
This content originally appeared on Level Up Coding - Medium and was authored by Darío Rodríguez

This is the second part of a series of articles where I’m covering the basics of scaling backend applications.
In the first article, we talked about some concepts and procedures to ensure that you are scaling when and how it is needed, you can read the full article here.
In this second part I want to focus on some advanced techniques to scale applications, why you need them and some examples of implementing based on real world problems, let’s go!
About scaling patterns
Usually when you are scaling your application you start by applying one technique and then another one depending on the problems you are facing. So basically your application starts to be more scalable because of the sum of improvements every pattern gives you.
There is no specific way to apply this patterns because each application is different, but if I should write down a guide to scale an application applying these patterns would be something like this:
- Ensure you checked the basics (database and code optimization)
- Scale vertically
- Scale horizontally
- Implementing a caching system
- Implement database sharding
I will apply these patterns in this particular order just because it solves the most common issues you are going to face as your application usage increases.
When you have some experience developing systems that support a huge load you will skip some patterns because they won’t help you so much. I will explain a little bit more in the next sections but first of all let’s get more information about the patterns themself.
About vertical and horizontal scaling
At this point I want to talk about the differences between vertical and horizontal scaling and when to use one or the other.
Vertical scaling is when you add more resources to the same application but using the same amount of servers. For example let’s say we have a website and we use one server to run it. If we want to scale vertically we will change the CPU for a faster one, we will add more RAM, we will change disk for a faster one, etc.
Horizontal scaling refers to the action to add more resources to run an application but increasing the number of servers. Using the previous example, if we want to scale horizontally our website we will add a second server instead of improving the existing one so we will get twice the power to run the application.
When you scale to add more resources you increase the costs of running your application, depending on the hardware requirements of your application scaling vertically adding powerful hardware could be as expensive as running another server to scale horizontally.
Both options have some pros and cons, and some use cases that make one of them the best option. For example, if you are running a stateless application without sessions, scaling horizontally is the best option, because in addition to gaining more power you will get high availability for your application. On the other hand if your application has a strong dependency on local resources inside the server, scaling vertically could be the fastest way to get more performance before doing a big refactor of your application to scale horizontally.
One important thing is that vertical and horizontal scaling patterns don’t belong to a particular technology, they apply to almost every application from web servers to databases. Usually each application has its own scaling capabilities built in.
About caching, sharding and high throughput databases
Now it’s time to introduce some scaling concepts related to databases and data usage in general.
When we say caching we are talking about compiling the information and storing it in a way that is faster to access and requires less resources. With this we can support more requests with low response times. This pattern is applied to improve database access as a first layer before reaching a slow database. We will see how it works in the following sections.
Sharding is a concept of data distribution and refers to the way we can distribute the information between different database instances in different servers. Usually when we scale databases horizontally we do it to read information but the typical architecture has only one primary server. It has a big problem if your application needs to write a lot of information and it’s where sharding comes to solve this problem. We will talk more about sharding in the following sections.
If I should define what is a high throughput database I will say that it’s a database that was implemented with horizontal scalability and sharding capabilities out of the box. It means that you just need to install and configure your database to handle millions of requests without touching a line of code.
A scaling pattern for every problem
As said, every pattern was thought to solve a particular problem or set of problems your application will face when increasing the number of requests to your system. We saw all the details about the patterns and it’s time to see how they can help us.
Vertical scaling allows you to handle a slight increase in your requests but won’t help you to reach hundreds of millions of them. It’s really useful in the early stages of your application but you will need to start scaling horizontally soon.
Horizontal scaling will help you handle millions of requests and should be applied to each part of your application. It means that you will need to scale horizontally your application servers, your database servers and so on.
Caching will help you to increase the number of requests your application can handle by avoiding overloading some parts of your systems like databases. Caching could be used to store the response of your application so basically you can skip even the process of the request itself but it’s really useful to reduce database queries. Sometimes you need a slow but reliable database engine to store the information and caching some information will help you to reduce response time and increase performance.
Sharding your data will allow you to handle both more read and write requests to your database or application. You can implement your own sharding algorithm, it’s easier than it seems, but I recommend using existings solutions like some database engines that have sharding support built in.
Using high throughput databases it’s really useful when the bottleneck of your application is the database. Usually it’s about using NoSQL databases like MongoDB, Redis, CouchDB, Cassandra, etc. these databases use a new approach to manage data and most of them implement horizontal scalability and sharding capabilities out of the box.
