
This content originally appeared on Level Up Coding - Medium and was authored by Radmila M.
My personal findings on comparing 3 simple operations in Julia and Python

Introduction
Many of you may have heard that learning foreign languages improves memory abilities, enhances analytical skills, develops problem solving and abstract thinking [1]. I believe that learning programming languages has the same benefits, therefore I decided to learn Julia while being a Pythonist.
In this article, I will compare 3 simple operations in both programming languages — working with a dataframe, its sorting & filtering, and making a plot.
Before we start, I want to emphasize that this post isn’t intended to compare apples with pears, i.e. technical characteristics of Python and Julia, but rather tries to summarize in which cases each language might be preferred due to its strengths.

I hope you are already a bit familiar with the Julia and Python programming languages and have installed them on your laptop (note: all code snippets in the post have been created via Jupyter Notebook, so integrate Julia and Python with it). If not, read these posts, first:
- Installing Julia on Ubuntu
- Introduction to Julia
- A Mini-Funny Julia Crash Course for Python and R Users
- Meet Julia: The Future of Data Science
- Exploratory data analysis in Julia
- How to Install and Getting Started With Python
- Everything About Python — Beginner To Advanced
Okay, let’s dive into the nuances of Python and Julia!
1. Working with data
1a. Creating DataFrame
A dataset is a set of data which usually has a certain form, while a dataframe is a special structure that organizes your data into a 2D table consisting of rows and columns, like a spreadsheet in Excel. DataFrame is one of the most common structures used in data analytics today, since it is flexible and powerful in terms of storing and working with data.
Julia
Here and after, I assume that the DataFrames package has been already installed on your machine via using Pkg and Pkg.add(“DataFrames”). Then you should apply using DataFrames to place relevant variables within your current namespace.
The easiest way of constructing a DataFrame in Julia is to pass column vectors using keyword arguments or pairs, for instance, let’s create a DataFrame [2], which contains information about my typical weekly physical activity during spring and summer:
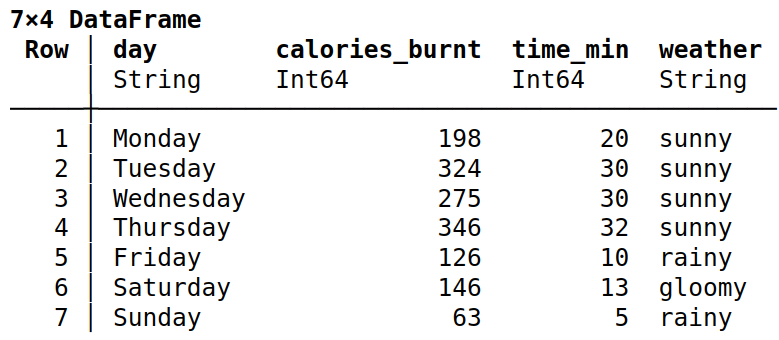
The code in Julia would look like this:
using DataFrames
# Create DataFrame
df = DataFrame(day = ["Monday", "Tuesday", "Wednesday", "Thursday", "Friday", "Saturday", "Sunday"],
calories_burnt = [198, 324, 275, 346, 126, 146, 63],
time_min = [20, 30, 30, 32, 10, 13, 5],
weather = ["sunny", "sunny", "sunny", "sunny", "rainy", "gloomy", "rainy"]
)
println(df)
A nice thing is that Julia automatically distinguishes types of your data in a dataframe, as it might be seen from the table above.
Python
There are many ways to create data frames in Python, I will demonstrate only one of the possible options that I use most often — through Pandas, where input data in DataFrame is saved as a list of lists.
