
This content originally appeared on Level Up Coding - Medium and was authored by Poorshad Shaddel
PostgreSQL’s TOAST manages large data values. This article explains TOAST, its supported data types, storage strategies (PLAIN, EXTERNAL, EXTENDED, MAIN), and how to choose the best strategy for optimal database performanceWhat you are going to read
- What is TOAST
- Which Data Types are TOAST-able?
- TOAST Strategies
- How to Choose the Strategy?
- Conclusion

What is TOAST?
Before getting to what it stands for, let’s define it in simple words. Postgres stores data in fixed size units called Page. The fixed size is 8kB. each feature is there to solve a problem and here is the problem:
What if we have a row that exceeds a page size? A table called posts, which keeps the blog post could exceed 8kB. what should we do? the answer to this question is TOAST. it stands for The Oversized-Attribute Storage Technique. the short answer would be through compression or making a pointer to another table which we know as out-of-line storage.
You probably already know that you can have fields in Postgres as big as 1GB :)
Which Data Types are TOAST-able?
First of all Data Types which cannot produce large field values are not TOAST-able.
These are Non-TOAST-able Data Types:
- Numeric and Serial Types(int2, int4, int8,…)
- Floating-Point Types(float4, float8)
- Boolean
- Date/Time Types
- Enumerated Types
- Network Address Types
If a Type wants to be TOAST-able, it should have variable-length representation, usually the first 4 bytes.
Here is the list of TOAST-ble Data Types
- Textual and Binary Large Objects(text, varchar, char(n))
- JSON and XML(json, jsonb, xml)
- Geometric Data Types(box, circle, line, …)
- Array Data Types
TOAST Strategies
We have 4 different strategies: PLAIN, EXTENDED, EXTERNAL, MAIN.
Before explaining them let’s create a table and also learn how to check the TOAST strategies of each column.
Create a sample table:
CREATE TABLE posts (
id SERIAL PRIMARY KEY,
title VARCHAR(255) NOT NULL,
body TEXT NOT NULL,
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP
);
the TOAST strategies of columns are stored in pg_attribute table, we can use our table name posts to get only data of it:
SELECT * FROM pg_attribute WHERE attrelid = 'posts'::regclass;
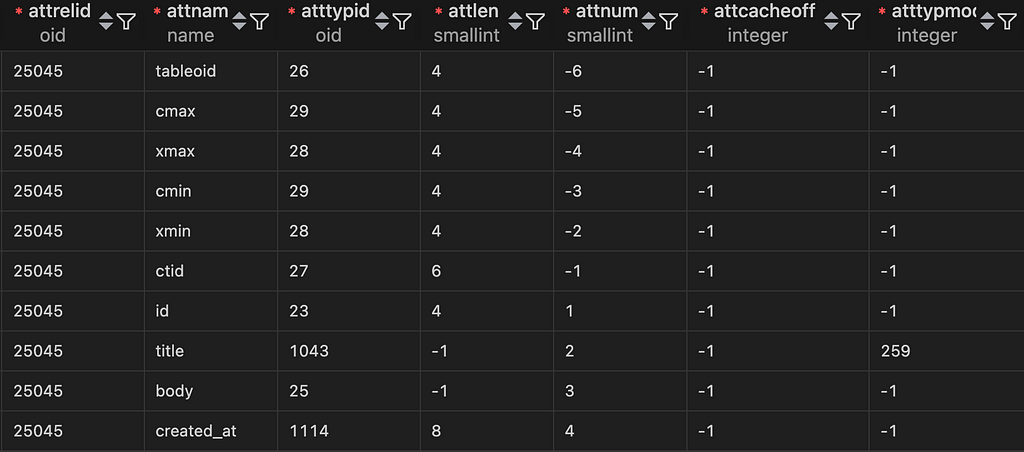
A lot of this data is not relevant to us. Also there are hidden system columns listed as well. We can ignore them, and also map attstorage to the strategy name:
SELECT
'posts'::regclass AS table_name,
a.attname AS column_name,
CASE
WHEN a.attstorage = 'p' THEN 'PLAIN'
WHEN a.attstorage = 'e' THEN 'EXTERNAL'
WHEN a.attstorage = 'm' THEN 'MAIN'
WHEN a.attstorage = 'x' THEN 'EXTENDED'
ELSE 'UNKNOWN'
END AS toast_strategy
FROM
pg_attribute a
WHERE
a.attrelid = 'posts'::regclass
AND a.attnum > 0 -- exclude system columns
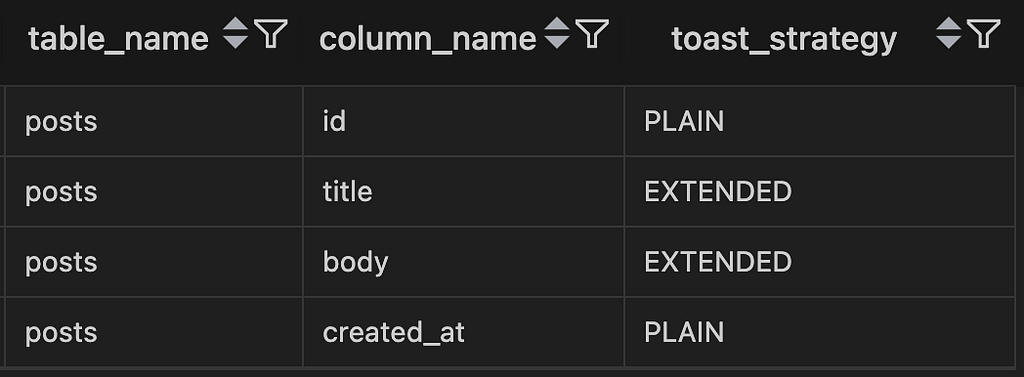
As you can see p stands for plain strategy.
We get a straightforward result:
We can also make a PSQL View(posts_toast) to make it simpler for the next steps:
CREATE VIEW posts_toast AS
SELECT
'posts'::regclass AS table_name,
a.attname AS column_name,
CASE
WHEN a.attstorage = 'p' THEN 'PLAIN'
WHEN a.attstorage = 'e' THEN 'EXTERNAL'
WHEN a.attstorage = 'm' THEN 'MAIN'
WHEN a.attstorage = 'x' THEN 'EXTENDED'
ELSE 'UNKNOWN'
END AS toast_strategy
FROM
pg_attribute a
WHERE
a.attrelid = 'posts'::regclass
AND a.attnum > 0 -- exclude system columns
AND NOT a.attisdropped;
We still get the previous result.
PLAIN
As we see in the result field Id and created_at have plain strategy. These were in the list of non-TOAST-able fields. This strategy is for non-TOAST-ble fields, and data would be stored without any compression or out-of-line storage.
EXTENDED
As we have seen in the result, our 2 TOAST-ble columns are using this strategy. This is the default for TOAST-able columns!
EXTENDED strategy allows for both Compression and Out of Line Storage.
It first tries to compress, if it cannot fit it, it stores data somewhere else.
The Postgres Limit TOAST_TUPLE_THRESHOLD is 2kB by default, so if it exceeds that number we should see some TOAST actions. Also it means that postgres rather store at 4 Tuples in a page(8kB).
Let’s insert a field:
INSERT INTO posts (title, body)
VALUES ('Post with 2kB body', repeat('a', 2048));
The TOAST data is stored in a table with this pattern:
pg_toast.pg_toast_<OID>
To get the oid we can use pg_class table and build the pattern:
SELECT 'pg_toast.pg_toast_' || (SELECT oid FROM pg_class WHERE relname = 'posts') AS toast_table_name
FROM pg_class
WHERE relname = 'posts';
Now we have the name of TOAST table: pg_toast.pg_toast_25045
SELECT * FROM pg_toast.pg_toast_25045;
The table is empty! Even if we insert a field with size of 4kB:
INSERT INTO posts (title, body)
VALUES ('Post with 4kB body', repeat('a', 4096));
The reason is very simple, when we repeat a it is compressible.