We have learned a lot of theory about scaling, its patterns and how they help us to improve our application performance. Now we will see how they work and how we can use them in our systems.
How to scale horizontally
Usually, you scale horizontally when some part of your application is overloaded. Let’s say your application server or web server is running out of resources (CPU, ram, etc) you can add more servers to deal with it.
The most common architecture to scale horizontally involves using a Load Balancer. A load balancer is an application that distributes requests, typically HTTP or TCP requests, across a pool of servers. Using a load balancer you can scale your application to the sky by just adding servers to the pool.
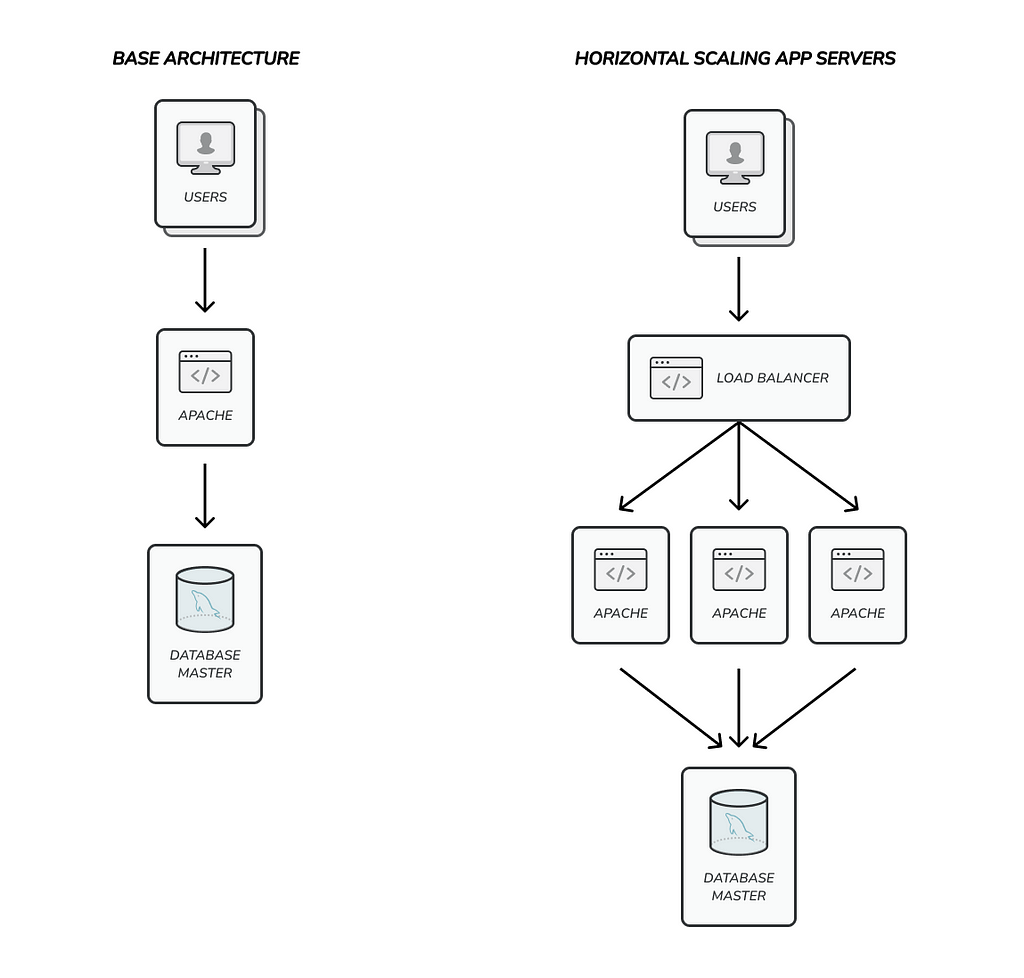
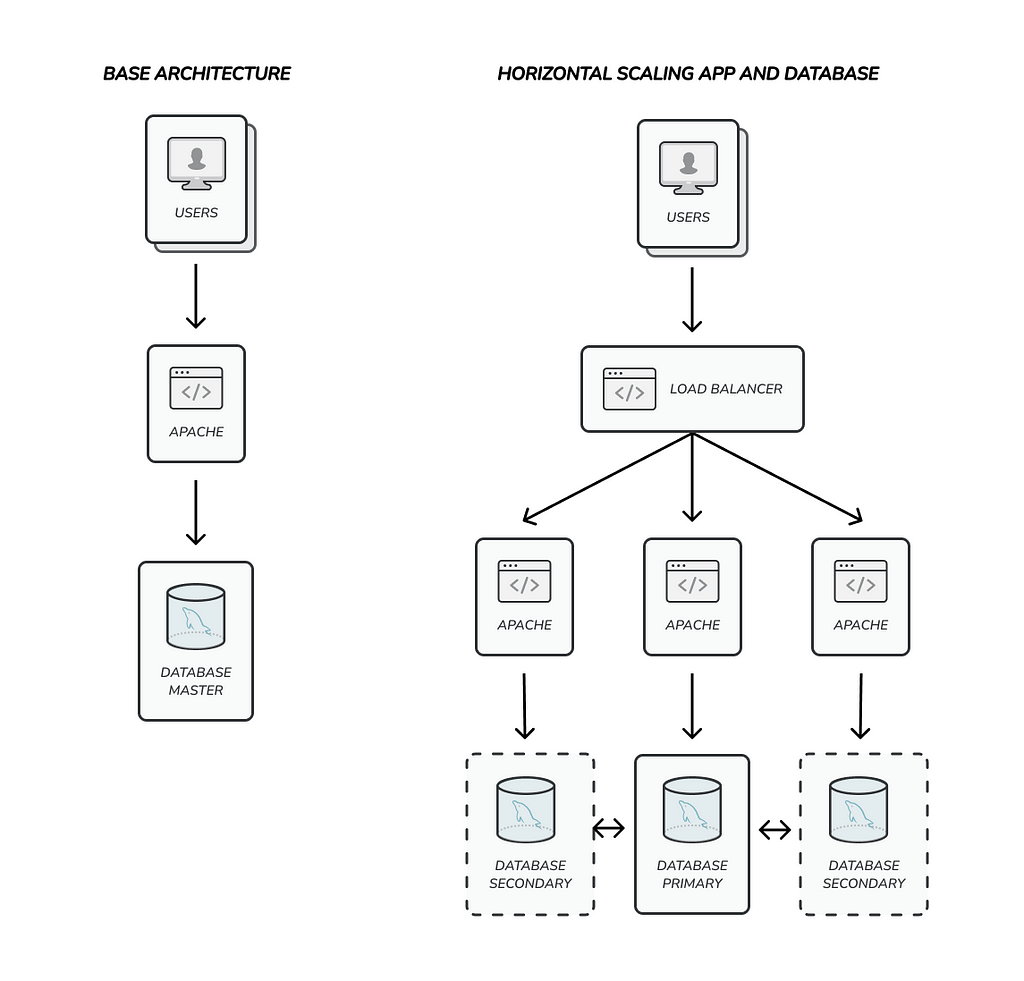
Some applications like databases supports horizontal scaling out of the box. The most common strategy available to do it is the primary-secondary replication. You can have one primary server and multiple secondary or replica servers. Ideally you will make a lot of read requests using secondary servers and use the primary just for write requests. The data would be replicated from primary to secondary automatically.
Scaling horizontally has many implications and sometimes could involve big refactorings and huge infrastructure changes. But despite all of that it’s the only way to add more resources when your application needs to handle more requests effectively.
How to implement a caching system
One of the basics scaling patterns is caching and it’s about using specific high performance databases to serve data.
When you implement a cache system you use a two steps process to fetch data. First you will try to use data inside a cache database because it’s faster, if data is not present in cache you will query your, typically, relational database to gather the information.
