
This content originally appeared on Level Up Coding - Medium and was authored by Pavan Belagatti

The rise of large language models (LLMs) has revolutionized how we generate and retrieve information. However, as LLMs evolve, new features, such as the long context window, are gaining attention. This raises an important question: will these advancements render techniques like Retrieval Augmented Generation (RAG) obsolete?
In this article, we’ll explore what long-context windows are, why they are in demand, and how they compare to RAG in shaping the future of AI-driven applications.
What is Context Window in LLMs?
A context window in the context of large language models (LLMs) refers to the amount of text or information that the model can “remember” or process at once when generating a response. It represents the maximum number of tokens (words or pieces of words) that the model can take into account during a single interaction.
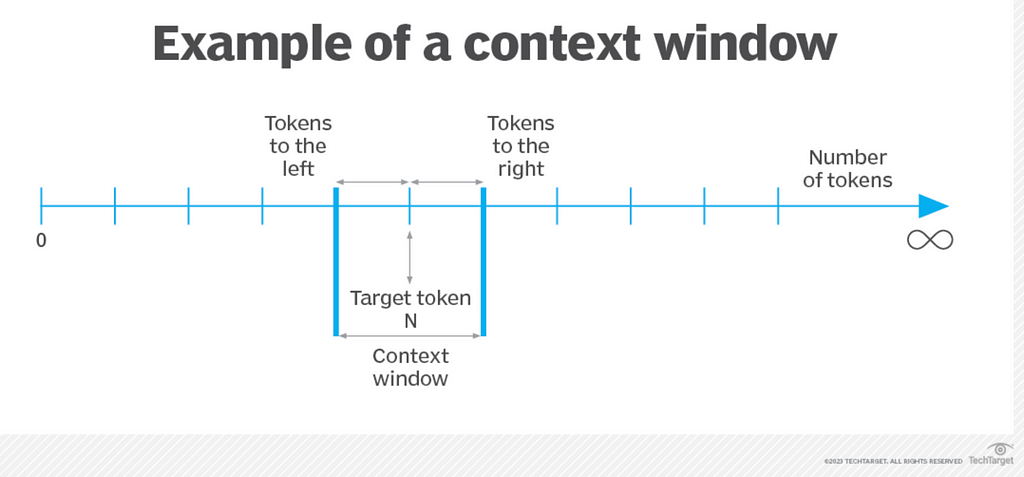
For example, when you provide an LLM with a prompt, the model generates a response based on the information within the context window. If the context window is 1,000 tokens, the model will consider the last 1,000 tokens of text when producing its output.
The size of the context window is important because it defines how much prior information the model can reference. A larger context window allows the model to handle longer documents or more complex interactions without losing track of previous details, making it more efficient in tasks like summarizing long articles, answering questions about large documents, or maintaining coherent conversations over many turns. Conversely, a smaller context window may cause the model to “forget” earlier parts of the input if it exceeds the window size, potentially leading to less coherent or contextually accurate responses.
Why LLMs with Long Context Window Are in Demand
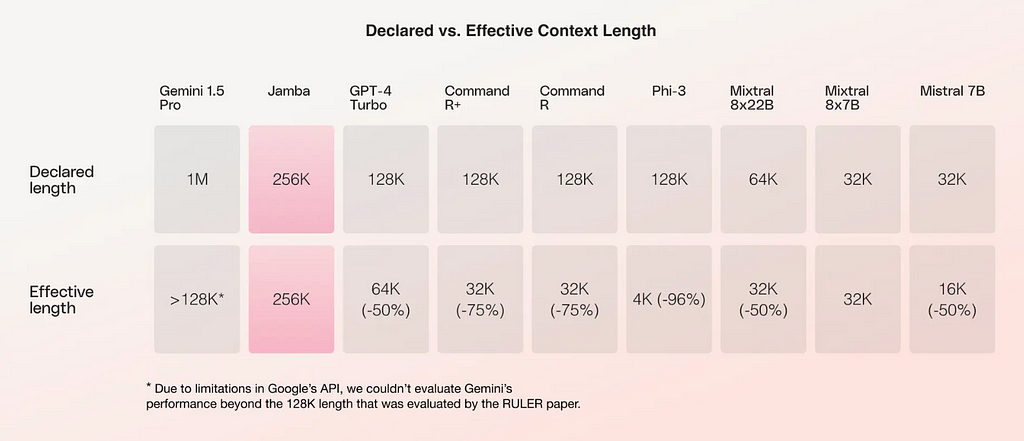
Large Language Models (LLMs) with long context windows are in high demand due to their ability to process and understand larger chunks of data over extended conversations or documents. Traditional LLMs, constrained by short context windows, struggle to retain information from earlier parts of interactions, which can limit their performance in tasks requiring deeper comprehension or long-term memory. This is particularly critical in scenarios like document summarization, long-form content generation, or customer service chats where users expect continuity and context retention across multiple exchanges.
With an extended context window, LLMs can maintain coherence across lengthy inputs, allowing them to better interpret and connect distant ideas or details. This enhances their capability in generating more accurate summaries, crafting detailed responses in technical writing, and improving decision-making in real-time applications like code generation, research assistance, or legal analysis.