The Python code in this case would look as follows:
# Import pandas
import pandas as pd
# State the list of lists
data = [['Monday', 198, 20, 'sunny'], ['Tuesday', 324, 30, 'sunny'], ['Wednesday', 275, 30, 'sunny'],
['Thursday', 346, 32, 'sunny'], ['Friday', 126, 10, 'rainy'], ['Saturday', 146, 13, 'gloomy'],
['Sunday', 63, 5, 'rainy']]
# Create DataFrame
df = pd.DataFrame(data, columns=['day', 'calories_burnt', 'time_min', 'weather'])
df
And the output will appear in the form of the table:
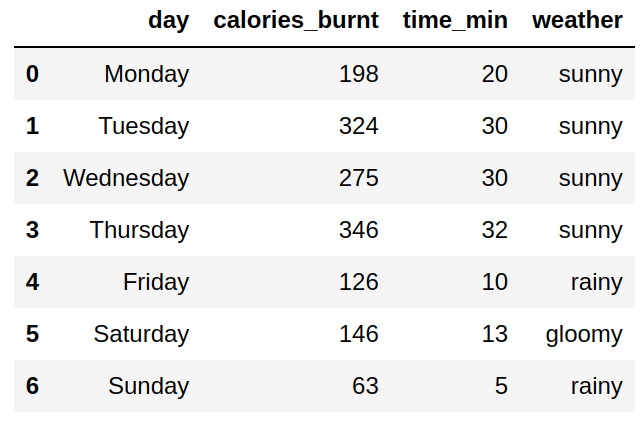
As you can see from the comparison of the two output tables, the first difference between Python and Julia deals with filling dataframes: in Julia we fill data vertically, in Python — row by row. Another distinction is the way of counting — in Python the count starts at 0 and ends at 6, while in Julia it starts at 1 and ends at 7.
1b. Reading a csv file
Except creating dataframes, you might often need to read files with data. The most common format for spreadsheets and databases is so-called csv (Comma Separated Values) format. Below we would discuss how one can efficiently read large datasets from a csv file using Julia and Python to measure which of them make it faster.
As an input dataset, we will use open-source Comprehensive Earthquake Dataset from Kaggle [3]. This dataset provides information on significant earthquakes that have occurred around the world since 1900 with a magnitude of 5 or above (96175 rows). The data includes essential details such as location, date and time, magnitude, depth, and other relevant information about each earthquake (23 columns in total).
Julia
In order to import the csv file in Julia, you may use the following code:
using CSV
using DataFrames
using BenchmarkTools
# Read .csv file
data = CSV.read("Significant_Earthquakes.csv", DataFrame)
# Evaluate the performance of Julia code
@btime CSV.read("Significant_Earthquakes.csv", DataFrame)
Again, I assume that you have already installed the CSV package via using Pkg and Pkg.add(“CSV”) in addition to already used DataFrames package. For reading CSV file in Julia you then need to apply CSV.read command.
To evaluate the performance of Julia code, it is possible to use BenchmarkTools package and @btime command with CSV.read(“file_name.csv”, DataFrame):
214.656 ms (1346701 allocations: 76.72 MiB)
Alternatively, some people recommend use the time function, @time with CSV.read(“file_name.csv”, DataFrame). In this case, you should apply it twice, because@time measures all time, including compilation time. Second run is going to be more or less “clean”, so results are well aligned with those obtained with @btime:
0.228419 seconds (962.34 k allocations: 69.391 MiB)
Python
There are several ways to read a CSV file in Python, either using the CSV module or the Pandas library. In the latter case, it is very easy to apply read_csv() method to read data from CSV files.
Below I provide a code snippet written in Python that illustrates the reading a CSV file and getting its values in the console with calculation of the time it takes to read all records in the input CSV file. For this purpose time module can be used.
time.time() records the current system time — we have two variables, init_time and final_time, which are defined before and after execution of the csv_reader function. Time difference is calculated in the last line of the code:
import time
import pandas as pd
def csv_reader():
read_file = pd.read_csv('Significant_Earthquakes.csv', delimiter=',')
print(read_file)
init_time = time.time()
cr=csv_reader()
final_time= time.time()
print('It took the CSV reader', "%.4f" %(final_time - init_time), 'seconds to read the file')
The output of the above code is:
It took the CSV reader 0.4353 seconds to read the file
As you can see, it is almost twice as slow as performance of the similar code in Julia.
