
This content originally appeared on Bits and Pieces - Medium and was authored by GaurangMittal
How to handle real-time processing of large amounts of data in distributed systems, why to use stream processing, how/why it is built.
Context
If you remember in 2008, LinkedIn ended up with a number of multiple point-to-point pipelines among multiple systems.
To organize, they started working on an internal project that eventually became Apache Kafka.
In a nutshell, Kafka is a buffer that allows producers to store new streaming events and consumers to read them, in real time, at their own pace.
So this led to evolution from Batch Processing of data by application to Real Time Stream Processing of Data.
Batch Processing System
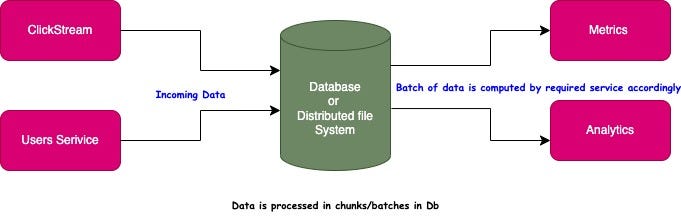
Brief Overview
In this system, all information was kept in either a database or a distributed file system and various programs would perform computations based on this information.
Since batch processing tools were built to process datasets of finite size, to continuously process new data, an application would periodically crunch data from the last period like one hour or one day.
The batch processing system has three limitations:
1. High latency leading to decreased value of data due to significant delay in computation of new results.
2. Difficult analysis of events spanning multiple time intervals, as session data is split into time intervals.
3. Non-uniform load, resulting in the system having to wait for sufficient data accumulation before processing the next block.
Real Time Stream Processing System
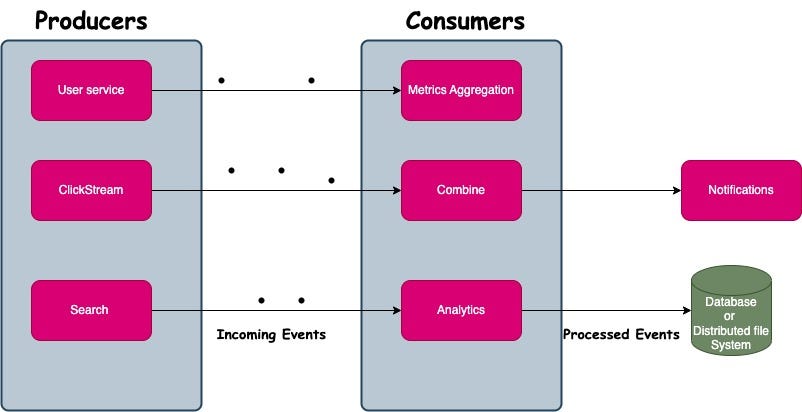
Stream processing is basically processing of flow of events.
Consists of Producers and Consumers.
Producers are those who produces the events.
Events in the system can be any number of things, such as financial transactions, user activity on a website, or application metrics.
Consumers can aggregate incoming data, send automatic alerts in real time, or produce new streams of data that can be processed by other consumers.
This architecture, however, poses a question:
- How should producers and consumers be connected?
2. Should a producer open a TCP session to every consumer and send events directly?
Introduction Of Apache Kafka
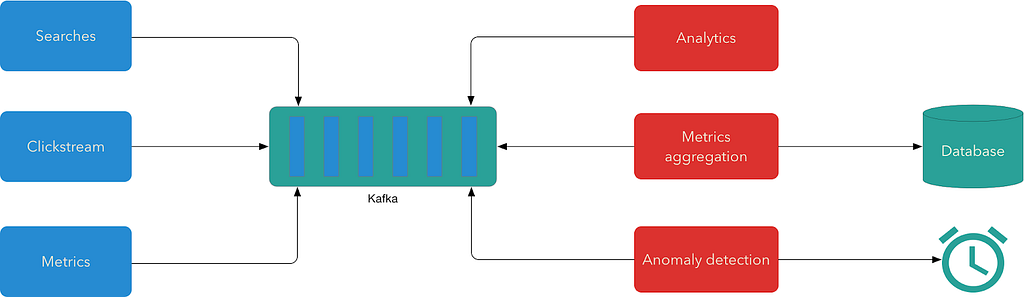
To solve above problem, linkedin created Apache Kafka.
Kafka is a buffer that allows producers to store new streaming events and consumers to read them in real time at their own pace.
Kafka is based on a data structure that forms the append-only log files.
