
This content originally appeared on HackerNoon and was authored by Rahul Sarabu
Introduction:
Google Bigquery is renowned for its ability to process massive datasets quickly and efficiently. However, it has its limitations, especially when handling large JOIN operations. These operations can result in performance degradation, increased costs, and even query failures. In this article, we explore these challenges and present a strategic approach to optimize JOINs in BigQuery.
\ Challenge: Handling Large JOIN Operations in Bigquery
Bigquery handles JOIN operations by distributing the workload across multiple nodes. However, issues like data skew, inefficient use of resources, and the complexity of joining large tables can lead to significant performance issues. This problem becomes more frequent as data volumes grow , causing longer query execution times and higher costs.
\ Lets consider to join large transactions table with a customers table:
SELECT
c.customer_id,
c.customer_name,
t.transaction_id,
t.transaction_amount
FROM
`cdl.dim.customers` AS c
JOIN
`cdl.fact.transacations` AS t
ON
c.customer_id = t.customer_id
WHERE
t.transaction_date > '2024-01-01';
This query may take several minutes to execute, especially if the transactions table contains billions of records.
\ Solution: Optimizing JOINs with Partitioning and Pre-Filterting
Below are the few strategies that can be leveraged to overcome the limitations of large JOINs.
\
Paritioning and Clustering:
Partitioning the transactions table by transactiondate and clustering it by customerid ensures that Bigquery processes only the relevant partitions, reducing the amount of data scanned during the JOIN.
CREATE OR REPLACE TABLE `cdl.fact.transactions_partitioned_clustered` PARTITION BY DATE(transaction_date) CLUSTER BY customer_id AS SELECT * FROM `cdl.fact.transactions`;\
Pre-filtering Data:
Filtering the transactions table before performing the JOIN reduces the data processed, leading to faster execution and lower costs.
WITH filtered_transactions AS ( SELECT * FROM `cdl.fact.transactions_partitioned_clustered` WHERE transaction_date > '2024-01-01' ) SELECT c.customer_id, c.customer_name, t.transaction_id, t.transaction_amount FROM `cdl.dim.customers` AS c JOIN filtered_transactions AS t ON c.customer_id = t.customer_id;\
Materialized views for Frequent JOINs:
Creating a materialized view to store the result of frequent JOINs can significantly speed up future queries by avoiding repeated calculations.
CREATE MATERIALIZED VIEW `cdl.fact.customer_transaction_summary` AS SELECT c.customer_id, c.customer_name, t.transaction_id, t.transaction_amount FROM `cdl.dim.customers` AS c JOIN `cdl.fact.transactions_partitioned_clustered` AS t ON c.customer_id = t.customer_id WHERE t.transaction_date > '2024-01-01';
\ Experimental Results : Performance Comparison
To measure the effectiveness of these optimizations, we ran a series of query executions comparing the performance of the original unoptimized query with the optimized versions.
Below table has the results of each approach
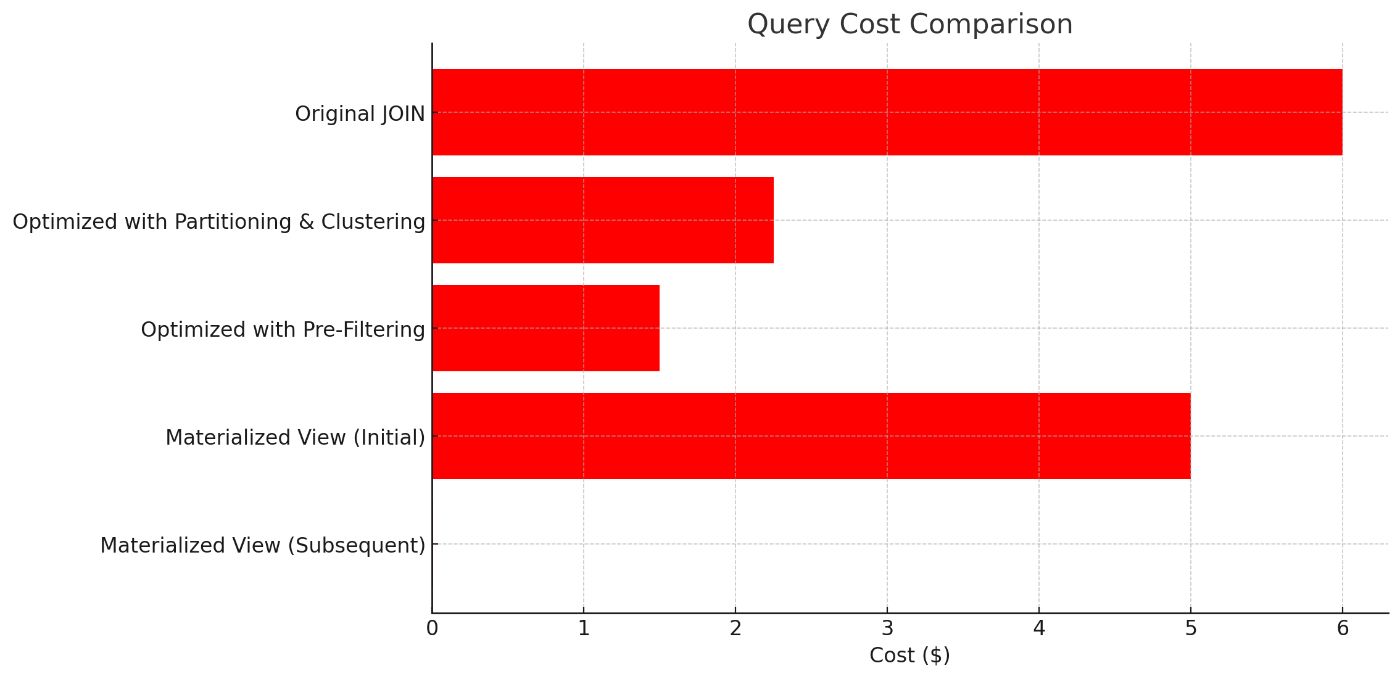
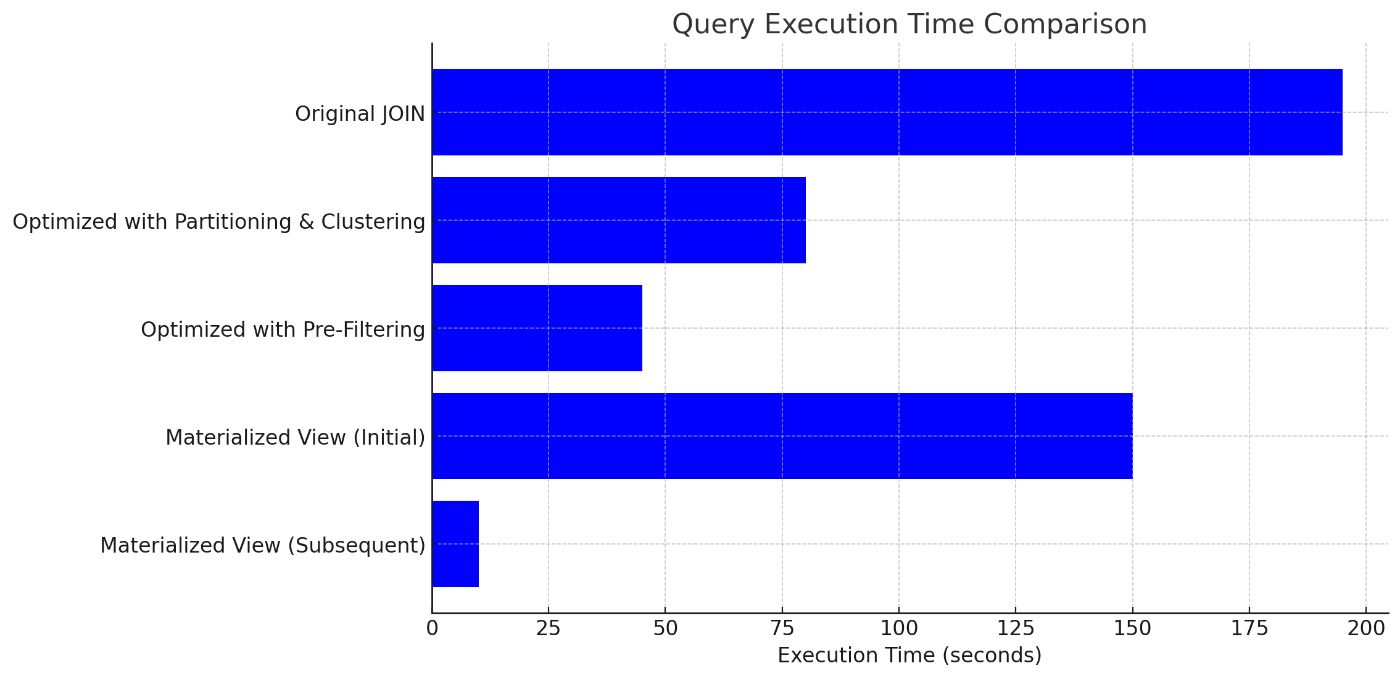
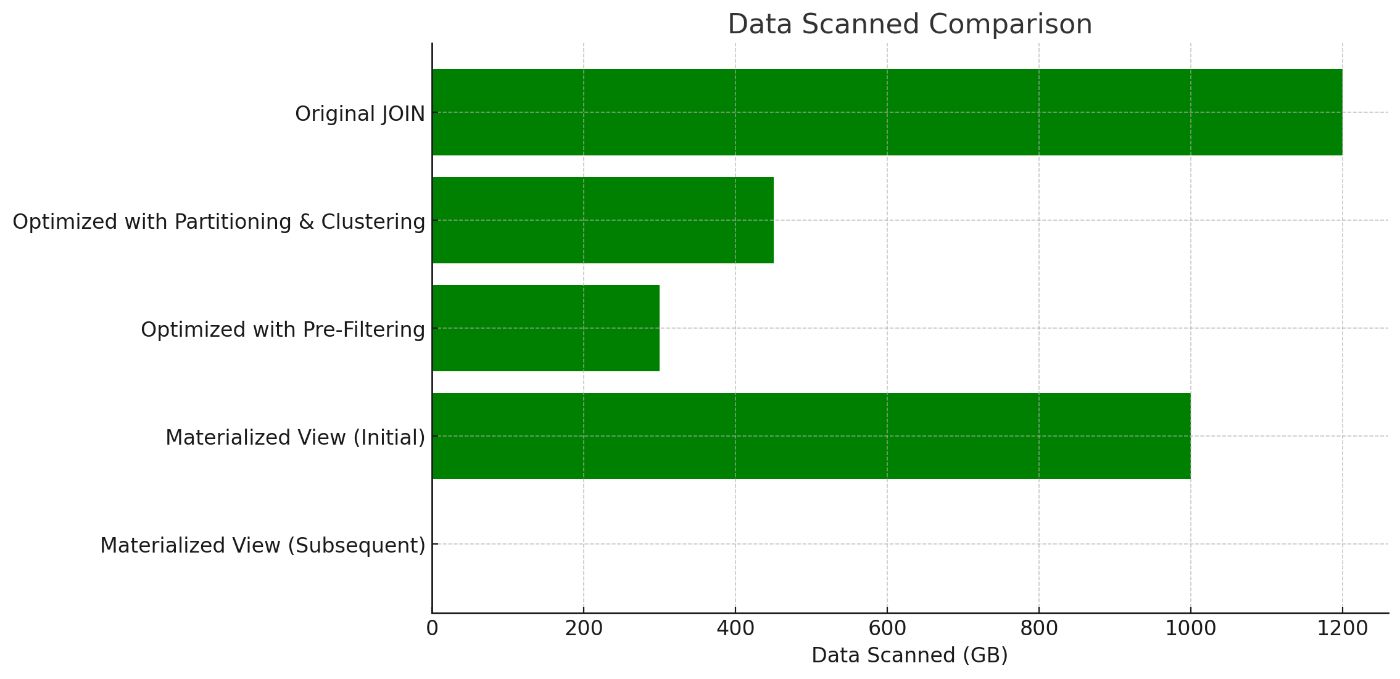
| Query Type | Execution Time | Data Scanned | Cost | |----|----|----|----| | Original JOIN | 3mins 15sec | 1.2TB | $6.00 | | Optimized with Partitioning and Clustering | 1min 20sec | 450GB | $2.25 | | Optimized with Pre-Filtering | 45sec | 300GB | $1.50 | | Materialized View (Initial) | 2min 30sec | 1.0TB | $5.00 | | Materialized View (Subsequent) | 10sec | 10MB | $0.01 |
\
\
\
Result Analysis
- Original JOIN: The unoptimized query was slow and costly due to the large volume of data processed.