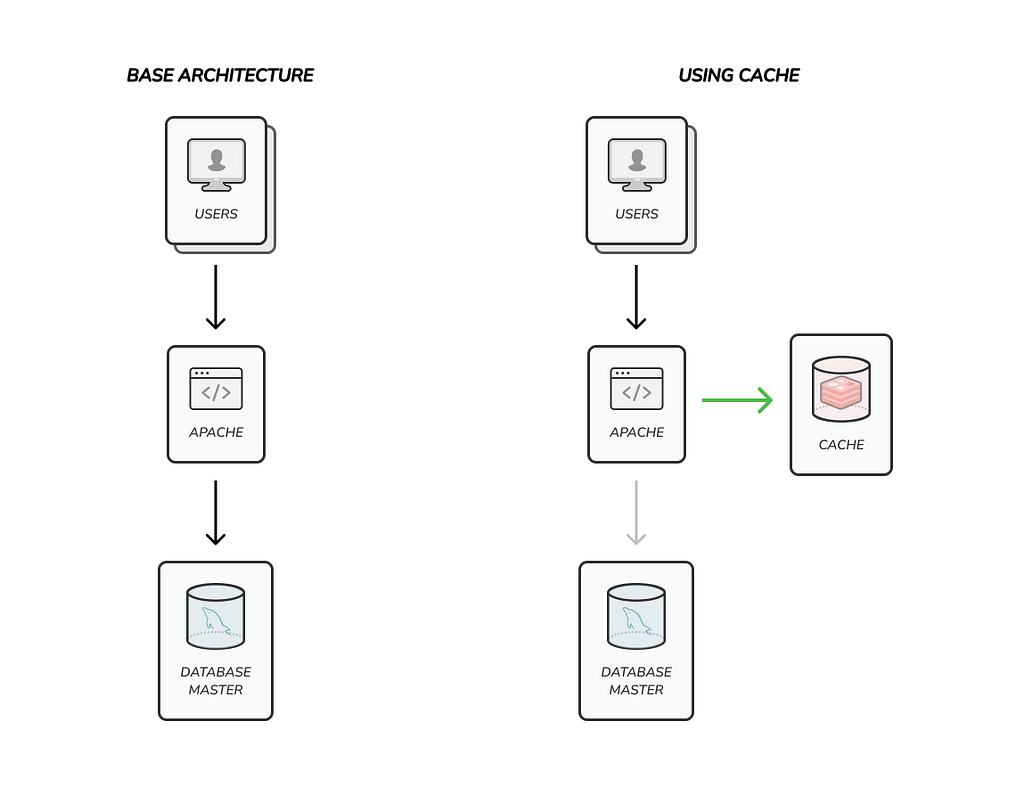
You can use several kinds of databases like in-memory databases, key-value databases or NoSQL databases, depending on your requirements some are more appropriate than others. For example, if your cache requires complex queries, maybe a NoSQL database it’s more flexible than a simple key-value, but if you need pure speed and performance key-value in memory databases are the best options.
Besides choosing database type, you need to think about what information you are going to store in cache and how. Knowing what information to store it’s really easy, you need to cache the information for two reasons: it’s widely used in your application or it’s really slow to fetch it from the database.
Choosing how to store the data could be a little more tricky, the most common way to do it is to store data using structures as close as you will need to use it later on in your code. For example, if you are caching a slow query from a relational database you will cache the result of this query.
Usually caches are filled in two ways: storing data on the fly or compiling information using background processes. If you cache data on the fly you are storing query results or business logic data treatments results into cache for following requests. If you use background processes to fill your cache you are compiling the information before it’s retrieved in your code. Both approaches are useful and can be used at the same time.
Another important thing is that you can implement as many caches as you need using different strategies so it’s up to you to get the most of this pattern to improve your application’s performance.
If you want more information you can check some technologies like: Redis, MongoDB, CouchDB, Cassandra, etc. to know more about high performance databases and caching.
Implementing database sharding
When talking about horizontal scaling we said that some database engines have built in horizontal scaling, but for read only queries. The most advanced database engines support horizontal scaling for write queries and they usually do it by implementing database sharding.
Database sharding literally splits your data into several groups of servers called shards. Every shard usually has at least three servers (one primary and two secondaries) to ensure availability and to support write and read for its portion of data. If you have two shards you can handle twice write requests, if you have four shards you can handle four times write requests and so on.
