
This content originally appeared on Level Up Coding - Medium and was authored by Gumparthy Pavan Kumar

Source: Illustration
Task Scheduling: A programming mechanism for defining when and how tasks should run automatically at specified times or intervals, without user intervention.
Have you ever wondered how apps send notifications on time, clean up old data automatically, or manage background tasks without breaking a sweat? That’s task scheduling in action!
Task scheduling helps you automate repetitive tasks, manage workflows, and keep systems running smoothly. As developers, it’s something we often handle in our projects— whether it’s sending emails, cleaning up logs, or optimizing system performance.
But here’s the catch: even though it sounds simple, implementing task scheduling the right way can be tricky. Missteps can lead to crashes, slow systems, or even bugs in production.
In this post, I’ll walk you through some common pitfalls and smart tricks that can help you master task scheduling in Spring Boot.
To illustrate the process, let’s consider a use case where we send promotional emails to all registered users. Here’s a simplified schema for the USER table:

Note: This schema is for development purposes only. In a production environment, the schema would be more complex and optimized for scalability and security.
For the sake of simplicity, we’ll proceed with this structure, which contains basic user details.
Here is the code snippet that we usually see developers write in Spring Boot:
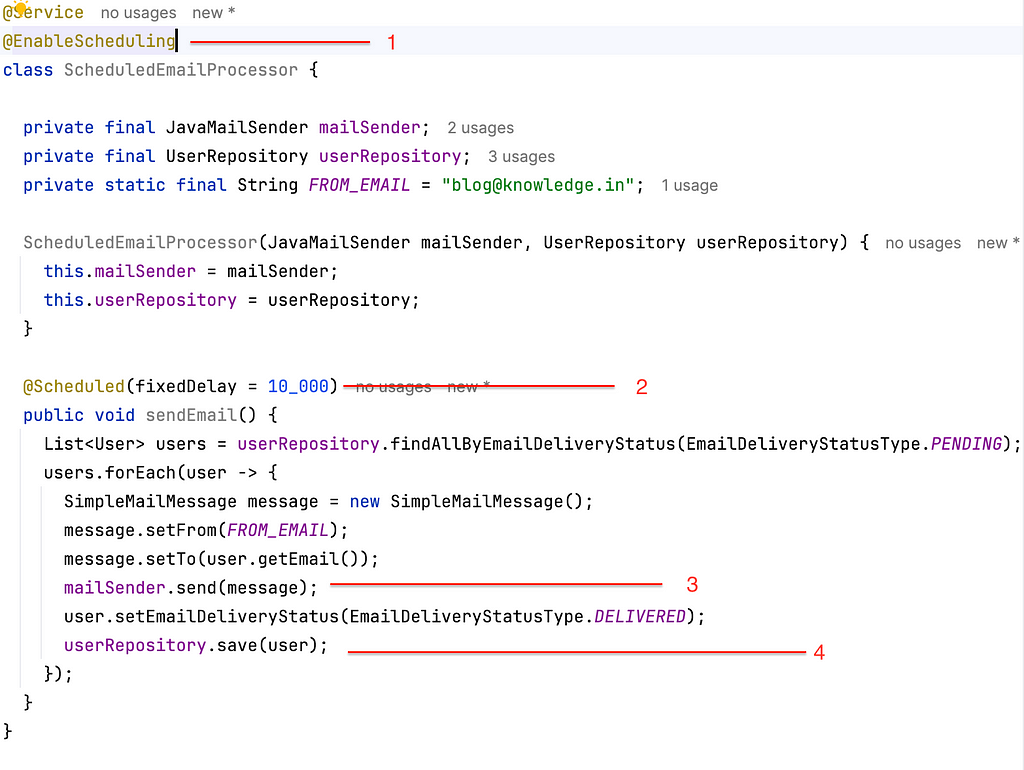
Although the code works, it has six subtle pitfalls that are often overlooked, as outlined below:
- Data Consistency
- Limiting the No. of results we process
- Programmatic Transaction Management
- Locking
- Skip-locking query hint
- Batch inserts and updates of Hibernate for more performance
1. Data Consistency
Ensuring data consistency is critical in any system, especially when tasks fail mid-process. For example, what happens if your system crashes after sending an email but before updating the database? This could leave your data in an inconsistent state.