If we check the size:
SELECT
pg_column_size(body) AS body_size_after_compression
FROM
posts
WHERE
title = 'Post with 4kB body';
The result is 56 Bytes
Which shows that compression was done.
Let’s insert a field which is not compressible and exceeds the amount.
First we need a random string generator function:
CREATE OR REPLACE FUNCTION random_string(length INTEGER) RETURNS TEXT AS $$
DECLARE
chars TEXT := 'ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789!@#$%^&*()_+-=[]{}|;:,.<>?';
result TEXT := '';
i INTEGER := 0;
BEGIN
IF length < 0 THEN
RAISE EXCEPTION 'Length cannot be negative';
END IF;
FOR i IN 1..length LOOP
result := result || substr(chars, floor(random() * length(chars) + 1)::INTEGER, 1);
END LOOP;
RETURN result;
END;
$$ LANGUAGE plpgsql;
Now let’s clean the table and then insert one 4kB text field:
DELETE FROM posts;
INSERT INTO posts (title, body)
VALUES ('Post with 4kB random body', random_string(4096));
Now if we get the size of column:
SELECT pg_column_size(body) AS body_size_after_compression from posts WHERE title = 'Post with 4kB random body';
It is 4096.
Let’s check out the original table:
SELECT * FROM posts;

Our random string begins TR) . Now let’s checkout our TOAST table:
SELECT * FROM pg_toast.pg_toast_25045;

This data is chunked and stored in another table. Our original table only keeps some pointers to these chunks.
EXTERNAL
This strategy only allows out-of-line storage. you cannot compress anything.
Let’s change the TOAST strategy of our field body and see.
ALTER TABLE posts ALTER COLUMN body SET STORAGE EXTERNAL;
Now lets insert a row:
INSERT INTO posts (title, body)
VALUES ('Post with 4kB body', repeat('a', 4096));
Now let’s see the column size:
SELECT pg_column_size(body) AS body_size_after_compression from posts WHERE title = 'Post with 4kB body';
The result is 4096 Bytes, in the extended strategy such a field had size of 56 Bytes .
Let’s check the pg_toast table:
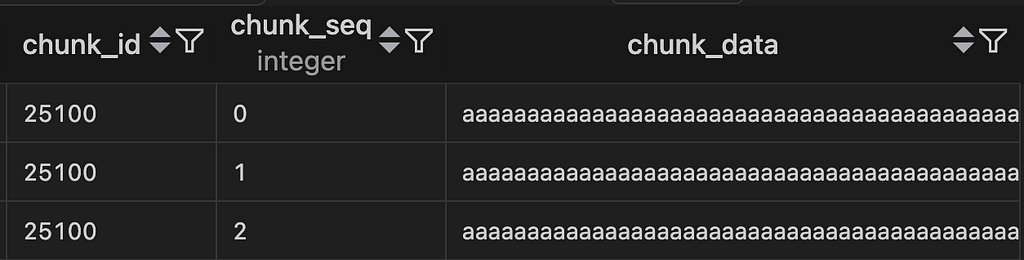
Is it a waste of Storage to use External Strategy?
Could be, but the benefit is that you can ask for a substring much faster than when you have compressed a string.
