
This content originally appeared on Level Up Coding - Medium and was authored by Bryan Galindo

Table of Contents
- Introduction
- ELI5
- Explained: Bloom filter
- Code: Bloom filter vs Redis
- Recap
- Quiz
A Bloom filter is a probabilistic data structure that is used to test whether an element is a member of a set. In other words, a Bloom filter can let you know, with a very high chance of being correct, if something exists in a group of things.
Me: Bloom Filter, is there a red piece of candy in this bag of candies?
Bloom Filter: Maybe.
Why should you care about this data structure? Bloom filters can eliminate up to 85% of disk reads [1]. In testing whether an element exists, clients query Bloom filters first before checking a database, thus potentially preventing a disk read (since databases persist to disk).
Okay, but who even uses Bloom filters? PostgreSQL, Google Chrome, Bing, Google Cloud Bigtable, and the list goes on.
But before we dig into the formal definition, I want to fulfill the promise I made in the title by explaining Bloom filters through a simple, non-technical analogy.

My girlfriend, Stacey, is my Bloom filter when it comes to the contents of our fridge. When I ask her if we have something in the fridge, she responds with any of these statements:
- a) yes, it’s in the fridge.
- b) yes, I think it’s in the fridge.
- c) no, 100% it’s not in the fridge
Stacey is usually right when she says it’s in the fridge, and she’s never been wrong with response (c). As we all know, it is expensive to walk to the fridge from anywhere (e.g., couch, bed, upstairs). So, I’m forever grateful to her because she has significantly reduced my trips to the fridge.
How do Bloom Filters work?

So you are considering implementing a Bloom filter in your tech stack. How does it work? Let’s define the components of a Bloom filter and how they work together.
Algorithm Description
An empty Bloom filter is a bit array of m bits, all set to 0.

There must also be k different hash functions defined, each of which maps or hashes some set element to one of the m array indexes.

To add an element, feed the element to each of the k hash functions to get k array indexes. Set the bits at these indexes to 1.

To query for an element (i.e., test whether it is in the set), feed the element to each of the k hash functions to get k array indexes. If any of the bits at these indexes is 0, the element is 100% not in the set; if it were, then all the bits would have been set to 1 when it was inserted. Thus, a Bloom filter is really effective at determining if an element is not a member of a set.
On the other hand, if all of the bits at these indexes are 1, then either the element is in the set, or the bits were set to 1 during the insertion of other elements, resulting in a false positive.
Even though Bloom filters allow false positives, in return, a Bloom filter offers very compact storage: less than 10 bits per element are required for a 1% false positive probability, independent of the size or number of elements in the set [2].
Bloom Filter vs Redis with Code

If you’re still not convinced, let’s run through an actual implementation by pitting a Bloom filter against a Redis database with Python.
Bloom Filter Test Case
I generated 1M new + unique IDs using the Python built-in library uuid and a list comprehension.
unique_ids = [uuid.uuid4() for i in range(0, 1_000_000)]
Then, I created a new Bloom filter instance using the pybloomfiltermmap3 library. By using this library, we do not have to worry about implementing the k hash functions.
bloom_filter = BloomFilter(capacity=1_000_000, error_rate=0.01, filename='filter.bloom')
Next, I iterated through the 1M unique IDs, checking if the ID exists in the Bloom filter, and, shortly after, adding the ID to the Bloom filter. If an ID exists (which it shouldn’t), I took note of the false positive.
def get_bloom_filter_stats():
start = time.time()
false_positives = 0
for i, element in enumerate(unique_ids):
if element in bloom_filter:
print(f'false positive for id={element} at index={i}')
false_positives += 1
# hashes element, and stores in bit array
bloom_filter.add(element)
elapsed_time = time.time() - start
return {'execution_time': elapsed_time, 'false_positives': false_positives}
Here are some stats for the Bloom filter test. Take note that the actual error rate is less than 1% and the blazing fast execution time < 500ms.
## Bloom Statistics ##
emulated_requests: 1,000,000
false_positives: 1,838
expected_error_rate: 1.00%
actual_error_rate: 0.1838%
bloom filter file_size: 1.14MB
Bloom execution_time: 482ms
Redis Test Case
Now, let’s see how Redis performs with the same 1M key lookups. I started by creating a Redis instance of my local Redis server.
redis_client = StrictRedis().from_url('redis://localhost:6379')Then, I iterated through the same 1M unique IDs, taking note of the elapsed time.
def get_redis_execution_time():
start = time.time()
for element in unique_ids:
redis_client.get(str(element))
elapsed_time = time.time() - start
return elapsed_time
Redis took 31 seconds (!) to iterate through the entire list of IDs, compared to a Bloom filters execution time of 482 milliseconds. I did not test a SQL database since Redis is generally faster (in-memory vs disk). Which means for key existence checks, a Bloom filter is at least 63x faster than a SQL database.
Of course, there were some trade-offs: the false positives and the Bloom filter file size (~1MB/1M records). However, with an error rate lower than 1% and such a small footprint, it is definitely worth it.
If you’re interested in seeing the entire code snippet, it can be found here: https://github.com/bryangalindo/bloomfilter-example/blob/main/main.py.
Recap
Thanks for reading! Here are some of the key points from this article.
- An empty Bloom filter is a bit array of m bits, all set to 0.
- To confirm if an element does not exist, an element’s hashed set needs at least one value that maps to a 0-bit index.
- If an element’s hashed set contains values that all map to 1-bit indexes, then either the element is in the set, or the bits were set to 1 during the insertion of other elements.
- Bloom filters allow false positives, but the probability of a false positive can be less than 1%.
A Very Short Quiz