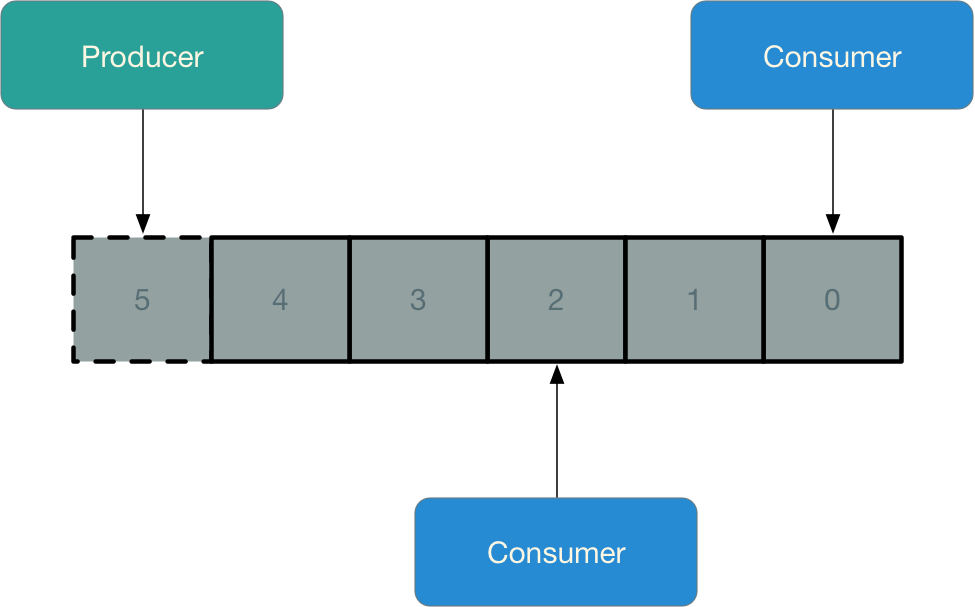
Append-Only Log
Modern Day Stream processing software is based on an append-only log data structure.
This log is simply a sequence of binary records with no restrictions on the format of the records (e.g. JSON, Avro, Protobuf).
The append-only nature of the log means that new elements can only be added to the end, not inserted at random positions, and existing elements cannot be removed.
Each log element is assigned a sequence number, with newer elements having a higher number than older ones.
Functionalities
- Consumers can read record, but those records are not deleted.
- No track of the records read or will be read by different consumers.
- Able to handle an enormous volume of transaction.
- Low latency.
- Consumers are also able to process data written to the log before they started.
We might have a fundamental question, then how does the records from the log is removed/evicted?
Retention Period
Every record entered in the log file has few default things like retention period, unique id to that record.
Retention period determines the time frame for which the record will be kept as alive in the log file, after the timeframe passes by the log record becomes inactive and will be removed by kafka.
In Kinesis, records are deleted after 24 hours but can be kept for up to 7 days with a longer retention period.
A longer retention period is useful if you need to reprocess data due to issues with handling incoming data. More time for reprocessing is available with a longer retention period, however, it also incurs increased storage costs.
Kafka offers the option of setting either a maximum retention period or maximum size for all records. The default retention period is 7 days, but it can be made infinite with log compaction enabled.
Scaling Of Kafka Streams
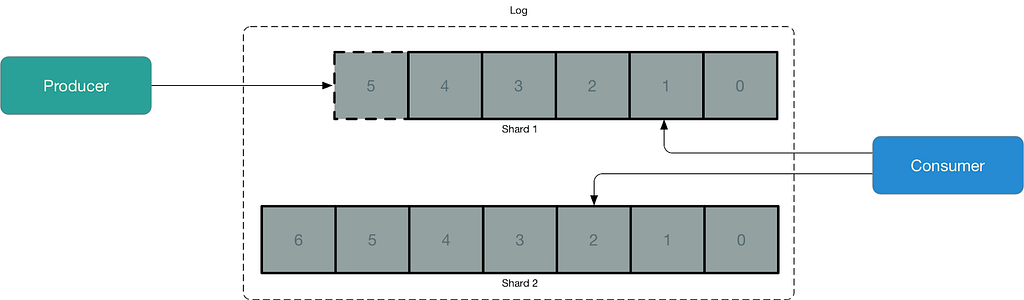
To handle an immense load, both systems apply two well-known tricks to allow to handle more reads and writes: sharding and replication.
