
This content originally appeared on Bits and Pieces - Medium and was authored by Fernando Doglio
Implementing your first Neural Net in JavaScript

Neural Nets sound sexy and interesting. But what are they exactly? How do they achieve their magic and most importantly, can you build one without being an expert data scientist?
In this article I’m going to show you the basics of neural networks and how you can implement one yourself using existing tools.
This is going to be a very practical article, in the end I’ll show you how you can build your own Neural Network to draw a basic ASCII picture in your terminal.
Let’s get down to it!
Understanding Neural Networks
Neural networks are a special type of data structure composed of individual elements known as “neurons”. Neurons are grouped in layers and they connect to other neurons from other layers.
One of the most basic neural net structures is the Feedforward neural network, they consist of an input layer, one or more hidden layers, and an output layer, and information flows only in one direction (from the input layer to the output layer).
Here is a basic diagram to show what I mean:
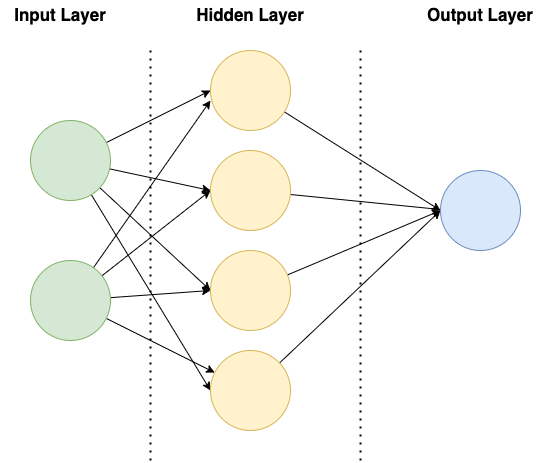
Essentially the input information is entered into the Input Layer, and from there the data gets transformed using values called “weights” and specific activation functions (functions that take a value and output a value between 0 and 1).
When you combine a group of these neurons and adjust the weights properly (which is what you do when you “train” the network), then the combined output is the expected one (or close enough) based on the inputs you provide.
For example, a basic example is solving the XOR equation. We all know that XOR works like this:
[0,0] => 0
[0,1] => 1
[1,0] => 1
[1,1] => 0
But if you create a feedforward network that has 2 inputs and 1 output neuron, once trained, you’ll be able to input any combination of 0’s and 1’s and you’ll get the expected XOR output, without actually programming the XOR behavior.
That is the main reason why you want to use neural networks, to achieve generalized behavior without actually coding every single rule.
Types of neural networks
There are many types of neural nets, each with its own set of characteristics and uses. Listing them all here and going deep into why you’d want to use them and how to implement it would defeat the practical approach of this article.
So here is a list of the most common ones (keep in mind there are others):
- Feedforward neural networks: we already covered this one above. These are the most common and simple networks, but they still have valid use cases.
- Convolutional neural networks (CNNs): These are neural networks designed for image recognition and processing tasks. They are particularly effective at learning features from image data and are commonly used in computer vision applications.
- Recurrent neural networks (RNNs): These are neural networks designed for sequential data processing tasks, such as language translation or speech recognition. They are particularly effective at learning patterns in sequential data and are commonly used in natural language processing (NLP) applications.
- Autoencoders: These are neural networks designed for dimensionality reduction and feature learning tasks. They consist of an input layer, a hidden layer, and an output layer, and are trained to reconstruct the input data at the output layer.
- Generative adversarial networks (GANs): These are neural networks designed for generating synthetic data. They consist of two networks: a generator network that generates synthetic data, and a discriminator network that tries to distinguish the synthetic data from real data.
- Transformers: They are very good at NLP and text generation. They have significantly improved the state-of-the-art results for many natural language processing tasks and have become widely used in the field. ChatGPT, for example, used these types of NN (Neural Nets) during the training process.
Depending on what type of behavior you want to achieve, you’ll use one or the other. In this article we’ll keep it simple, and for the first NN we’ll focus on a feedforward network.
Did you like what you read? Consider subscribing to my FREE newsletter where I share my 2 decades’ worth of wisdom in the IT industry with everyone. Join “The Rambling of an old developer” !
Implementing your first Neural Net
Since this is our first one and we’re looking for a practical approach, I don’t think we need to spend time re-inventing the wheel. There are plenty of tools out there that can help us achieve what we want, we just need to pick the right now.
In my case, I went with Synaptic, since it provides a low-level interface but the underlying building blocks are already there. So you get a good feeling of what needs to go into building a NN without having to worry about the deep math involved.
Instead of solving the XOR equation with our NN, which is one of the basic examples, I wanted to use it to “draw” an ASCII image on the terminal. The Image is relatively small because we’re trying to keep the training times small.

