
This content originally appeared on Level Up Coding - Medium and was authored by Erich Hohenstein
How to get a Data Science Job…using Data Science-Part I

Looking for a job is a full time job. You have to dedicate countless hours searching and reading job posting websites, writing cover letters, filling your CV over and over (even after you already uploaded it) only to later find out you weren’t a good match for the position.

But wait! we are Data Scientists, there has to be a better way to find our dream job, without having to read every job post out there. What if we could build a job postings database and then find the best match for our qualifications. Like seniority, programming languages, frameworks, etc. And then rate each of the jobs so we can give priority to the ones we have a better match with. That would be cool wouldn’t it?
Today we will be using this real life problem to introduce some web scraping techniques as well as learning how we can apply Data Science way of thinking to tackle problems…So we will be using Data Science to get a Data Science job!
The plan
Before jumping into coding, let’s solve the problem on paper and break it down into steps.
- Find the data source — There are many job posting websites, but by far the most popular is LinkedIn, so this will be our data source.
- Collect data — We will write a Python Script on Jupyter to access LinkedIn, search jobs with the keywords “data science” and then crawl page while we extract the information from each post.
- Clean the collected data — This is a very important part for any ETL. Put the data in the best possible shape to make it understandable and searchable. Since we will be working with unstructured data, that is text written by humans, we will have to clean the text and remove unnecessary words for the scoring part.
- Create a scoring function — What we need is to create a function to score how good is the match between us and each job post. Put it simply, the function will take our CV and a job post and the output will be a number between 0 and 1: f(CV, JobPost) = score
The code
Login to LinkedIn
The first task of the day is installing the Selenium library. We will use this library to open and control a Google Chrome window with Python code. We will also need to download a chromedriver from:
https://chromedriver.chromium.org/downloads
Make sure that the chromedriver version matches the version of the Google Chrome you have installed on your computer. You can check the version opening Google Chrome, clicking on the 3 dots on the top right, then go to Help and About Chrome.
Once we have Selenium installed and the chromedriver in our project folder we can start coding. We will import the libraries: Pandas, Selenium, and time. The later is a pre-installed library that we’ll use to add wait times to let the browser fully load a page before the next step. This is an important consideration when doing Web Scraping. Then we will create a browser instance and use that instance to go into the LinkedIn login page.
#Create browser instance by giving the address to chrome webdriver
browser = webdriver.Chrome('./chromedriver')
# Navigate to LinkedIn Login page
browser.get('https://www.linkedin.com/login/es?fromSignIn=true&trk=guest_homepage-basic_nav-header-signin')
You will see a Google Chrome window open and automatically navigate into LinkedIn.

We will add now some lines of code to automatically insert our LinkedIn user and password. To insert the username we use the following line:
browser.find_element(By.ID,'username').send_keys('erichhohenstein@gmail.com')
Let’s break up this line of code. First we have a browser instance which we named “browser”, then we have the method “find_element” to which we pass how are we going to find the browser element, in this case “By.id” and then we pass the id “username” . The way we work with Selenium is by finding elements on the browser screen and then interacting with them by sending strings, clicks, and other commands. If you type “By.” and then hit tab, you can see all the possible ways you can find elements. In this case we passed the “username” id. I found this id by using Chrome DevTools: Right click on the browser → Inspect → Select and element to inspect (This lets you click an element on the page and then shows the code behind the element)
We do the same to send the password and then we use the following code to click the Login button.
browser.find_element(By.CLASS_NAME,’btn__primary — large’).click()
Notice in this case I found the element using the class name and used the .click() method to click the button…and we are in!

In order to keep our code clean, we will be using functions for each specific task. So the final code for the login function is the following:
def loginLinkedIn(browser,usr,psw):
# Go to LinkedIn Login page
browser.get('https://www.linkedin.com/login/es?fromSignIn=true&trk=guest_homepage-basic_nav-header-signin')
time.sleep(4)
browser.find_element(By.ID,'username').send_keys(usr)
time.sleep(1)
browser.find_element(By.ID,'password').send_keys(psw)
time.sleep(1)
browser.find_element(By.CLASS_NAME,'btn__primary--large').click()
return browser
Notice I added time.sleep(1) so the program waits for 1 second before each step. This practice is done to avoid errors of executing tasks too fast like clicking a button that hasn’t been rendered yet.