One way to address this is by leveraging ACID properties in relational systems. By ensuring that every operation in a transaction is atomic, consistent, isolated, and durable, you can prevent partial updates.
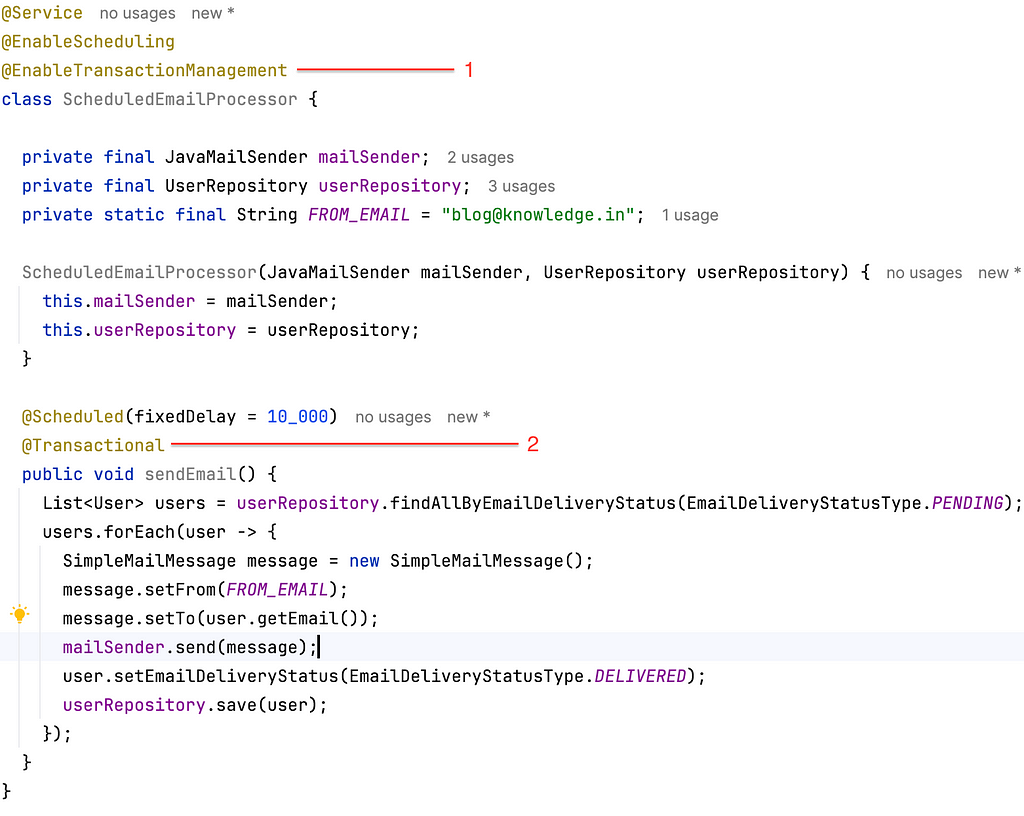
But is this approach efficient in terms of memory? Let’s explore.
2. Memory Efficiency
Loading all users into memory for processing can lead to errors like OutOfMemoryError, especially when dealing with large datasets. A better approach is to process data in chunks.
