
This content originally appeared on Level Up Coding - Medium and was authored by Giedrius Kristinaitis
Handling data in microservices can be difficult, and careless use of caches and event buses can be problematic

A lack of sense of context in a microservice architecture is a big problem. Context is important, I wrote about it a bit in the first part of this mini-series on microservice design mistakes. You may want to check it out before proceeding with this.
Microservice Design Mistakes (Part 1): Ignoring Context
Without a sense of context, you risk ending up with god concepts/entities. A god concept is a concept that exists in most/all parts of the architecture with the same meaning across all of them, regardless of the context it’s used in.
Data Duplication
At first glance, it might seem great to have entities/concepts that mean the same thing everywhere, because you’re being consistent that way. However, a single form of an entity cannot easily cover all possible use cases. Trying to be too consistent doesn’t always work.
Let’s say you have a god entity. How do you proceed with the storage of the entities? How do you query them in the services that need them? A common approach is to create a single central repository that’s responsible for handing out the entities.
Handling data in the same form everywhere and having a single central repository to query it is a way of trying to be too consistent.
Let’s say you have a single service, and it always returns the entities in the same format, regardless of the use case. There are 2 things that could happen:
- You overload the single service that’s responsible for serving the god entities
- Instead of always fetching the data from a single central service you store copies of the required data in individual services that consume that data, either in a database or a cache
Which option appears to be better at first glance?
A lot of people are very concerned about performance when working on microservices, which makes perfect sense. Everyone knows that microservices are supposed to be scalable, so you can’t be introducing any bottlenecks.
So, with the performance concerns in mind people opt for the second option, the one that involves copies of data.
That’s nice and all, however, copies of data need to be in sync, and it’s a challenge to keep them updated. The more copies you have, the harder it becomes.
Data synchronization is difficult.
Cache Chains
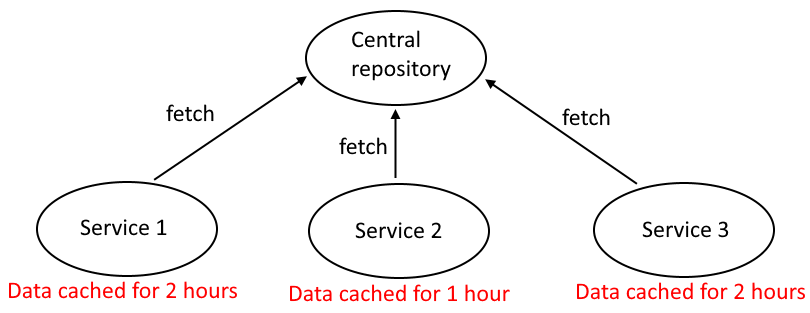
Ok, let’s say you have a central repository and 3 other services that fetch data from it and cache it for some time.
It’s not that bad, is it? If you had only the 3 services, then maybe it’s still acceptable, and by “had only 3 services” I mean for sure 100% all the way into the future. You don’t know what services you’ll add in the future, and if you do, you’re most likely lying. If you have every service planned ahead of time I have some bad news for you… Your architecture is too static.
If it always were just 3 services, we could live with that, and the services could look like this:
Now let’s say there are more services, all of which also cache data for themselves, then you could have a chain-like data flow that looks like this:
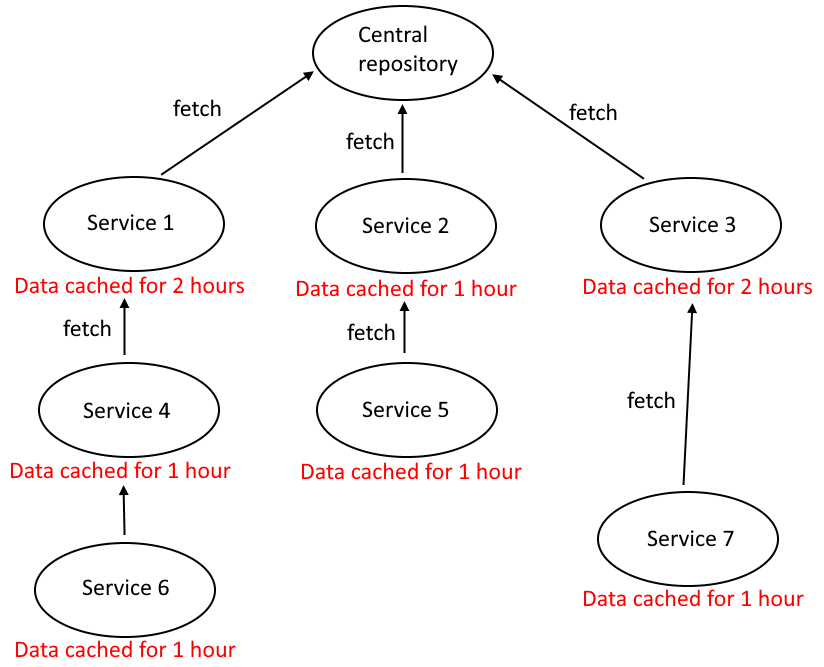
Causes of cache chains
Wait a minute… Why do the services take data from other services like that, and not the central service?