Question 1
Which elements (foo, bar, baz) are not in the Bloom filter?
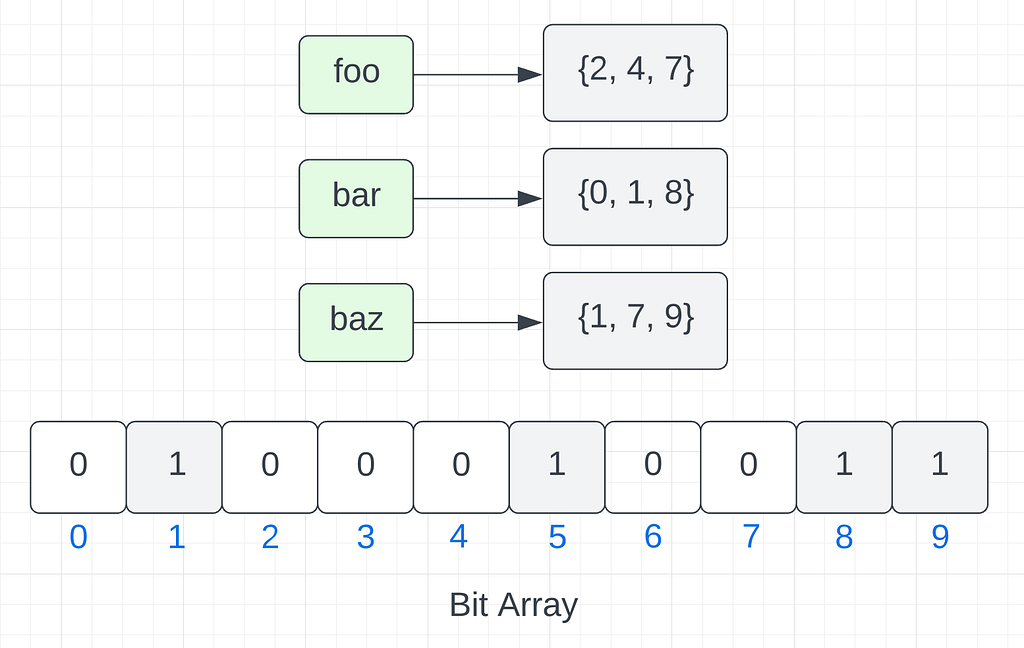
Question 2
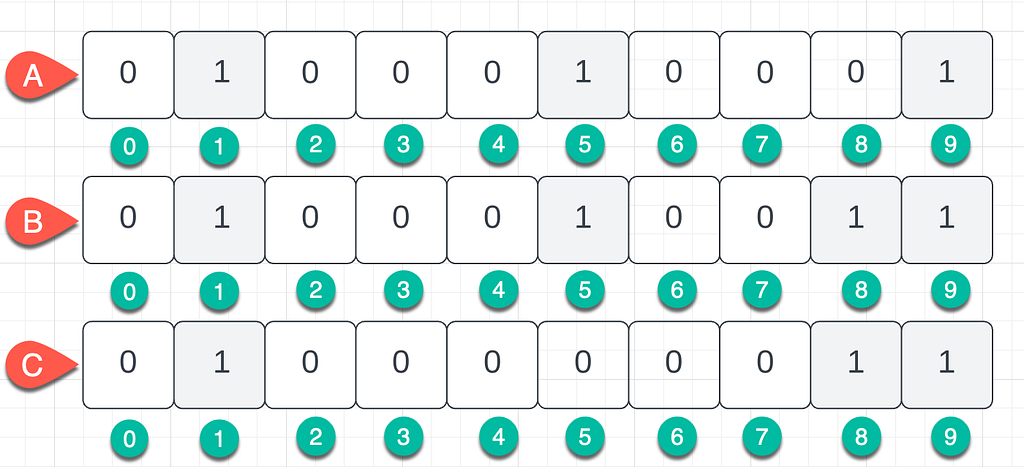
A new element, qux, appears with a hashed set of {1, 5, 9}.
If we were to check whether element qux exists in the set, which Bloom filter (A, B, C) would return a false positive?
ELI5: What the F*** is a Bloom Filter? was originally published in Level Up Coding on Medium, where people are continuing the conversation by highlighting and responding to this story.
This content originally appeared on Level Up Coding - Medium and was authored by Bryan Galindo
Bryan Galindo | Sciencx (2022-03-27T15:28:38+00:00) ELI5: What the F*** is a Bloom Filter?. Retrieved from https://www.scien.cx/2022/03/27/eli5-what-the-f-is-a-bloom-filter/
Please log in to upload a file.
There are no updates yet.
Click the Upload button above to add an update.