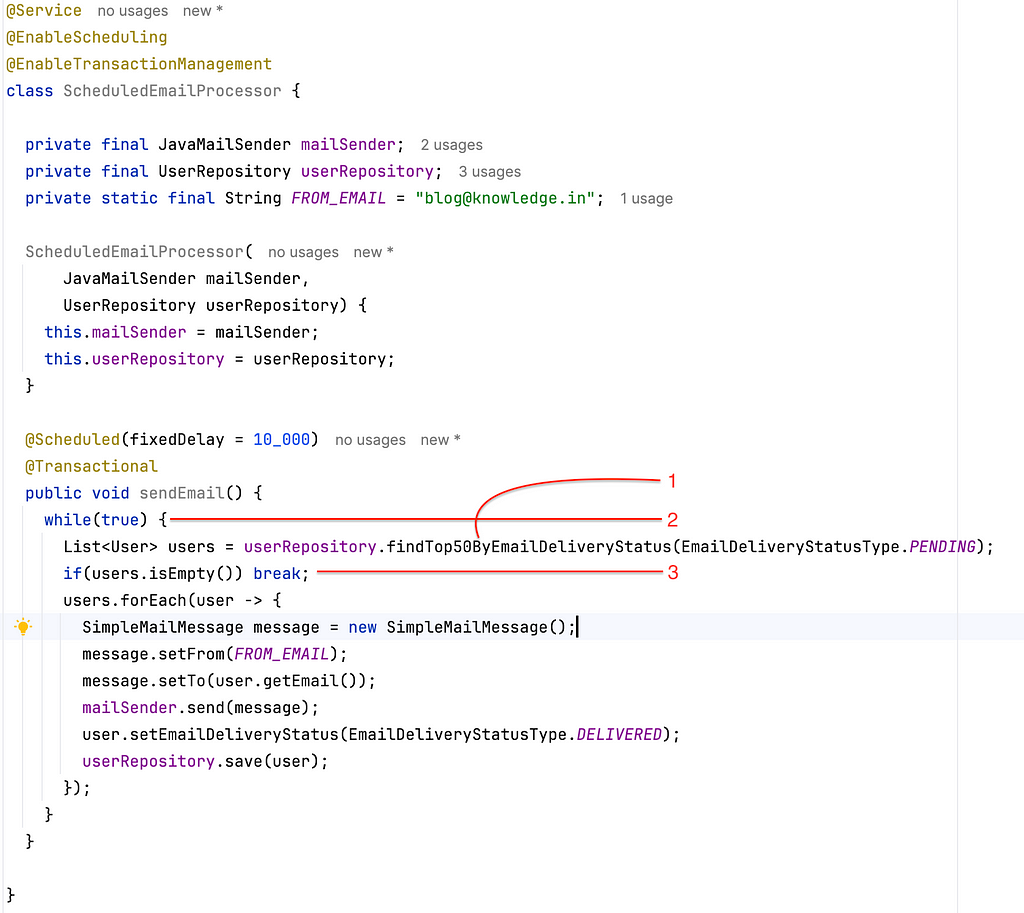
So this change should solve OutofMemoryError? Right?
Well, it is not the case because of how Transactions are managed in JPA.
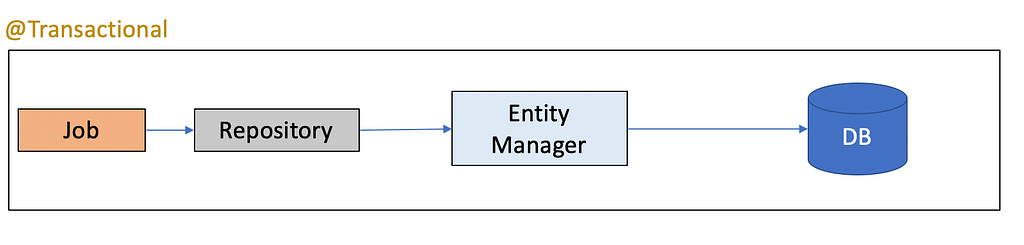
The reference to objects is not cleaned by the Garbage Collector because the reference is still held by the entity manager in its first-level cache, which is the reason why likely you see an OutOfMemoryError. Please check the below source for more details:
An entity gets detached when you close the persistence context. That typically happens after a request got processed. Then the database transaction gets committed, the persistence context gets closed, and the entity object gets returned to the caller. The caller then retrieves an entity object in the lifecycle state detached.