- Partitioning and Clustering: Implementing partitioning and clustering reduced the data scanned by over 60%, resulting in 58% reduction in execution time and cost.
- Pre-Filtering: By filtering before the JOIN, we further reduced the execution time to 45 sec and cut the data scanned to 300GB, reducing costs by 75%.
- Materialized View: Initial creation of the materialized view took time and scanned significant amount of data, but subsequent queries were very fast and extremely cost effective.
Conclusion:
The performance gains from these optimizations are substantial. By intelligently partitioning and clustering data, pre-filtering datasets, and leveraging materialized view, you can overcom BigQuery’s limitation with large JOIN operations. These strategies not only improve query performance but also significantly reduce costs, making your data processing more efficient.
For Data Engineers dealing with large scale datasets, these optimizations are crucial. They ensure that BigQuery can handle even the most complex queries swiftly and economically, allowing you to maximize the value of your cloud investment.
Final Thoughts:
As data volumes continue to grow, the ability to optimize and manage large JOIN operations in BigQuery will become increasingly important. By applying the techniques discussed in this article, you can stay ahead of performance bottlenecks and increased costs, ensuring that your data pipelines are both powerful and efficient.
\
This content originally appeared on HackerNoon and was authored by Rahul Sarabu
Rahul Sarabu | Sciencx (2024-08-23T01:03:12+00:00) Optimizing JOIN Operations in Google BigQuery: Strategies to Overcome Performance Challenges. Retrieved from https://www.scien.cx/2024/08/23/optimizing-join-operations-in-google-bigquery-strategies-to-overcome-performance-challenges/
Please log in to upload a file.
There are no updates yet.
Click the Upload button above to add an update.