Sharding
Sharding refers to the process of dividing log files into smaller parts, called shards, for improved scalability and parallel processing.
Each shard acts as a separate and independent unit of data storage and processing.
By distributing the incoming data across multiple shards, the system can handle larger amounts of data, provide higher throughput and process data in parallel for faster processing.
Strategy For Dividing Records Among Shards
Hash Key
We need to provide a key with each record.
This hash key could be a randomly generated unique number which will be associated with each record or it could be userid, paymentid, any unique attribute.
This will allow achieving order among records with the same key, since they will be directed to the same shard.
For each incoming record, Kinesis calculates a hash code of a key and the value of the hash code is used to determine what shard will process it.
Each shard is responsible for a portion of the hash code values range and if a hash code of a key falls within a shard’s range this shard will store a record associated with it.
When a shard reaches its storage limit, a new shard can be created to accommodate additional incoming data.
Sharding helps to balance the load, increase reliability and allow for horizontal scaling of a stream processing system.
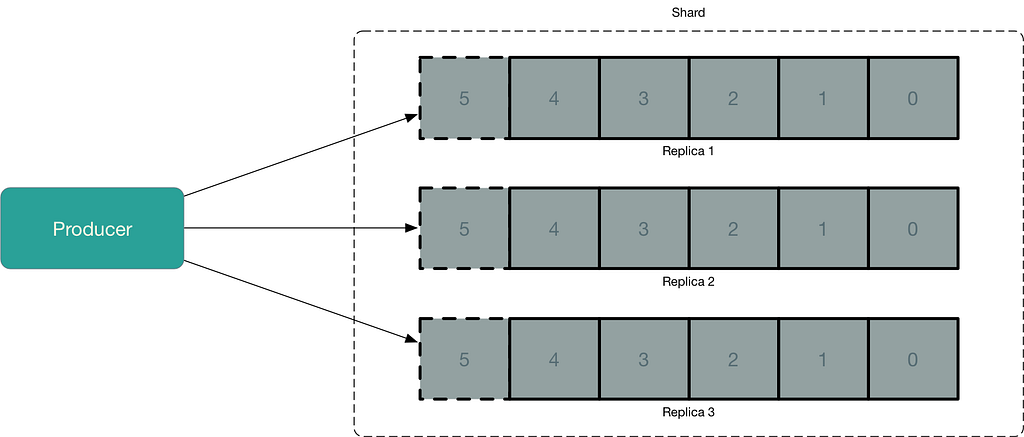
Replication
In databases, global replication refers to the practice of keeping multiple copies of data, allowing consumers to access data from any of the copies. Kinesis takes this a step further by having three copies of every record, located in three different data centers.
Key Challenges
- How do we distribute the work of reading records from a stream among multiple machines?
- If one of our machines reading from the stream failed, how do we ensure that we continue processing records correctly?
There are multiple stream processing systems that can process records from Kinesis or Kafka streams, such as Apache Spark, Apache Flink, Google Cloud Dataflow, etc.
Conclusion
In this article, we saw an overview of the real-time stream processing.
The latest stream processing systems are built on the append-only log data structure, which enables the creation of a data ingestion infrastructure. These systems allow producers to add new records to the log while multiple consumers can simultaneously read records from the same log.
Please follow me & give your valuable feedback. Check out my profile to see such more content. You can also contact me on LinkedIn.
Build apps with reusable components like Lego
Bit’s open-source tool help 250,000+ devs to build apps with components.
Turn any UI, feature, or page into a reusable component — and share it across your applications. It’s easier to collaborate and build faster.
Split apps into components to make app development easier, and enjoy the best experience for the workflows you want:
→ Micro-Frontends
→ Design System
→ Code-Sharing and reuse
→ Monorepo
Learn more
- How We Build Micro Frontends
- How we Build a Component Design System
- Bit - Component driven development
- 5 Ways to Build a React Monorepo
- How to Create a Composable React App with Bit
How to Handle Real-Time Stream Processing was originally published in Bits and Pieces on Medium, where people are continuing the conversation by highlighting and responding to this story.
This content originally appeared on Bits and Pieces - Medium and was authored by GaurangMittal
GaurangMittal | Sciencx (2023-02-24T12:10:33+00:00) How to Handle Real-Time Stream Processing. Retrieved from https://www.scien.cx/2023/02/24/how-to-handle-real-time-stream-processing/
Please log in to upload a file.
There are no updates yet.
Click the Upload button above to add an update.