2. Sorting & filtering
You can sort a DataFrame in Python and Julia by row or column values. Both rows and columns have indices, which represent the data positions in the DataFrame. You can retrieve data from specific rows or columns using DataFrame index locations.
In the current post, we will look at sorting the dataset created in the previous step, as well as filtering rows with a given condition.
Julia
In order to make sorting DataFrame in Julia, it is possible to apply sort. Because your data contains many rows and columns, you may often need to sort your data based on a particular column. For instance, if you want to sort DataFrame on the duration of physical activity (in minutes), run the following code snippet:
# Sort DataFrame in ascending order
df_sort = sort(df, "time_min")
println(df_sort)
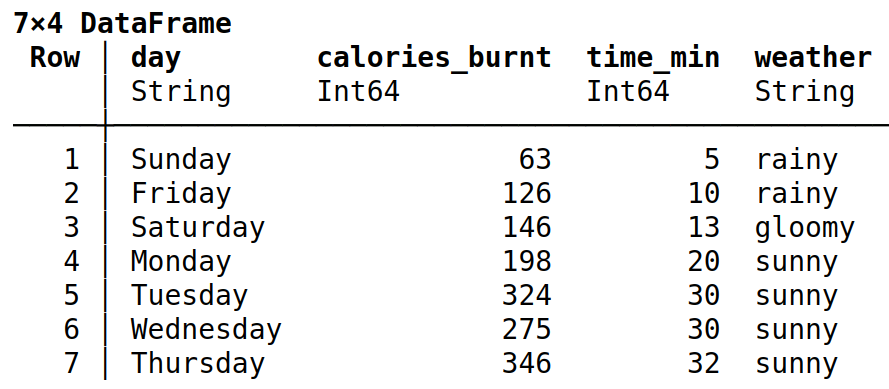
As one might noticed, in this case we got a sorting in ascending order. If you want the opposite effect (i.e. descending order), you should add rev=true, so the code would look as follows:
# Sort DataFrame in descending order
df_sort = sort(df, "time_min", rev=true)
println(df_sort)
To filter for choosing exercise sessions which lasted for less than or equal to 20 minutes, it is possible to use the code fragment below:
# Filter DataFrame to get shorter sessions (less than or equal 20 minutes)
df_short = filter(row -> row.time_min<=20, df)
println(df_short)
Python
By default, Python, as Julia, sorts data in ascending order:
# Sort DataFrame in ascending order
df_sort = df.sort_values(by='time_min')
df_sort

If you want the reverse order, just specify it in your code, i.e. df_sort = df.sort_values(by=’time_min’, ascending=False).
In order to filter the DataFrame for including rows where time_min is less than or equal to 20 minutes, apply the following code:
# Filter DataFrame to get shorter sessions (less than or equal 20 minutes)
df_short = df[df.time_min<=20]
df_short
As it can be seen, the way Julia filters the data is a bit different from how it works in Python and doesn’t require double repetition of df, but includes such an unusual sign, as arrow.
3. Making a plot
Let’s create a simple bar chart which would display the dynamics of physical activity during the week.
