
This content originally appeared on Level Up Coding - Medium and was authored by Pavan Belagatti

In the world of AI, Retrieval-Augmented Generation (RAG) pipelines have become essential for delivering accurate and contextually relevant responses. This blog will explore how to build RAG pipelines quickly and efficiently using Vectorize, a tool designed to streamline the process.
Introduction to RAG Pipelines
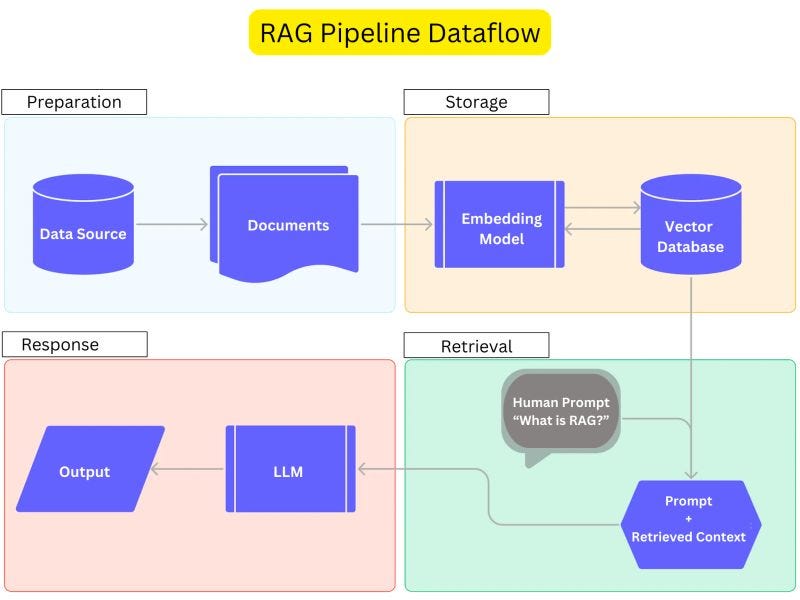
Retrieval-Augmented Generation (RAG) pipelines represent a significant advancement in the way AI systems generate responses. At their core, RAG pipelines combine the strengths of retrieval-based mechanisms with generative models, enabling systems to access vast amounts of information while providing contextually relevant and coherent answers.
The architecture of RAG pipelines allows for a seamless integration of retrieval and generation processes. This means that rather than relying solely on pre-trained models, RAG pipelines can pull in fresh data to enhance the quality of responses. This is particularly important in dynamic fields where information is continuously evolving.
Key Components of RAG Pipelines
- Retrieval Mechanism: This component fetches relevant documents or data based on user queries.
- Generation Model: After retrieving data, the generation model synthesizes this information into a coherent response.
- Feedback Loop: Continuous learning from user interactions helps improve the accuracy and relevance of future responses.
Evolution of RAG Pipelines

The journey of RAG pipelines began with simple retrieval systems that relied on keyword matching. As AI technology advanced, so did the complexity of these systems. The introduction of embeddings marked a pivotal moment, allowing for more sophisticated retrieval methods that understood the context behind queries.
With the emergence of advanced RAG models, such as multimodal RAG, systems began to integrate various data types, including text, images, and audio. This evolution has paved the way for more nuanced and comprehensive responses, enabling AI to understand and generate content across multiple formats.
From Traditional to Agentic RAG
Today’s RAG pipelines are not just about retrieving and generating information; they are increasingly becoming agentic. This means they can autonomously plan and execute complex tasks by breaking them down into manageable subtasks. This shift is transforming how we interact with AI, making it a more powerful tool for problem-solving.
The Need for a Robust Tool
Despite the advancements in RAG pipeline technology, the development of these systems remains challenging. Many practitioners struggle with the intricacies involved in building production-ready pipelines. The need for a robust tool that simplifies this process is more critical than ever.
A well-designed platform can streamline the complexities of RAG pipelines, allowing users to focus on creating effective applications rather than getting bogged down in technical details. This is where tools like Vectorize come into play, offering an intuitive interface and powerful features to build and evaluate RAG pipelines efficiently.
Vectorize
Vectorize is a groundbreaking platform designed to facilitate the creation of RAG pipelines. It provides users with a comprehensive set of tools that simplify the building process while ensuring high-quality outputs. One of the standout features of Vectorize is its ability to conduct RAG evaluations, enabling users to assess different embedding models and retrieval strategies.