Source: https://thorben-janssen.com/entity-lifecycle-model/
So how can we do that?
3. Programmatic Transaction management
Switching from declarative transactions to programmatic transactions can provide greater control over how and when data is committed. Spring Boot’s TransactionTemplate bean is a powerful tool for this.
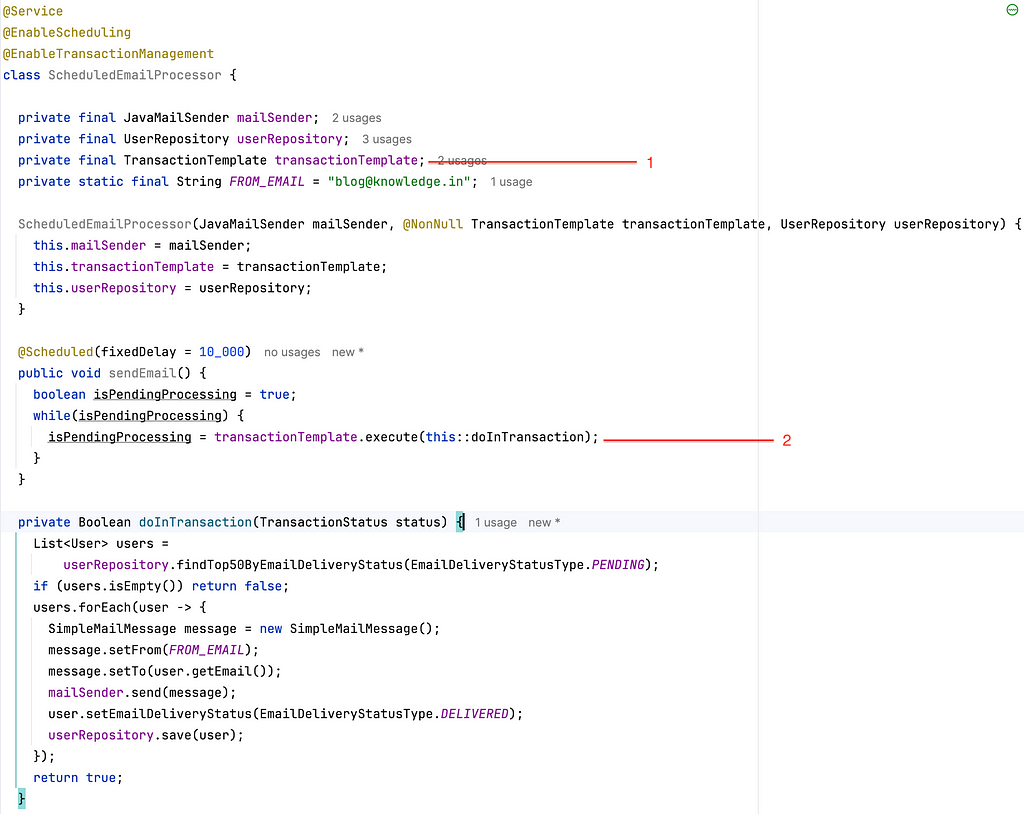
While this works well on a single-node machine, running in a cluster introduces new challenges. Without proper coordination, multiple nodes might process the same chunk, leading to data corruption or performance bottlenecks.