Julia
The code in Julia is given below (again, don’t forget to install the Plots package via Pkg.add(“Plots”) in addition to already used DataFrames package):
using DataFrames
using Plots
bar(df.day, df.time_min, legend = :none)
annotate!(df.day, df.time_min, df.time_min, :bottom)
ylabel!("Spent time (in minutes)")
xlabel!("Days")
savefig("plot.png")
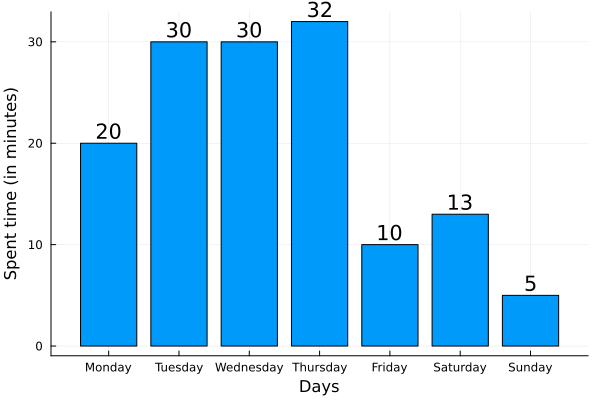
The main features of making bar charts in Julia are summarized below:
- List all used packages at the beginning of the code
- Apply bar function, where state values for x and y respectively, as well as specify the legend
- Use annotate to show the values of each bar on top of them
- Specify axes names using xlabel and ylabel
- To save a plot to local file storage, use the savefig(“filename”) method
- Don’t forget to use ! :)
Python
In general, creating horizontal bar charts in Python is similar on how it does in Julia, except the way of creating labels to annotate each bar. In Python it requires far longer code snippet with some additional manipulations:
import pandas as pd
from matplotlib import pyplot as plt
plt.figure(figsize =(10, 7))
# Complicated way of creating labels to annotate each bar
for count, data in enumerate(df.time_min):
plt.text(y=data+1,
x=count-0.1,
s=f"{data}", color='black',
va='center', fontweight='bold')
# Horizontal Bar Plot
plt.bar(df.day, df.time_min)
plt.xlabel("Days")
plt.ylabel("Spent time (in minutes)")
plt.savefig("plot_2.png")

Conclusion
I hope that after reading this post, you have got a piece of motivation to expand the base of programming languages by adding into your portfolio few more. Learning, or at least getting some basic understanding of second, third, maybe even fourth programming language, allows you to become more experienced programmer with higher flexibity on switching between various projects. And this seems to be a wise investment into the future, right?
If we are talking about Python and Julia, they both have their own special characteristics. For example, I like Python for its unique and wide range of available libraries. In this article, I have covered Pandas and Matplotlib, since I use them most often, but there are many nice alternatives in Python, e.g. Polars and Seaborn.
But what about Julia? Well, I enjoy how this programming language works with dataframes when the count starts from 1. Another great thing is how easy to create bar charts in Julia.
Below I have generated an image showing two people running behind each other: the fastest person is the sprinter and this is Julia, for sure. The second is a marathon runner, and for me that’s Python. With this metaphor, I tried to make a clear distinction between when I would use one programming language and when — another. For the vast majority of tasks within the data pipeline, I would choose Python, since it is more familiar to me. However, for some tasks that involve reading large datasets, I would definitely prefer Julia, because it is fast and powerful.

P.S.
Although I am just starting to learn Julia programming language, I don’t lose hope of becoming a polyglot programmer one day, who knows perfectly at least 3 or 4 programming languages. Wish me good luck, and thanks for reading!
The code appeared in this article is available on the author’s GitHub.
References
- Webpage “How learning a new language changes your brain” (https://www.cambridge.org/elt/blog/2022/04/29/learning-language-changes-your-brain/)
- Webpage “How to Create a DataFrame in Julia” (https://datatofish.com/dataframe-julia/)
- Comprehensive Earthquake Dataset from Kaggle: https://www.kaggle.com/datasets/usamabuttar/significant-earthquakes
Level Up Coding
Thanks for being a part of our community! Before you go:
- 👏 Clap for the story and follow the author 👉
- 📰 View more content in the Level Up Coding publication
- 💰 Free coding interview course ⇒ View Course
- 🔔 Follow us: Twitter | LinkedIn | Newsletter
🚀👉 Join the Level Up talent collective and find an amazing job
On the Way to Becoming a Multi-Language Programmer was originally published in Level Up Coding on Medium, where people are continuing the conversation by highlighting and responding to this story.
This content originally appeared on Level Up Coding - Medium and was authored by Radmila M.
Radmila M. | Sciencx (2023-04-27T13:58:02+00:00) On the Way to Becoming a Multi-Language Programmer. Retrieved from https://www.scien.cx/2023/04/27/on-the-way-to-becoming-a-multi-language-programmer/
Please log in to upload a file.
There are no updates yet.
Click the Upload button above to add an update.