Additionally, LLMs with longer context windows reduce the need for repeated user input, saving time and improving the overall user experience. Industries such as healthcare, finance, and customer service benefit from these improvements, as they often deal with complex datasets requiring nuanced understanding. By capturing more information in a single interaction, these models deliver greater efficiency, making them indispensable for real-time AI applications.
What is Retrieval Augmented Generation (RAG)?
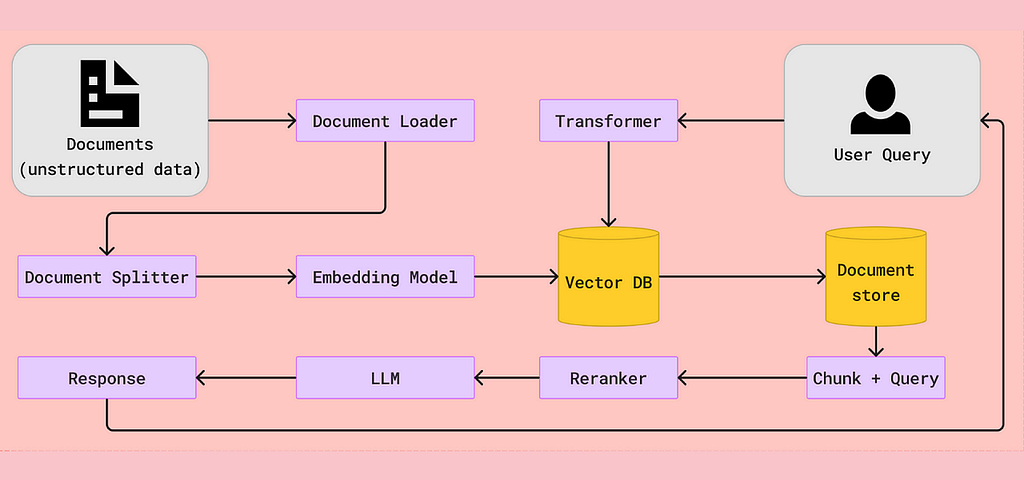
RAG combines two techniques: retrieval of relevant external information and generating responses using an LLM. Instead of relying solely on the model’s internal memory, RAG actively searches for external sources of knowledge, such as databases or web articles, to provide more accurate and up-to-date answers. This makes RAG highly effective when dealing with tasks where the information is too vast to be contained within a model’s internal parameters alone.
By retrieving specific data in real-time, RAG enhances the precision of responses, especially in fields requiring detailed or evolving knowledge, such as research, technical support, and legal analysis. It also reduces hallucinations, as the model can reference external facts rather than generate potentially incorrect or irrelevant content from its internal training data.
This dynamic approach makes RAG ideal for personalized applications where diverse or context-specific information is necessary. Moreover, RAG allows developers to maintain smaller, more efficient models, as the need to embed massive amounts of information within the model’s architecture is reduced, making it more scalable and resource-efficient across various domains. This combination of retrieval and generation represents a significant step forward in creating intelligent, real-time applications.
Below are some of my articles and tutorial on RAG.
- Implementing RAG using LangChain and SingleStore: A Step-by-Step Guide!
- Agentic RAG Using CrewAI & LangChain!
- Multimodal RAG Using LlamaIndex, Claude 3 and SingleStore!
RAG vs. Long Context Window
While both RAG and long-context LLMs enhance the ability of AI models to handle large volumes of data, they take different approaches. RAG pulls relevant information on demand, retrieving fresh content when needed, while long-context LLMs rely on extending their ability to “remember” more information in a single session. RAG excels in cases where external knowledge is required, while long-context windows are ideal when all relevant information is already available within a single document or conversation.
Here’s a comparison chart between Retrieval Augmented Generation (RAG) and a Long Context Window approach in LLMs, highlighting five key differences:

In summary, RAG integrates external knowledge retrieval to overcome memory limits, while long context windows try to extend what the model can “remember” within its internal capacity.
The Winner: Both [RAG and Long Context Window]
Long-context LLMs are great for tasks that require processing lengthy documents, but RAG shines when the AI needs to pull from diverse sources to generate accurate responses. As both technologies continue to evolve, they are more likely to complement each other rather than compete, with hybrid models emerging to leverage the best of both worlds.
BUT, the ultimate winning case can be using both — RAG and Long Context Window.
In the above video, you will see a tutorial on RAG application using LlamaIndex & Long Context Model Jamba-Instruct for enhanced AI applications.
Here is the complete notebook code.
GitHub - pavanbelagatti/RAG-And-Long-Context-Window-Tutorial
BTW, I recommend using SingleStore as your ultimate data platform as it supports all data types. You can use SingleStore not just as a vector database but for real-time analytics too.
Sign up to SingleStore and start using it for FREE.
Clap 👏 for the article if you liked this article. Thanks:)
Will Long-Context LLMs Make RAG Obsolete was originally published in Level Up Coding on Medium, where people are continuing the conversation by highlighting and responding to this story.
This content originally appeared on Level Up Coding - Medium and was authored by Pavan Belagatti
Pavan Belagatti | Sciencx (2024-09-12T16:02:01+00:00) Will Long-Context LLMs Make RAG Obsolete. Retrieved from https://www.scien.cx/2024/09/12/will-long-context-llms-make-rag-obsolete/
Please log in to upload a file.
There are no updates yet.
Click the Upload button above to add an update.