
This content originally appeared on Level Up Coding - Medium and was authored by Itsuki
AWS Glue Table from Dynamo JSON in S3 Two Ways

If you are reading this article, you are probably like me, looking for a solution to query DynamoDB with Athena.
There are couple approaches here.
One will be by using the AthenaDynamoDBConnector Lambda function.
This approach is simple and we can get Dynamo data in almost real time. However, there are some problems with it especially if we have a large amount of data. When Athena access DynamoDB, Read capacity unit (RCU) is used, and we may run into the following issues:
- RCU Stalled
- Data won’t load
- Effect to services that actually required access to the same DynamoDB Data
Also, it is not directly available in CDK and aws-sam.CfnApplication is not supported anymore.
If you want to try it out from the console, please feel free to check out my previous article here.
If you need to deploy the connector using CDK, try the code below
const dataBucket = new Bucket(this, 'EmotionDataBucket', {
removalPolicy: RemovalPolicy.RETAIN,
})
const lambdaRole = new Role(this, "EmotionVisualizerConnectorRole", {
roleName: "EmotionVisualizerConnectorRole",
assumedBy: new ServicePrincipal('lambda.amazonaws.com'),
managedPolicies: [
ManagedPolicy.fromAwsManagedPolicyName(
'service-role/AWSLambdaBasicExecutionRole'
),
],
})
lambdaRole.addToPolicy(new PolicyStatement({
actions: ['s3:ListAllMyBuckets'],
resources: ['*'],
}))
lambdaRole.addToPolicy(
new PolicyStatement({
actions: [
's3:GetObject',
's3:ListBucket',
's3:GetBucketLocation',
's3:GetObjectVersion',
's3:PutObject',
's3:PutObjectAcl',
's3:DeleteObject',
's3:GetLifecycleConfiguration',
's3:PutLifecycleConfiguration',
],
resources: [dataBucket.bucketArn, dataBucket.arnForObjects('*')],
})
)
table.grantReadWriteData(lambdaRole)
lambdaRole.addToPolicy(
new PolicyStatement({
actions: [
'athena:GetQueryExecution',
'glue:GetTableVersions',
'glue:GetPartitions',
'glue:GetTables',
'glue:GetTableVersion',
'glue:GetDatabases',
'glue:GetTable',
'glue:GetPartition',
'glue:GetDatabase',
// Allows Athena Query Explorer to show schema. Required on first run for Athena to discover schemas
// Can probably be commented out later to avoid oversharing data
'dynamodb:ListTables',
'dynamodb:DescribeTable',
'dynamodb:ListSchemas',
'dynamodb:Scan',
],
resources: ['*'],
})
)
const codeBucket = Bucket.fromBucketName(this, "EmotionConnectorCodeBucket", "awsserverlessrepo-changesets-1lsaqs4rvcm2")
new Function(this, " EmotionDynamoConnector", {
code: Code.fromBucket(codeBucket, "075198889659/arn:aws:serverlessrepo:us-east-1:292517598671:applications-AthenaDynamoDBConnector-versions-2023.42.1/4bde652b-0e5f-4205-ab25-5cdfd62e21fc"),
runtime: Runtime.JAVA_11,
handler: 'com.amazonaws.athena.connectors.dynamodb.DynamoDBCompositeHandler',
memorySize: 3008,
timeout: Duration.seconds(900),
environment: {
"disable_spill_encryption": 'false',
"spill_bucket": dataBucket.bucketName,
"spill_prefix": "athena-spill",
},
role: lambdaRole
})Anther way will be by using Glue which is what we will be taking a look at here.
The basic idea is to export the DynamoDB data to S3, create a Glue Table from it and query with Athena.
We will be creating our Glue resources using CDK here.
Export Dynamo Data
Open your Dynamo Table from the Console and do the following Two steps!
- Enable Point-in-time recovery for the table. For details on how to enable PITR, see Point-in-time recovery.
- Click on the Export to S3 Button and choose Full Report Under Exports and streams if you are doing it from the console. Or you can set up an EventBridge to trigger a Lambda to start the export Job.
You can find out more about Requesting a table export in DynamoDB here.
It is so simple that I will skip it and jump right into the Glue part.
Create Glue Table
As I have said in my title, we will be checking out 2 different approaches, one by creating the Table directly, and one from Glue Crawler. Each approach has its own pros and cons.
Table From Crawler
Here is CDK Code we can use to create the Crawler, assuming your dynamo JSON is in the AWSDynamoDB/xxx/data/ folder.
const dataBucket = new Bucket(this, 'EmotionDataBucket', {
removalPolicy: RemovalPolicy.RETAIN,
})
const databaseName = "my-database"
const prefix = "AWSDynamoDB/xxx/data/"
const crawlerRole = new Role(this, "EmotionCrawlerRole", {
roleName: "EmotionCrawlerRole",
assumedBy: new ServicePrincipal('glue.amazonaws.com'),
managedPolicies: [
ManagedPolicy.fromAwsManagedPolicyName(
'service-role/AWSGlueServiceRole'
),
],
})
crawlerRole.addToPolicy(new PolicyStatement({
effect: Effect.ALLOW,
actions: [
's3:GetObject',
"s3:PutObject"
],
resources: [`${dataBucket.bucketArn}/*`],
}))
const crawler = new CfnCrawler(this, "EmotionDataCrawler", {
databaseName: databaseName,
targets: {
s3Targets: [{
path: dataBucket.s3UrlForObject(`${prefix}`)
}]
},
role: crawlerRole.roleArn,
schemaChangePolicy: {
updateBehavior: "UPDATE_IN_DATABASE"
},
schedule: undefine
})We can then run the crawler to create the Glue Table, either from the Console, by using SDKs, by using CLI, or by setting the expression for the schedule so that it runs automatically.