Web Crawling
The next step is to make the job search. For this, we will first do the job search manually to get the URL and understand the parts of if so we can use it to crawl LinkedIn.
I searched for job remote position, worldwide for data science and got the following URL:
https://www.linkedin.com/jobs/search/?f_WT=2&geoId=92000000&keywords=data science&location=Worldwide&sortBy=R and when I go to the next page 2, the link changes to https://www.linkedin.com/jobs/search/?f_WT=2&geoId=92000000&keywords=datascience&location=Worldwide&sortBy=R&start=25
Analyzing the URL we see there are 3 important things are happening here:
- The number after “f_WT=”, searches for on-site, remote, or hybrid. Where 2 is remote.
- After “keywords=” goes what we are searching for, replacing spaces with “%20”
- After “start=” goes the number of job posts. Each page starts at multiple of 25.
With this knowledge we can now use some type of loop to go through all the result pages. Then our code to crawl the search results will look like this.
#PARAMETERS
jobtype = '2' #Remote
keyword = 'data%20science' # "%20" = space
page = '0' #start at 0. Goes in multiples of 25
#URL
URL = 'https://www.linkedin.com/jobs/search/?f_WT='+jobtype+'&geoId=92000000&keywords='+keyword+'&location=Worldwide&sortBy=R&start='+page
Web Scraping LinkedIn Job posts
The next thing we need to solve is what to do with each post. When we click on a job post, the whole description is shown. So we need to write a function so each time our program clicks on a job post, the information within is extracted. The information we want to get is: jobTitle, company, company profile link, location, job link, poster name, poster profile link, and job description. We will now write a function that will receive a Selenium browser instance and will return this information. The code is the following:
def getLinkedinJobs(browser,keyword,jobType,maxPageNumSearch):
actions = ActionChains(browser)
jobtype = str(jobType) #2 = Remote
keyword = keyword.replace(' ','%20') # %20 = space
jobData = [['title','company','companyLink','location','jobLink','posterName','posterProfileLink','jobDescription']]
for p in range(maxPageNumSearch):
page = str(p*25)
#print(page)
browser.get('https://www.linkedin.com/jobs/search/?f_WT='+jobtype+'&geoId=92000000&keywords='+keyword+'&location=Worldwide&sortBy=R&start='+page)
time.sleep(3)
#Search for all job postings shown
jobs = browser.find_elements(By.CLASS_NAME,'jobs-search-results__list-item')
i=0
for j in jobs:
#print(i)
i+=1
time.sleep(2)
actions.move_to_element(j).perform()
j.find_element(By.TAG_NAME,'img').click() #Click on the image so it doesnt misclick a URL
jobData.append(getJobInfo(browser))
df = pd.DataFrame(jobData[1:],columns=jobData[0])
#Drop any duplicate
df.drop_duplicates(subset = ['jobLink'],inplace=True)
return df
There are a lot of things happening here, so let’s break it down. Our function takes the following inputs: A browser instance, the keyword to be searched (Ex. “Software Developer”), a jobType (Ex: 2 for remote job), and maxPageNumSearch. When we make a search on LinkedIn the results are divided in pages, this number represents up to which page we want to scrape the results. This function will iterate through all the result pages (up to maxPageNumSearch) and for each page will click on each post to display the job description on the screen. After clicking a job it calls the function getJobInfo(browser) which extracts all the information we want and returns it as a list. Finally all the lists are put together into a Pandas data frame that is returned. The code for getJobInfo() is the following:
def getJobInfo(browser):
title = ''
company = ''
companyLink = ''
location = ''
jobLink = ''
posterName = ''
posterProfileLink = ''
jobDescription = ''
try:
title = browser.find_element(By.CLASS_NAME,'jobs-unified-top-card__content--two-pane').text.split('\n')[0]
except:
pass
try:
company = browser.find_element(By.CLASS_NAME,'jobs-unified-top-card__company-name').text
except:
pass
try:
companyLink = browser.find_element(By.CLASS_NAME,'jobs-unified-top-card__company-name').find_element(By.TAG_NAME,'a').get_attribute('href')
except:
pass
try:
location = browser.find_element(By.CLASS_NAME,'jobs-unified-top-card__bullet').text
except:
pass
try:
jobLink = browser.find_element(By.CLASS_NAME,'jobs-unified-top-card__content--two-pane').find_element(By.TAG_NAME,'a').get_attribute('href')
except:
pass
try:
posterName = browser.find_element(By.CLASS_NAME,'jobs-poster__name').text
except:
pass
try:
posterProfileLink = browser.find_element(By.CLASS_NAME,'jobs-poster__name-link').get_attribute('href')
except:
pass
try:
jobDescription = browser.find_element(By.CLASS_NAME,'jobs-box__html-content').find_element(By.TAG_NAME,'span').text.replace('\n',' ')
except:
pass
return [title,company,companyLink,location,jobLink,posterName,posterProfileLink,jobDescription]
Although it looks complex, this function is following the same principles we discussed at the beginning. Find an element name using Chrome Dev Tools, then use selenium “find_element” to find the element by using the ID, or Class name, or any other method that works for us. Notice how I enclosed each find element instance in a try-pass. This is a good practice when there are elements that don’t always show. For instance, sometimes the “location” element isn’t included in the job post so we can skip securely with the try-pass.
1000 Web Scraped Jobs from LinkedIn!...Now what?
I run the code to search for remote Data Science jobs using our function:
getLinkedinJobs(browser,'data science','2',40)
I got back a data frame with 1000 job postings and all their data.
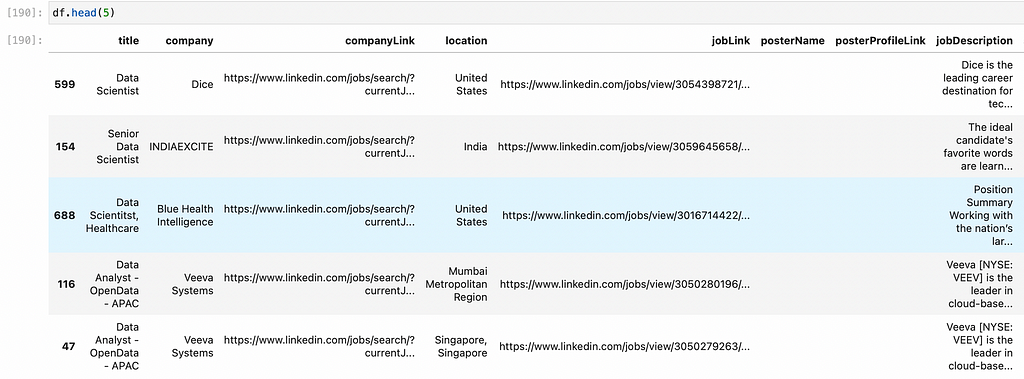
That’s a lot of job postings to read! What we need to do now is to find a way to process all these jobs posts so we can find the jobs that are a better match for us and prioritize our application process. Which is exactly what we’ll do in the next blogpost. We will apply Data Science to compare each job description with our CV. We will learn how to read PDFs with Python and then how to do text comparison to score each job post against our Resume and find the best Jobs for us.
Code: https://github.com/erichho/LinkedIn-Job-Webscraper
Applying Data Science and Web Scraping to find a Job on LinkedIn-Part I was originally published in Level Up Coding on Medium, where people are continuing the conversation by highlighting and responding to this story.
This content originally appeared on Level Up Coding - Medium and was authored by Erich Hohenstein
Erich Hohenstein | Sciencx (2022-05-13T10:45:45+00:00) Applying Data Science and Web Scraping to find a Job on LinkedIn-Part I. Retrieved from https://www.scien.cx/2022/05/13/applying-data-science-and-web-scraping-to-find-a-job-on-linkedin-part-i/
Please log in to upload a file.
There are no updates yet.
Click the Upload button above to add an update.