Main
Only compression is allowed. then what happens if even with the compression it cannot fit it? it simply stores it out-of-line storage :)
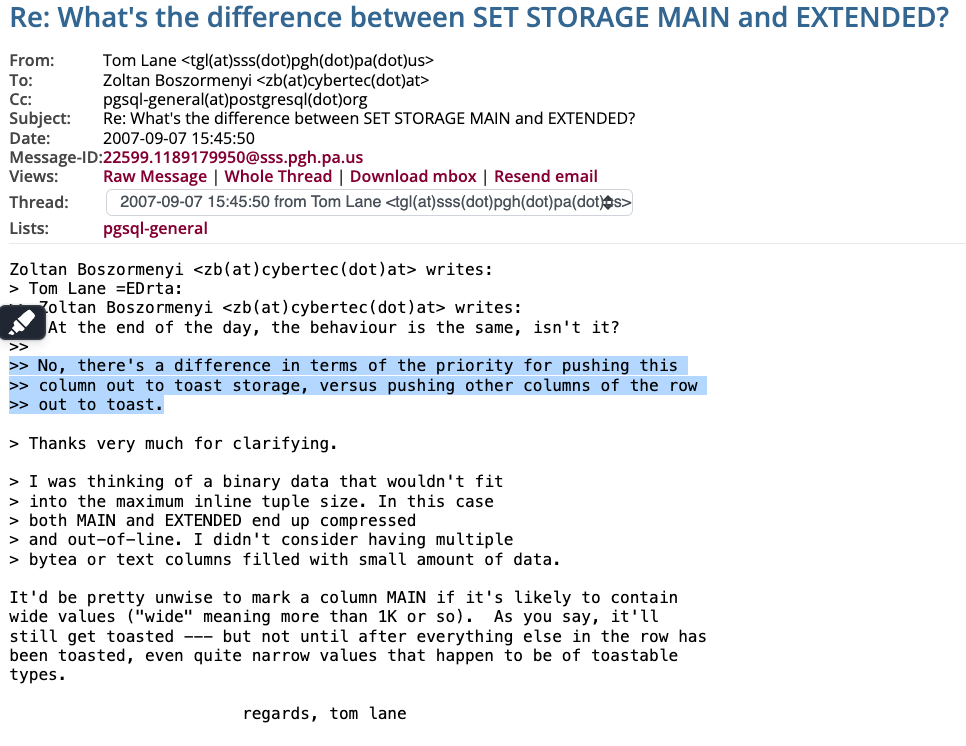
The Difference between MAIN and EXTENDED
The difference is when we have multiple columns which are TOAST-able. The columns which has the strategy of MAIN, is the last one that gets out-of-line. Which means it has higher priority to stay in the row, compared to other columns which have strategy of EXTENDED. If you need more details follow these series of emails:
How to Choose the Strategy?
In my opinion for most cases the defaults are good enough. Now that we have seen how the strategies work we can think about trade offs when we choose one. Let’s take a look at some examples.
Example 1: You are using a Large JSON or JSONB
If you are using a json field, and it is becoming larger and larger, it means that it is not going to be stored in the main table itself anymore, which means a join under the hood to get your data, and the performance of your queries are going to degrade. a solution would be to keep them small or turn them into multiple fields so Postgres does not move them out-of-line.
Example 2: Relatively Large Field that is not used for searching
We have our Posts table. in our use case, we are not using Postgres to search in the body of the posts. So we do not want to use compression to fit this field in the table itself. We can use EXTERNAL strategy in this case, to move this field into out-of-line storage. The reason is that, then we can fit so many more rows in a single Postgres Page, and when we are searching for title , we can fetch what we need, by getting less pages.
Conclusion
TOAST is how Postgres is able to store 1GB of data in a field, although its Page Size is 8kB. Not all Data Types are TOAST-able. Fields like Boolean, or Numeric using PLAIN Strategy, which means no TOAST. Some other data types are able to use EXTENDED(default), EXTERNAL and MAIN Strategy. For us as Backend devs, it is important to know, what happens behind the scenes to debug performance issues caused by some large fields in our Databases.
- 65.2. TOAST
- TOAST
- TOASTing in PostgreSQL, let's see it in action
- Building Columnar Compression for Large PostgreSQL Databases
- The Surprising Impact of Medium-Size Texts on PostgreSQL Performance
https://youtu.be/IfZbqrtfHRs?si=CAZuhbSa9KIC2xY_&t=957
Why Knowing TOAST in PostgreSQL is necessary for Backend Devs! was originally published in Level Up Coding on Medium, where people are continuing the conversation by highlighting and responding to this story.
This content originally appeared on Level Up Coding - Medium and was authored by Poorshad Shaddel
Poorshad Shaddel | Sciencx (2025-01-19T20:28:28+00:00) Why Knowing TOAST in PostgreSQL is necessary for Backend Devs!. Retrieved from https://www.scien.cx/2025/01/19/why-knowing-toast-in-postgresql-is-necessary-for-backend-devs/
Please log in to upload a file.
There are no updates yet.
Click the Upload button above to add an update.