By leveraging data-driven approaches, Vectorize helps users identify the most effective configurations for their specific needs. This functionality is crucial for optimizing the performance of RAG pipelines and ensuring that they deliver accurate and relevant results.
Features of Vectorize
- Intuitive Dashboard: Users can easily navigate through the platform to set up and manage their RAG pipelines.
- Evaluation Tools: Conduct RAG evaluations to determine the best embedding models and retrieval approaches.
- Integration Capabilities: Connect with various vector databases and AI platforms to enhance functionality.
Creating Your Vectorize Account
Getting started with Vectorize is a straightforward process. Users can create a free account by visiting the Vectorize website. Once registered, you will have the opportunity to create your organization, which serves as the foundation for building your RAG pipelines.
The onboarding process is designed to be user-friendly, guiding you through the initial setup. After creating your organization, you will access the dashboard, where you can begin exploring the features and tools available for building RAG pipelines.
Steps to Create Your Account
- Visit the Vectorize website.
- Click on the “Sign Up” button to create a new account.
- Fill in the required details to set up your organization.
- Confirm your email address to activate your account.
- Log in to the dashboard to start building your RAG pipelines.
Running a Sample RAG Evaluation
Once your Vectorize account is set up, you can run a sample RAG evaluation to see the platform in action. This process involves selecting sample documents to vectorize and evaluating how different configurations affect the outcomes.
The evaluation will guide you through selecting an embedding model, chunking strategy, and vector database. By analyzing the results, you can gain insights into which configurations yield the best performance for your RAG applications.
Steps for Running Your Sample Evaluation
- Select a set of sample documents to vectorize.
- Choose the embedding model that best suits your needs.
- Define the chunking strategy for data processing.
- Run the evaluation and analyze the results to identify the winning approach.
- Utilize the insights gained to refine your RAG pipeline configurations.
The complete step-by-step walkthrough video is here for you.
Understanding RAG Evaluation Metrics
To optimize RAG pipelines, understanding evaluation metrics is crucial. These metrics provide insights into the effectiveness of retrieval and generation processes.
Key metrics include:
- Precision: Measures the accuracy of retrieved documents. It indicates how many of the retrieved documents are relevant.
- Recall: Represents the ability of the system to retrieve all relevant documents. A high recall means the system finds most or all relevant items.
- F1 Score: The harmonic mean of precision and recall, providing a balance between the two. This score is particularly useful when the class distribution is uneven.
- NDCG (Normalized Discounted Cumulative Gain): Evaluates the ranking quality of results. High NDCG scores indicate that more relevant documents appear higher in the search results.
Using these metrics, developers can fine-tune their RAG pipelines, ensuring they deliver high-quality, relevant responses.
Exploring the RAG Sandbox

The RAG Sandbox is a powerful feature that allows users to test and refine their RAG pipelines. It provides an end-to-end testing environment where different vector search indexes and language models can be compared.
In the RAG Sandbox, users can:
- Run Simulations: Test various configurations to identify the most effective settings for their specific use cases.
- Ask Questions: Directly interact with the system by posing questions and observing how well the RAG pipeline retrieves and generates responses.
- Analyze Results: Review the relevance scores and context retrieved for each question to assess the pipeline’s performance.
This interactive environment is essential for iterating on RAG pipeline designs, ensuring they meet the users’ needs effectively.

Building Advanced RAG Pipelines
Creating advanced RAG pipelines involves integrating multiple components and configurations. This process ensures that the pipeline can handle complex queries and provide accurate responses.
Key steps to building advanced RAG pipelines include:
- Choosing the Right Source Connectors: Selecting appropriate data sources, such as web crawlers or APIs, to gather relevant information.

- Utilizing Multiple Embedding Models: Experimenting with various embedding models to enhance retrieval accuracy.
- Implementing Hybrid Search Strategies: Combining different search techniques, such as keyword matching and semantic search, for improved results.
- Configuring Feedback Mechanisms: Establishing systems to learn from user interactions, which can refine the retrieval and generation processes over time.
By systematically addressing each of these areas, developers can build robust RAG pipelines capable of tackling a wide range of queries.
Integrating SingleStore as Your Vector Database
SingleStore is an excellent choice for a vector database in RAG pipelines. It offers high performance and scalability, making it suitable for handling large datasets.

To integrate SingleStore, follow these steps:
- Create a SingleStore account and set up your workspace.
- Define your database and establish the necessary schemas to store vectorized data.
- Connect SingleStore to your RAG pipeline through the provided integration tools in Vectorize.
- Ensure that the vectorization process populates the SingleStore database with relevant embeddings.

This integration allows for efficient data retrieval and management, enhancing the overall performance of your RAG pipelines.
Conclusion: The Future of RAG Pipelines
The future of RAG pipelines looks promising, with ongoing advancements in AI technologies. As systems become more agentic, the ability to autonomously plan and execute tasks will revolutionize how we interact with AI.
Tools like Vectorize simplify the development of RAG pipelines, making it accessible for practitioners at all levels. By leveraging robust vector databases like SingleStore, the potential for creating high-performance applications expands significantly.
As we continue to innovate, the integration of RAG pipelines into various domains will enhance our ability to retrieve and generate information accurately. The journey of RAG pipelines is just beginning, and the possibilities are limitless.
A Practical Approach to Building Advanced RAG Pipelines with Confidence! was originally published in Level Up Coding on Medium, where people are continuing the conversation by highlighting and responding to this story.
This content originally appeared on Level Up Coding - Medium and was authored by Pavan Belagatti
Pavan Belagatti | Sciencx (2024-11-05T17:50:11+00:00) A Practical Approach to Building Advanced RAG Pipelines with Confidence!. Retrieved from https://www.scien.cx/2024/11/05/a-practical-approach-to-building-advanced-rag-pipelines-with-confidence/
Please log in to upload a file.
There are no updates yet.
Click the Upload button above to add an update.