
This content originally appeared on Level Up Coding - Medium and was authored by Arslan Ahmad
Get your next system design interview off to a great start.
In this post, we will discuss seven system design concepts that can be used to solve design problems related to distributed systems. As these concepts can be applied to all kinds of distributed systems, they become very handy during system design interviews.
Here is the list of concepts we will be discussing:
- Merkle Tree
- Consistent Hashing
- Read Repair
- Gossip Protocol
- Bloom Filter
- Heartbeat
- CAP and PACELC Theorems
Let’s get started.
1. Merkle Tree
Used for identifying data inconsistencies between servers.
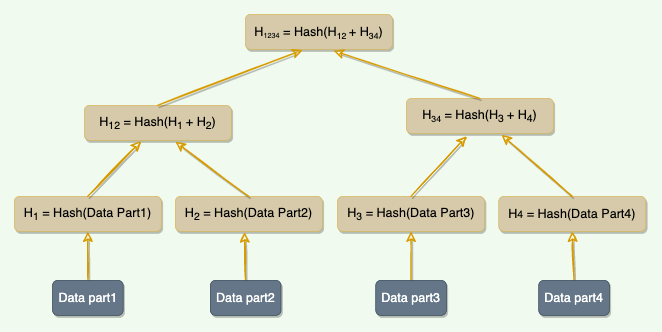
Background
Distributed systems maintain multiple copies of data on different servers (called replicas) for fault tolerance and higher availability. To keep the data in sync among all replica servers, the system needs an efficient mechanism to compare data between two replicas. In a distributed environment, how can we quickly compare two copies of a range of data residing on two different replicas and figure out exactly which parts are different?
Definition
A replica can contain a lot of data. Naively splitting up the entire range to calculate checksums for comparison is not very feasible; there is simply too much data to be transferred. Instead, we can use Merkle trees to compare replicas of a range.
Solution
A Merkle tree is a binary tree of hashes, where each internal node is the hash of its two children, and each leaf node is a hash of a portion of the original data.
Comparing Merkle trees is conceptually simple:
- Compare the root hashes of both trees.
- If they are equal, stop.
- Recurse on the left and right children.
Ultimately, this means that replicas know exactly which parts of the range are different, but the amount of data exchanged is minimized. The principal advantage of a Merkle tree is that each branch of the tree can be checked independently without requiring nodes to download the entire tree or the entire data set. Hence, Merkle trees minimize the amount of data that needs to be transferred for synchronization and reduce the number of disk reads.
The disadvantage of using Merkle trees is that many key ranges can change when a node joins or leaves, at which point the trees need to be recalculated.
Examples
For anti-entropy and to resolve conflicts in the background, Amazon’s Dynamo uses Merkle trees.
Details: https://lnkd.in/gZpt67uU
2. Consistent Hashing
Distributed systems use Consistent Hashing to distribute data across servers.
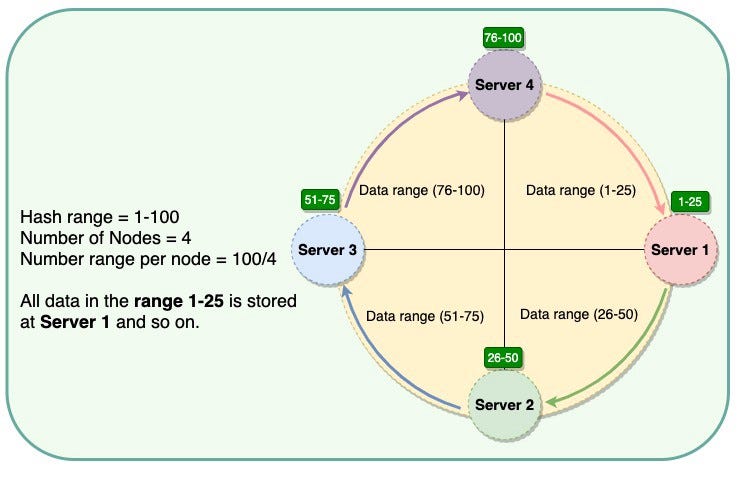
Consistent Hashing helps with two things:
- It maps data to physical servers. Whenever the system wants to read or write data, Consistent Hashing tells us which server holds the data.