This is the matrix I want to draw, or rather, I want the NN to learn how to draw. So, what we’ll do is we’ll create a NN with the same 3 layers as before:
- An input layer with 2 neurons, for the X and Y coordinates.
- A hidden layer with 15 neurons.
- And an output layer with just 1 neuron, because I want to understand if for each set of coordinates, we have to print a 1 or a 0.
We’ll set the NN like this using Synaptic:
Now, for the training, we’ll use a learning rate of 0.3, which means our weights between neurons will adjust their value by 0.3 on every iteration. Then they’ll compare the result against what they should be printing, and on the next iteration they’ll adjust accordingly.
The image constant contains the output I want to achieve, I’ll be using it to train the network. It’s an 8x6 matrix of 0’s and 1's.
Then I’ll run 30k iterations for training, on every “pixel”, I’ll call the activate method, which enters the input into the input layer and then runs the NN. Then, using the propagate method, with the learningRate and the expected value for the last activation, the network will adjust itself.
Note: the little formula “y * 8 + x” is a little trick to navigate a one-dimensional array using cartesian coordinates. Essentially you do “<y coord> * <width> + <x coord>” and you don’t need a 2-dimensional array anymore.
Once the training is done, all we have to do is run through the coordinates again and ask it to activate, only this time, we’ll print out the results. For that, I’ve created the following function:
For every Y coordinate, we’ll save all results from activation into a list, and then once the row is finished (once we’ve gone through all X coordinates for that Y), we’ll print it out.
I’m using Math.round here with the result, because the output of the NN is not going to be 0 or 1, instead, it’ll be a number between both.
The result? Take a look:

As you can see the output is not perfect, notice how there are 2 mistakes in that image. Maybe by training it a little longer we’d get better results, but this is also one of the best results I’ve gotten.
You have to remember that since we’re looking to achieve generalized behavior without actually coding the exact algorithm needed, we won’t always get the right answer, and even then, the answer will not be perfect, but rather, close enough.
That’s why you get strange hands when generating images with Dall-e or Midjourney, or why ChatGPT sometimes writes sentences that are not true, or code that has bugs. They’re close enough based on the numbers resulting from their training.
Neural Nets can be very useful when you’re looking to achieve behavior that either needs to adapt to a varied number of inputs, or simply that coding it specifically would require a lot of work.
Instead, through training using the right type of inputs, you can get results that are close enough.
Have you used NN’s before? What did you use them for?
Build Apps with reusable components, just like Lego

Bit’s open-source tool help 250,000+ devs to build apps with components.
Turn any UI, feature, or page into a reusable component — and share it across your applications. It’s easier to collaborate and build faster.
Split apps into components to make app development easier, and enjoy the best experience for the workflows you want:
→ Micro-Frontends
→ Design System
→ Code-Sharing and reuse
→ Monorepo
Learn more
- How We Build Micro Frontends
- How we Build a Component Design System
- Bit - Component driven development
- 5 Ways to Build a React Monorepo
- How to Create a Composable React App with Bit
- Sharing JavaScript Utility Functions Across Projects
Advanced Data Structures and Algorithm: Neural Nets for Dummies was originally published in Bits and Pieces on Medium, where people are continuing the conversation by highlighting and responding to this story.
This content originally appeared on Bits and Pieces - Medium and was authored by Fernando Doglio
Fernando Doglio | Sciencx (2023-02-13T07:02:36+00:00) Advanced Data Structures and Algorithm: Neural Nets for Dummies. Retrieved from https://www.scien.cx/2023/02/13/advanced-data-structures-and-algorithm-neural-nets-for-dummies/
Please log in to upload a file.
There are no updates yet.
Click the Upload button above to add an update.