Couple things I would like to point out here.
- databaseName: It does not have to be an exisitng Glue Database. If it does not exist, it will be created automatically when we first run the crawler.
- prefix = "AWSDynamoDB/xxx/data/" : The xxx part will be different every time the export job is performed. Then how can we create one Crawler (or Table in the next section) that works for all exported data? To solve this, we can create an S3 Triggered Lambda that moves the dynamo JSON to a specific folder, for example, processed/ when the export job finishes, and use that folder as the s3Target when creating the crawler or the table. Here will be CDK for creating the Lambda and the S3EventSource. Note that for the source, we are filtering based on suffix: "manifest-files.json" so that the Lambda is only triggered ONCE, and will only be triggered on JOB FINISH!
const exportFinishLambda = new RustFunction(this, 'ExportFinishLambda', {
// Path to the root directory.
manifestPath: join(__dirname, '..', '..', 'path_to_Cargo.toml/')
});
exportFinishLambda.addEventSource(new S3EventSource(dataBucket, {
events: [EventType.OBJECT_CREATED],
filters: [{
suffix: "manifest-files.json"
}]
}))
dataBucket.grantReadWrite(exportFinishLambda)Table Directly
Here is how we can create the Table directly, assuming that our Dynamo Table contains only one column event_id of type String.
const glueTable = new CfnTable(this, "EmotionDatatable", {
databaseName: databaseName,
catalogId: this.account,
tableInput: {
name: "my_table",
parameters: {
"classification": "json"
},
storageDescriptor: {
columns: [
{
"name": "item",
"type": "struct<event_id:struct<S:string>>"
}
],
inputFormat: "org.apache.hadoop.mapred.TextInputFormat",
outputFormat: "org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat",
serdeInfo: {
serializationLibrary: "org.openx.data.jsonserde.JsonSerDe",
parameters: {
"paths": "item"
}
},
location: dataBucket.s3UrlForObject(`${prefix}`)
},
},
})One Note here. catalogId will simply be the accountId , don’t try to create a CfnCatalog, it will not work!
Comparison
Crawler pros
- JSON schema is detected automatically
- No need to configure table parameters
Crawler cons
- Unknown Table Name. It will most likely be the folder name containing the data. However, this is not guaranteed and there is no way to configure it!
- Need to be ran manually or programmatically after export finish to update the Table with the new Data.
Table pros
- Table name can be specified.
- Automatically update itself on updates in the target s3 location
Table cons
- Manually defined (and fixed) schema and parameters. If you have no idea on what the schema, especially the type for the column, should be, simply create a crawler from the console, run it once to create the table, copy and paste the schema generated!
Regardless of which approach you choose, I will strongly recommend to try it out once using the console to confirm all the parameters we need to configure.
Query Using Athena
Now that we have our Glue Table, we are pretty much done for this article!
But! Just as a little bonus, let me share with you on how we can query our data because it is a little different from regular cases.
If we simply run
SELECT * FROM "AwsDataCatalog"."my-database"."my_table" limit 10;
we will see somthing like following, where all columns of the Dynamo Table are nested within the item.
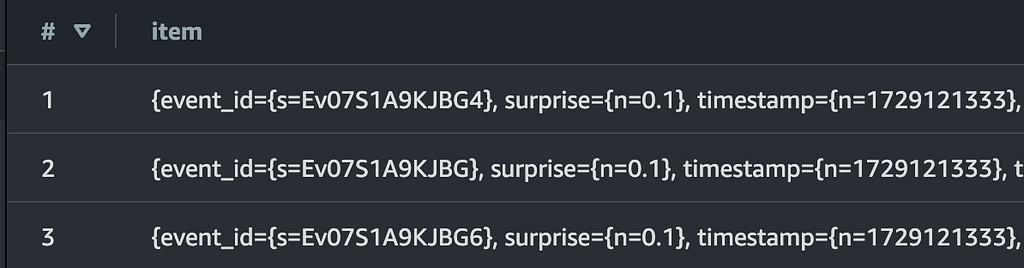
Here is what we can do instead.
SELECT
Item.event_id.S AS event_id
FROM "AwsDataCatalog"."my-database"."my_table" limit 10;
And now we get something more processable and readable!

Thank you for reading!
That’s all I have for today!
Happy table-ing!
AWS Glue Table from Dynamo JSON in S3 2 Ways was originally published in Level Up Coding on Medium, where people are continuing the conversation by highlighting and responding to this story.
This content originally appeared on Level Up Coding - Medium and was authored by Itsuki
Itsuki | Sciencx (2024-10-19T13:15:07+00:00) AWS Glue Table from Dynamo JSON in S3 2 Ways. Retrieved from https://www.scien.cx/2024/10/19/aws-glue-table-from-dynamo-json-in-s3-2-ways/
Please log in to upload a file.
There are no updates yet.
Click the Upload button above to add an update.