Legacy
One of the reasons for the emergence of such a data flow is the need to support legacy systems.
Legacy systems are messy and the way that data flows in them can be pretty bad, where you have one component taking data from another, and that component takes data from yet another component.
When you introduce microservices it could make sense to leave the legacy components the way they are. Sometimes even whole proxy services are created to serve as wrappers around legacy components, exposing literally the same operations.
When such wrappers are created, they copy the bad data flow of the legacy components, and that’s how you can end up with a chain-like data flow.
Lack of thought and design
Without the need to support a legacy system, the lack of any real design could play a role in the formation of long data float chains.
Why would anyone try to implement whole systems without any design? The misconception that you can’t do design in agile contributes to the problem. I mean, in agile, you never know how the requirements are gonna change, so you don’t do any design, right?
Not really. Here’s the thing about agile: it’s basically a no-design philosophy compared to the waterfall model, agile doesn’t have the design phase, however, that doesn’t mean that you can’t do any upfront design in agile, and thinking that you can’t is just ignorant.
People might do upfront design, however, people create one design, and then stick to it. A good design needs iteration, if you don’t iterate no matter how good your initial design is, you’re likely to end up with a concurrent distributed plate of spaghetti.
God entities
How does the chain-like data flow relate to not seeing the context and having god entities?
When you have a god entity that’s being passed around all the time in the same form you encourage coupling everything to the same form of data.
When everything’s coupled to the same form of data, the way of properly querying the data loses importance, because no matter the source of data, it’s always gonna be returned in the same form, so why bother with figuring out how to properly access the data when you can just get it from a neighbor service your service closely communicates with? It’s a rhetorical question. I think you should bother with figuring out how to properly access the data you need, and not take it from the first source that comes to mind.
Same old mindset
You can’t approach microservices with the same old mindset you used in old monolithic projects, because if you do you’re bound to repeat the same mistakes.
An outdated mindset could also contribute to the problem.
Common Solution
This is where it gets really exciting. Let’s say a data change happens in the central service. Now you have to wait for hours for all caches to expire, and if you add up the time, it takes at least 4 hours for the data update to take effect everywhere. Nobody has that much time, especially in a critical situation, which is bound to happen eventually. Such a solution doesn’t scale one bit.
A common approach to solve the waiting problem would be to introduce an event system, where whichever services need the updated data would get notified and would then fetch the updated data. Then we could have something like this:
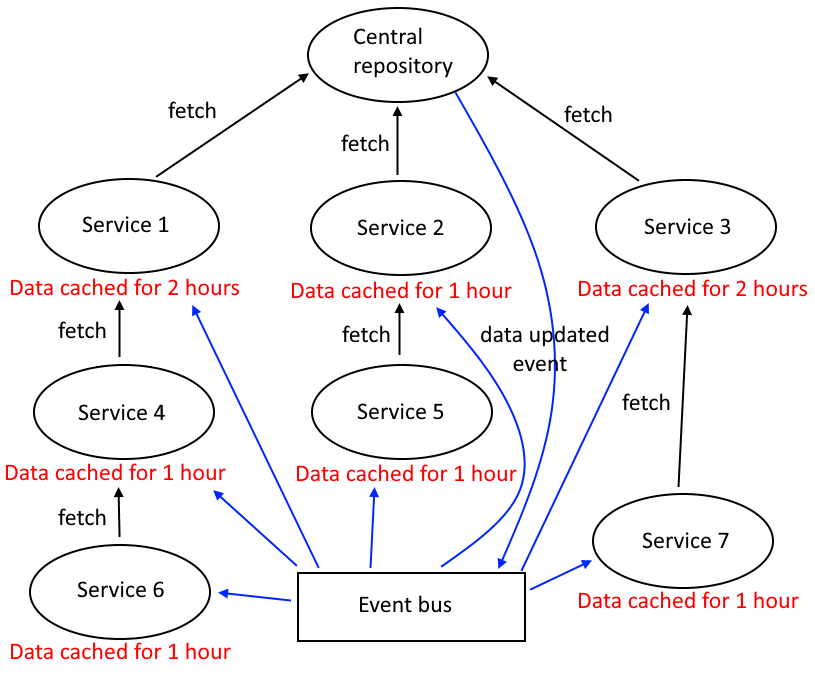
However, even this is very problematic and doesn’t fully solve the problem. If all services receive the data update event at the same time and start fetching data again, then it’s pure chaos, because there’s a sequence that must be followed, and it gets trashed when the event happens.