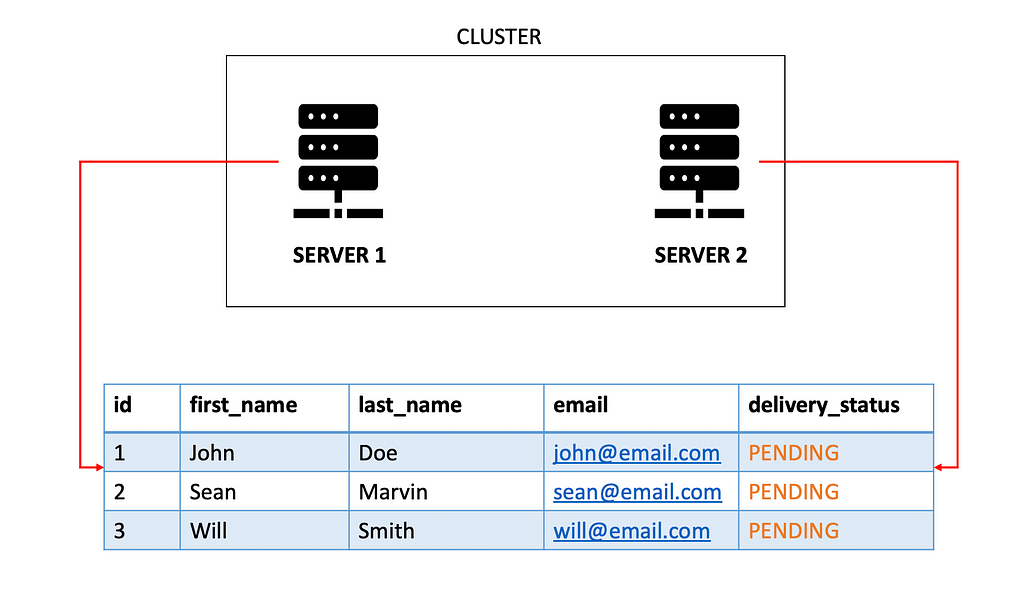
You cannot use the synchronized keyword in Java, as the JVMs are completely different. One possibility is to use Distributed Locking, which is out of the scope of this article.
For simplicity, let us stick to having a multi-node cluster for processing with a shared database.
With that alignment! Let’s look at how we can handle this.
4. Locking
To maintain consistency in a multi-node cluster, you need a locking mechanism that ensures only one node processes a specific chunk of data at a time. Relational databases offer built-in support for this through row-level locking. With JPA the configuration is much more simple:
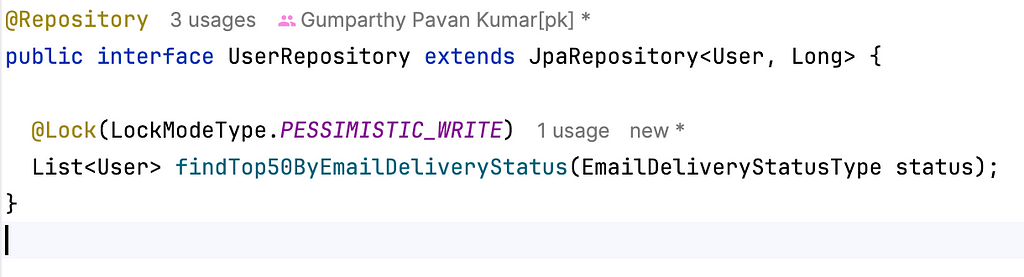
The generated SQL query will look like:
select u1_0.id, u1_0.created_by, u1_0.created_on,
u1_0.email, u1_0.email_delivery_status,
u1_0.first_name, u1_0.last_modified_by,
u1_0.last_modified_on, u1_0.last_name
from
cd_users u1_0
where
u1_0.email_delivery_status='PENDING'
limit
? for update --> LOCK
This approach ensures high availability but introduces a new challenge: one node may spend a long time waiting to acquire a lock, only to find that another node has already processed the data and updated its status. In such cases, the initial node re-evaluates the query and skips processing, which can occasionally lead to Deadlocks.
