reasonable size in:
- the request line (including the query parameters),
- the headers of a request or a response (the protocol allows for custom ones),
- the message body of a the request or a response.
There must exist precise rules of understanding information embodied in these components for any meaningful communication to occur.
If a service can encode a piece of information to satisfy the requirements of the URI encoding, it may transfer the data using the request line. The same happens for custom headers, albeit with different restriction in place. The Content-Type header defines the applicable format of a message body; XML, JSON and YAML qualify as the most popular formats for sharing information between microservices.
Even though a microservice might understand that a message body contains a JSON structure, it needs to know how to extract proper information. It requires a component that knows which fields to look for in the message, and their expected value types. In most systems I know of, developers call such a component either a deserializer or a decoder.
Serialization and Deserialization
I understand serialization as the process that transforms an environment-dependent in-memory object into its transferable representation over a certain medium (e.g., the Internet). The reverse operation, called deserialization, may recreate the initial object in a different environment, with a different programming language, different string encoding or a different CPU architecture. As serialization and deserialization work in tandem, I believe that no distributed system should treat the former with higher relevance than the latter; if either fails, the system in question cannot reliably work.
Microservices use special components called serializers and deserializers to perform the aforementioned operations. Any (de)serializer exists as part of a microservice that uses it, and thus, it heavily depends on the type system of the used programming language. In theory, one could model representations of a certain entity using a description language and produce dedicated (de)serializers for both the sender and the receiver in their respective programming languages; however, this solution might require bindings that do not exist yet for some stacks.
If the sender and the receiver utilize the same programming language, their developers might produce serializers and deserializers once and share the resulting code, using e.g., a library, git submodule or git subtree. Some programming languages, namely Java, allow for a platform-dependent serialization of an instance, including the version of its class. I would advise the reader to read about native serialization to gain outlook on experiences of other developers with the discussed problem.
Deserialization of an object representation can work in the strict way, which means that the deserializer deals only with the explicit properties, either ignoring outstanding ones or throwing an error. I usually incline towards the strict approach, as I consider receiving additional properties a red flag. Additionally, I believe that all deserialization failures require an error-class log entry, especially in closed proprietary systems.
Versioning
Serializers and deserializers need versioning when the system designers expect these components to change over time. The decision to apply versioning to all components or just a subset of them belongs, again, to the architects. Regardless of particular choices, the developers must devise a transition plan to move the system in question from one version of a (de)serializer to the other.
The most basic model of a contemporary Internet product consists of 3 elements: the physical user, the frontend application and the backend server. Users use the frontend to give commands to the backend, leveraging the communication protocol that connects the aforementioned system components. I illustrated an example of the concept in the following diagram:
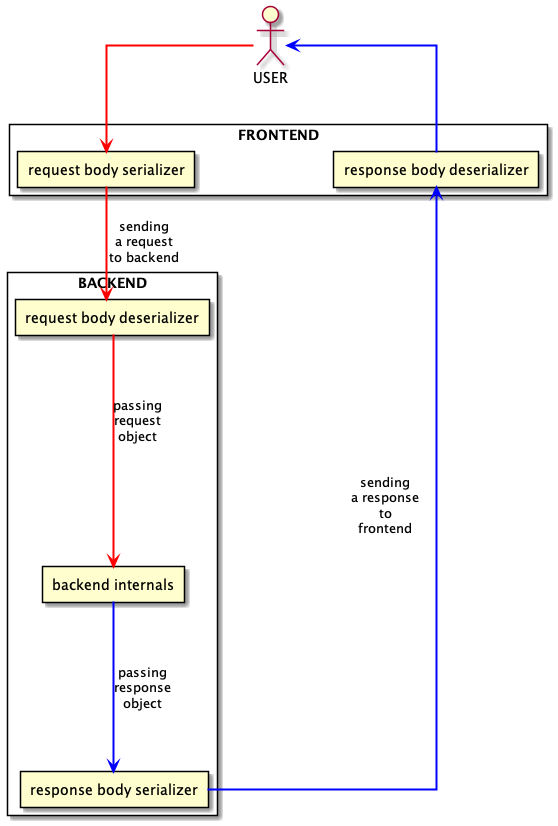
I find it crucial to point out that there exist two classes of serializer/deserializer pairs: one for the request body, and the other for the response body. This means that if a software developer changes both pairs, the system will need to deal with 4 combinations:
- the old request body object with the old response body object (the old state),
- the old request body object with the new response body object (the forward transition state),
- the new request body object with the old response body object (the backward transition state),
- the new request body object with the new response body object (the new state).
If possible, the system architects should plan the transition in a way that no information exchange happens in a transition state, lest communication becomes unreliable — starting by defining versions for either the (de)serializers, or the API endpoints in question.
Manual versioning
A system might use manual versioning of (de)serializers when:
- a serializer/deserializer pair works over microservices of different technical stacks,
- a shared serializer (if it exists) does not support the concept of hashing,
- system architects want to easily distinguish between different versions of a serializer.
Developers can express the version as either an integer, or a string compatible with semantic versioning. Transporting the version happens over a non-cacheable HTTP header (e.g. X-Request-Body-Serializer-Version) or as a property on the root object in the message body (e.g. serializerVersion).
Hash-based versioning
A developer might use hash-based versioning when (de)serializers can create hashes of themselves. Creating a proper hashing function constitutes quite a challenge on its own, therefore I designed one that works with io-ts (de)serializers called codecs, shown in the example underneath:
The system components can specify the version using, again, a non-cacheable HTTP header (e.g. X-Request-Body-Serializer-Hash) or as a property on the root object of the message body (e.g. serializerHash).
Implementation & Deployment
If the both aforementioned serializer/deserializer pairs changed, the following should happen:
- the altered backend supports both the old and the new pairs (or rather, the old and the new states),
- the altered frontend recognizes only the new pair (the new state).
This ensures that, after the new version of the backend comes online, the old version of the frontend application can still use the old state. After the backend deployment, developers can release the new version of the frontend, which will work with the new state.
The backend has to choose the proper serializer based on either the incoming HTTP headers, or the version property of the root object in the request message body; the same applies to the deserializer used for the response message body. In more advanced systems, the load balancer of a particular backend might use the provided HTTP headers to point the caller to a backend instance with a specific serializer version. In certain scenarios, the old serializer might build an object coming from the new serializer using simple transformations, by leveraging e.g. default values for some properties.
Summary
Even though I showed two methods of versioning serializers, there exist more of them, especially if system architects allow for creating versioned endpoints. I believe that ensuring no downtime forms the most important aspect of any transition in a distributed system, unless specified otherwise. I encourage experienced readers to write a comment if you have lately stumbled upon a different solution to the aforementioned problem.
Versioning Serializers was originally published in Level Up Coding on Medium, where people are continuing the conversation by highlighting and responding to this story.
This content originally appeared on Level Up Coding - Medium and was authored by Gregory Pabian
Gregory Pabian | Sciencx (2021-03-16T13:28:55+00:00) Versioning Serializers. Retrieved from https://www.scien.cx/2021/03/16/versioning-serializers/
Please log in to upload a file.
There are no updates yet.
Click the Upload button above to add an update.