So if you do things this way you have no choice, but to wait, or create many more different types of events that notify about data updates in individual services, or, always fetch data from the central service, which could be a performance bottleneck. In short, the situation doesn’t look too bright.
Let’s make the situation even worse by introducing some communication between services to match the real world a bit more. We could have something like this:
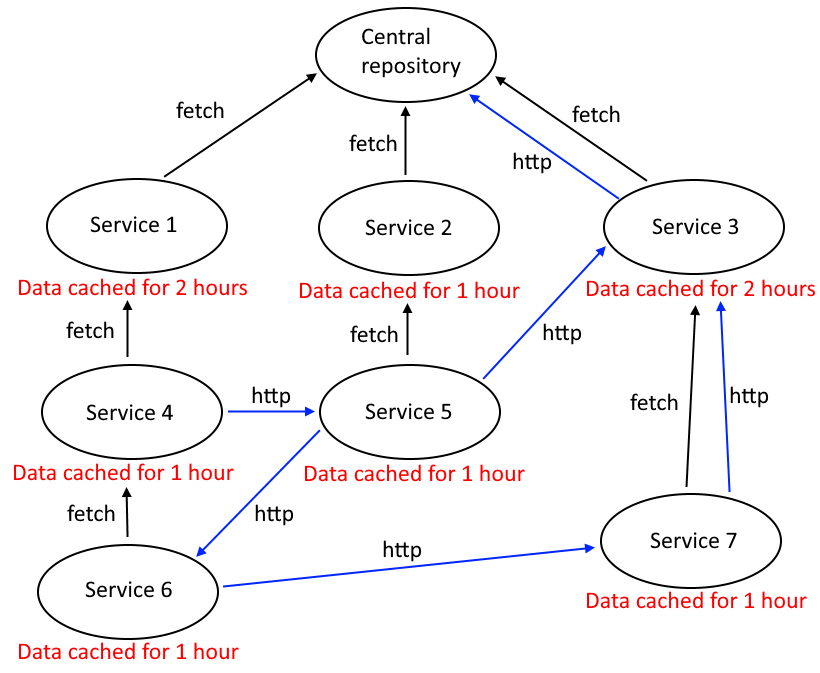
Now it’s not as simple as just fetching the data when an event gets fired. The correctness of communication requires the data to be in sync at all times, and synchronization takes a lot of time, even with the help of events it’s not instant.
I’m pretty sure nobody wants to end up in such a situation, not only because performance suffers a lot. Now, because of communication happening in an instant and the data not necessarily being synchronized, you can’t even trust the data you have at a given point in time, which creates a lot of corner cases you can never debug, much less fix.
Concurrency is difficult, very difficult.
Respect Context
Complex problems involve abstract ideas, it’s unavoidable. God entities and concepts result from poor abstractions and are a way of trying to be too literal. They introduce a lot of coupling and make the whole system static. It’s not a problem that’s specific to microservices only, but to software in general.
Central repositories could be split up
The problem in the examples could be minimized if data that’s not supposed to be together with other data was separated and context-specific.
Let’s say your domain is car sales. You have 2 bounded contexts: one for marketing, and another one for handling orders. When you need a car entity, you shouldn’t always fetch the whole car information everywhere. Order handling doesn’t care about the features of the car, it doesn’t matter if the car is black or blue, that’s for the marketing department.
A central repository becomes the equivalent of a god object that knows everything.
You could split up the central repository into smaller repositories of more cohesive data.
Again, context matters. Even if you split your central data repository into more cohesive pieces, it’s not going to do you any good if your microservices are not cohesive and respectful of context as well.
Limit cache chains
When you have smaller repositories of more cohesive data you reduce the number of services that access the data from a single repository, because not all of them need the same information.
Reduced usage makes all the performance concerns less of an issue, which can help you to eliminate chain-like data flows by allowing more smaller context-specific services to access smaller repositories.
Data caches flowing from one service to another can lead to a lot of copies of data that need to be kept in sync at all times. It is a serious concurrency problem that you should avoid. Handling data contextually should be preferred in order to help to avoid the problem.
Microservice Design Mistakes (Part 2): Data Cache Chains was originally published in Level Up Coding on Medium, where people are continuing the conversation by highlighting and responding to this story.
This content originally appeared on Level Up Coding - Medium and was authored by Giedrius Kristinaitis
Giedrius Kristinaitis | Sciencx (2022-11-14T03:22:00+00:00) Microservice Design Mistakes (Part 2): Data Cache Chains. Retrieved from https://www.scien.cx/2022/11/14/microservice-design-mistakes-part-2-data-cache-chains/
Please log in to upload a file.
There are no updates yet.
Click the Upload button above to add an update.