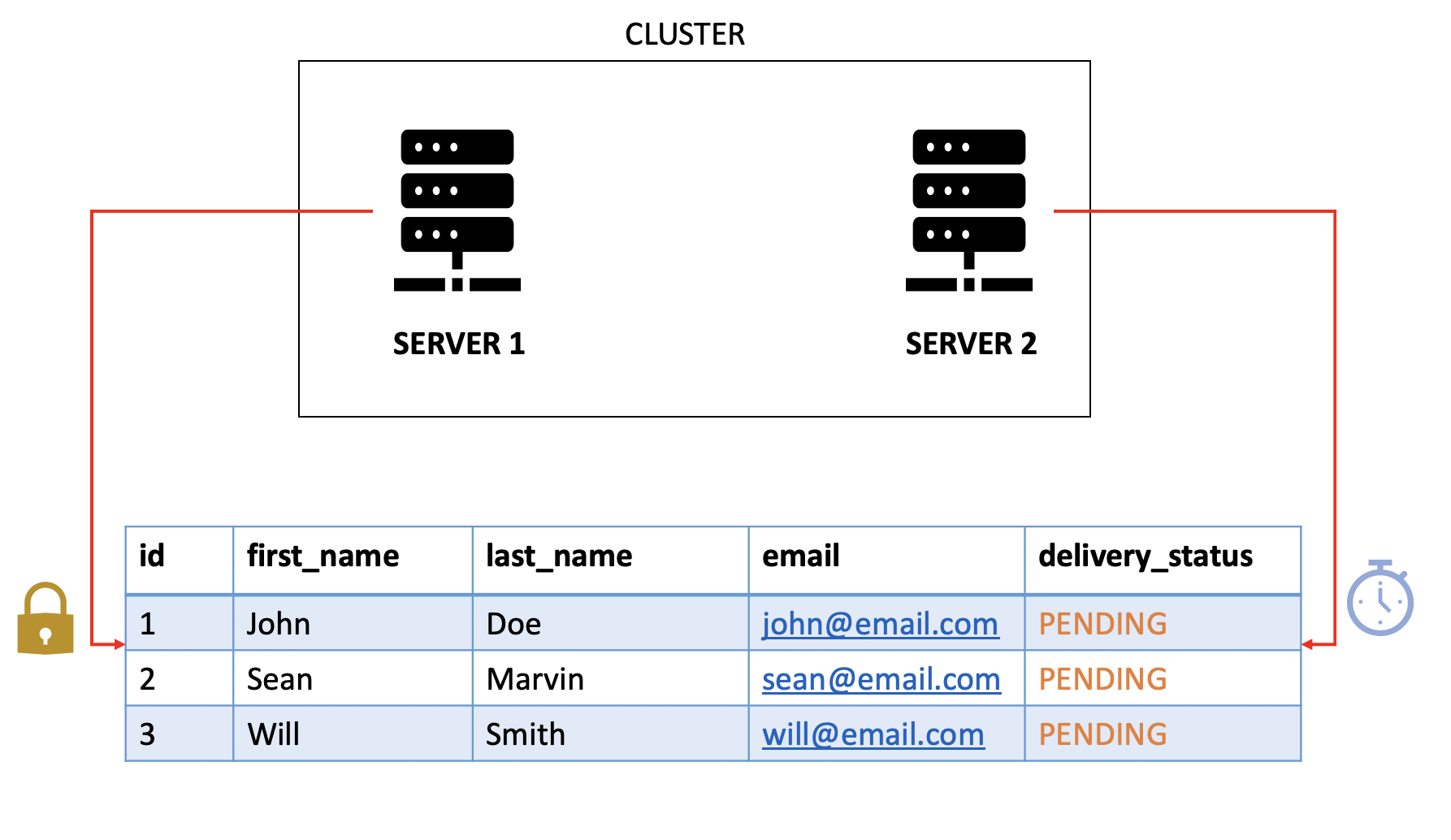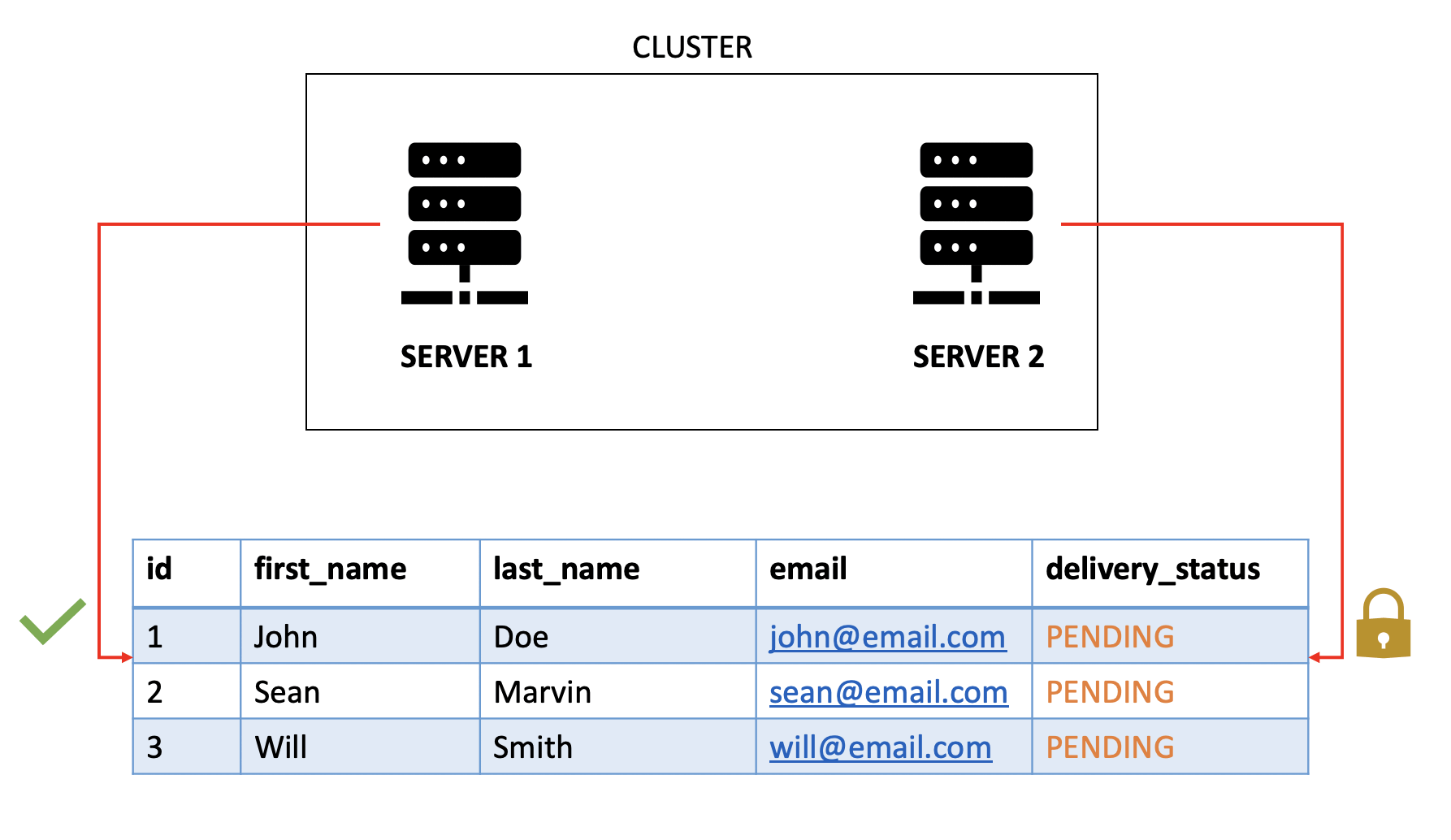
Which means in any given time only the node acquired the lock will process and other nodes will be idle, just to skip the row after the acquired node releases the lock.
Can we do this better to get more throughput?
5. Skip-locking query hint
A locking read that uses SKIP LOCKED never waits to acquire a row lock. The query executes immediately, removing locked rows from the result set.
This technique is generally preferred in Queue processing when concurrent sessions are involved
Source: MySQL
This way we distribute the processing workload with all the available processors offering high throughput thus scalability.