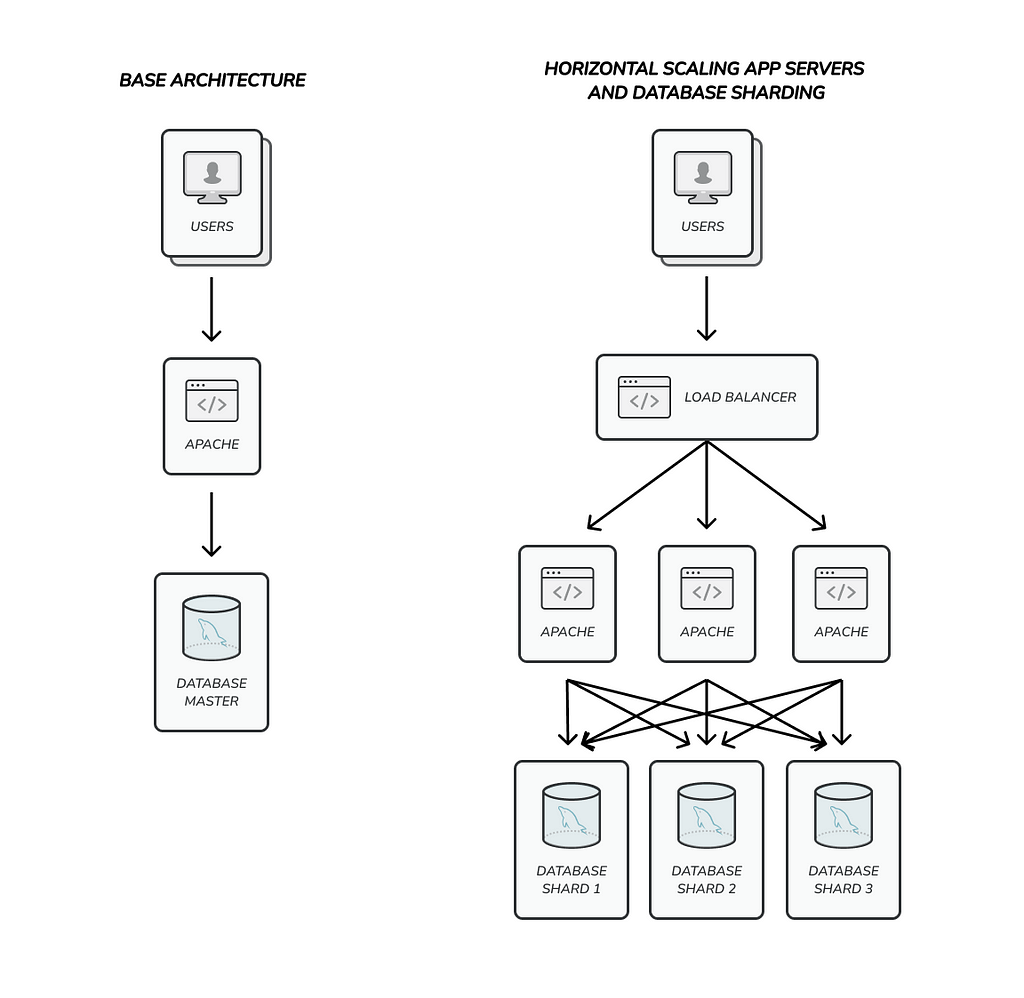
In my experience database sharding it’s not always a requirement to scale horizontally your application, you just need to use it when you need to scale write requests to your database.
Depending on the database engine sharding could be very easy to implement (like MongoDB) or could require you to write your own code to manage sharding.
Anyway, sharding requires advanced configurations and has many implications so you need to be sure before using it to avoid over engineering.
Conclusions
If your servers are running out of resources, scaling your application will solve your problems. You should select a scaling pattern depending on the problem you are facing.
The easiest and fastest way to make your system run faster is to implement a cache system. You should take into consideration two things: database engine and data structure. Depending on how you are going to access and store your information, data structure and database engines will differ.
Without any doubt the best way to have a reliable and scalable system is to scale horizontally every layer of your system, both application and database servers. Depending on the layer and the technologies you are using, scaling horizontally will be a matter of seconds or will require a lot of development hours.
Scaling your application will add more complexity to it, but it’s the only way you can make it grow. Because of this, when you scale your application you should balance your system complexity and performance improvement and analyze with caution every change. But believe me, there is no other way to handle millions of requests, you need to scale!
If you feel these concepts are a bit advanced for your knowledge on scaling applications, you can take a look at the first article of this series.
High scalability patterns for dummies was originally published in Level Up Coding on Medium, where people are continuing the conversation by highlighting and responding to this story.
This content originally appeared on Level Up Coding - Medium and was authored by Darío Rodríguez
Darío Rodríguez | Sciencx (2022-10-17T00:42:10+00:00) High scalability patterns for dummies. Retrieved from https://www.scien.cx/2022/10/17/high-scalability-patterns-for-dummies/
Please log in to upload a file.
There are no updates yet.
Click the Upload button above to add an update.