- It ensures that only a small set of keys move when servers are added or removed.
More details: https://lnkd.in/dJQKjN6i
3. Read Repair
When the data is replicated across multiple servers, Read Repair is used to push the latest version of data to servers with older version.
Repair stale data during the read operation, since at that point, we can read data from multiple servers to compare and find servers with stale data.
Details: https://lnkd.in/g6kCVgvr
4. Gossip Protocol
Used for efficiently sharing state information between servers.
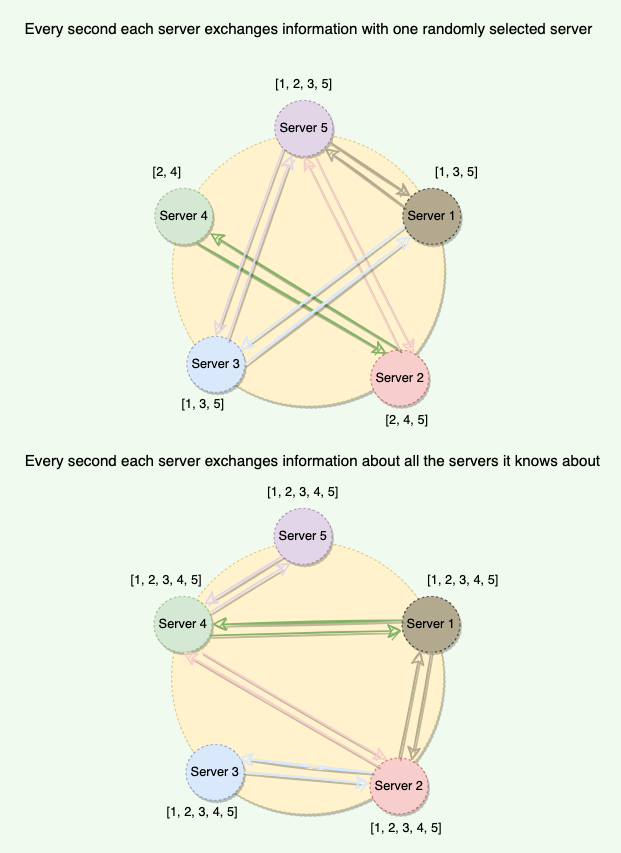
Each server keeps track of state information about other servers in the cluster and gossips (i.e., shares) this information with one random server every second. This way, eventually, each server gets to know about the state of every other node in the cluster.
Details: https://bit.ly/3D2w14j
5. Bloom Filter
The Bloom filter data structure tells whether an element may be in a set, or definitely is not. The only possible errors are false positives, i.e., a search for a nonexistent element might give an incorrect answer. With more elements in the filter, the error rate increases. An empty Bloom filter is a bit-array of m bits, all set to 0. There are also k different hash functions, each of which maps a set element to one of the m bit positions.
- To add an element, feed it to the hash functions to get k bit positions, and set the bits at these positions to 1.
- To test if an element is in the set, feed it to the hash functions to get k bit positions.
- If any of the bits at these positions is 0, the element is definitely not in the set.
- If all are 1, then the element may be in the set.
Here is a Bloom filter with three elements P, Q, and R. It consists of 20 bits and uses three hash functions. The colored arrows point to the bits that the elements of the set are mapped to.
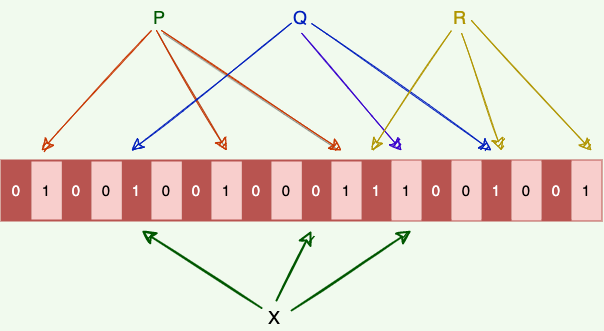
A Bloom filter consisting of 20 bits.