Skip Lock Query hint in JPA for MySQL:
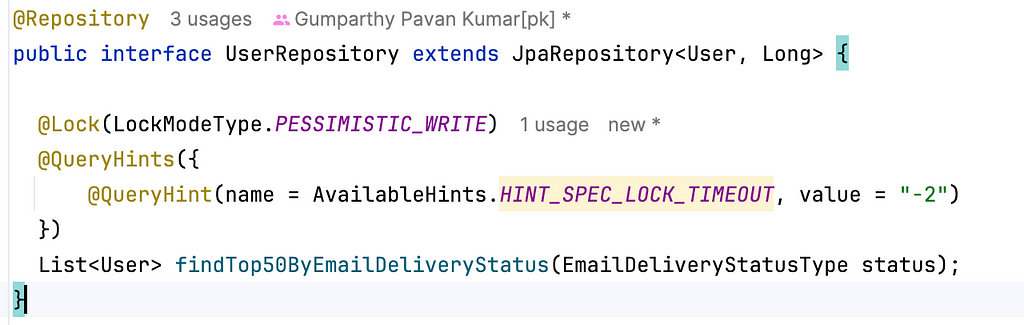
The Generated SQL query looks like follows:
select u1_0.id, u1_0.created_by, u1_0.created_on,
u1_0.email, u1_0.email_delivery_status,
u1_0.first_name, u1_0.last_modified_by,
u1_0.last_modified_on, u1_0.last_name
from
cd_users u1_0
where
u1_0.email_delivery_status=?
limit
? for update skip locked
This trick can make the solution scalable, However, is it performant? Let’s explore.
6. Batch inserts and updates of Hibernate for more performance
If you check the hibernate SQL logs you would identify something similar to this:
update cd_users set created_by=?,created_on=?,email=?,email_delivery_status=?,first_name=?,last_modified_by=?,last_modified_on=?,last_name=? where id=?
update cd_users set created_by=?,created_on=?,email=?,email_delivery_status=?,first_name=?,last_modified_by=?,last_modified_on=?,last_name=? where id=?
This query is executed for every record and is proportional to no. of records fetched. To fix this we can instruct JDBC driver to batch such statements to get better performance.
Here’s how you can configure it in JPA:
spring.jpa.properties.hibernate.jdbc.batch_size=50 # Change according to fetch size
spring.jpa.properties.hibernate.order_inserts=true
spring.jpa.properties.hibernate.order_updates=true
Wrapping It Up
By tackling these six challenges, you can build efficient and reliable task scheduling in Spring Boot. From ensuring data consistency to optimizing memory usage, locking strategies, and batching updates, these tricks will save you headaches and make your applications shine.
What’s Next?
Of course, there’s more to explore — handling network latency, retrying failed tasks, or dealing with external system downtime. But these are topics for another day.
Let’s Chat!
Thanks for reading! I hope these tips help you level up your task scheduling skills. If you’ve got any other cool tricks or questions, drop a comment below — I’d love to hear from you! 😊
For more detailed explanations and examples, check out the links below. They dive deeper into the topics we discussed and are highly recommended for a closer look:
References:
- https://www.youtube.com/watch?v=ghpljMg8Ecc
- https://medium.com/predictly-on-tech/spring-data-jpa-batching-using-streams-af456ea611fc
- https://github.com/spring-projects/spring-data-jpa/issues/3295
- https://dev.mysql.com/doc/refman/8.4/en/
- https://docs.spring.io/spring-boot/appendix/application-properties/index.html
Mastering Task Scheduling: Essential Tricks for Senior Spring Boot Developers was originally published in Level Up Coding on Medium, where people are continuing the conversation by highlighting and responding to this story.
This content originally appeared on Level Up Coding - Medium and was authored by Gumparthy Pavan Kumar
Gumparthy Pavan Kumar | Sciencx (2025-01-19T20:28:12+00:00) Mastering Task Scheduling: Essential Tricks for Senior Spring Boot Developers. Retrieved from https://www.scien.cx/2025/01/19/mastering-task-scheduling-essential-tricks-for-senior-spring-boot-developers/
Please log in to upload a file.
There are no updates yet.
Click the Upload button above to add an update.