- The element X definitely is not in the set, since it hashes to a bit position containing 0.
- For a fixed error rate, adding a new element and testing for membership are both constant time operations, and a filter with room for ‘n’ elements requires O (n) space.
Details: https://bit.ly/3TbSAsR
6. Heartbeat
Used for broadcasting the health status of a server.
Background
In a distributed environment, data (or work) is distributed among servers. Such a setup requires servers to know what other servers are part of the system in order to route requests efficiently. Furthermore, servers should be able to tell if other servers are up and running. In a decentralized environment, whenever a request arrives at a server, the server should be able to decide which server is responsible for entertaining that request. In this way, timely detection of server failure is crucial, enabling the system to take corrective action and move data (or work) to another healthy server and stop the environment from deteriorating further.
Definition
In a distributed environment, each server periodically sends a heartbeat message to a central monitoring server or other servers in the system to show that it is still alive and functioning.
Solution
Heartbeating is one of the mechanisms for detecting failures in a distributed system. If there is a central server, all servers periodically send a heartbeat message to it. If there is no central server, all servers randomly choose a set of servers and send them a heartbeat message every few seconds. This way, if no heartbeat message is received from a server for a while, the system can suspect that the server might have crashed. If there is no heartbeat within a configured timeout period, the system can conclude that the server is not alive anymore and stop sending requests to it and start working on its replacement.
Example
Google File System (GFS) and HDFS use Heartbeating to communicate with each other servers in the system to give instructions and collect state.
Details: https://bit.ly/3eFnT04
7. CAP and PACELC Theorems
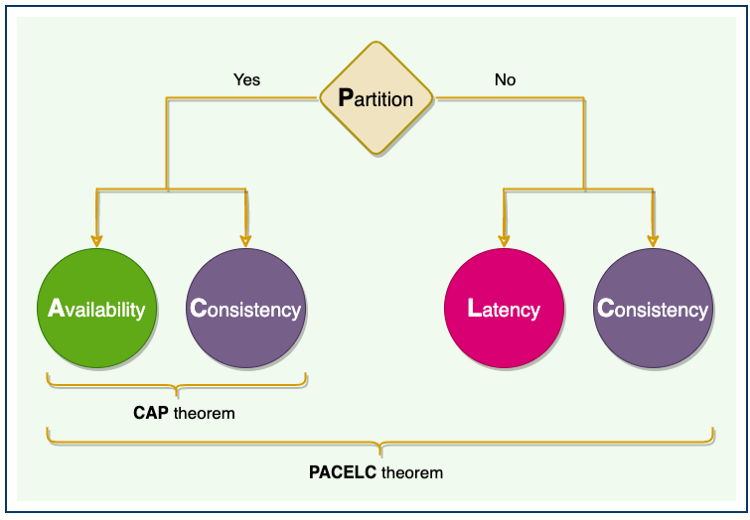
With the help of these two theorems, distributed systems can choose a good balance between Consistency, Availability, Partition Tolerance, and Latency.
Details: https://lnkd.in/dTFksWj9
Conclusion
➡ Practice these system design concepts to distinguish yourself from others!
➡ Learn more on these approaches in “Grokking the System Design Interview” and “Grokking the Advanced System Design Interview.”
➡ Follow me on Linkedin for tips on system design and coding interviews.
Read more on System Design and Coding Interviews:
- Don't Just LeetCode; Follow the Coding Patterns Instead
- The Complete Guide to Ace the System Design Interview
7 Algorithms to Know Before Your Next System Design Interview was originally published in Level Up Coding on Medium, where people are continuing the conversation by highlighting and responding to this story.
This content originally appeared on Level Up Coding - Medium and was authored by Arslan Ahmad
Arslan Ahmad | Sciencx (2022-12-20T23:22:34+00:00) 7 Algorithms to Know Before Your Next System Design Interview. Retrieved from https://www.scien.cx/2022/12/20/7-algorithms-to-know-before-your-next-system-design-interview/
Please log in to upload a file.
There are no updates yet.
Click the Upload button above to add an update.