
This content originally appeared on Level Up Coding - Medium and was authored by Pavan Belagatti

We all know that LLMs hallucinate. “LLM hallucination” refers to when a large language model (LLM) generates responses that are factually incorrect or completely fabricated, often appearing plausible but not grounded in reality. To mitigate this LLM hallucinating behaviour, we have three prominent approaches — Prompt engineering, Fine tuning and Retrieval augmented generation (RAG), Of which, RAG is by far considered the most suitable approach.

RAG is a technique that helps mitigate the LLM hallucination by allowing the LLM to access and incorporate relevant information from external knowledge bases, effectively reducing the chances of generating inaccurate or “hallucinatory” outputs by providing a factual grounding for its responses
So, Retrieval-Augmented Generation, or RAG, represents a cutting-edge approach to artificial intelligence (AI) and natural language processing (NLP). It is a technique that combines the capabilities of a pre-trained large language model with an external data source.
RAG Pipeline
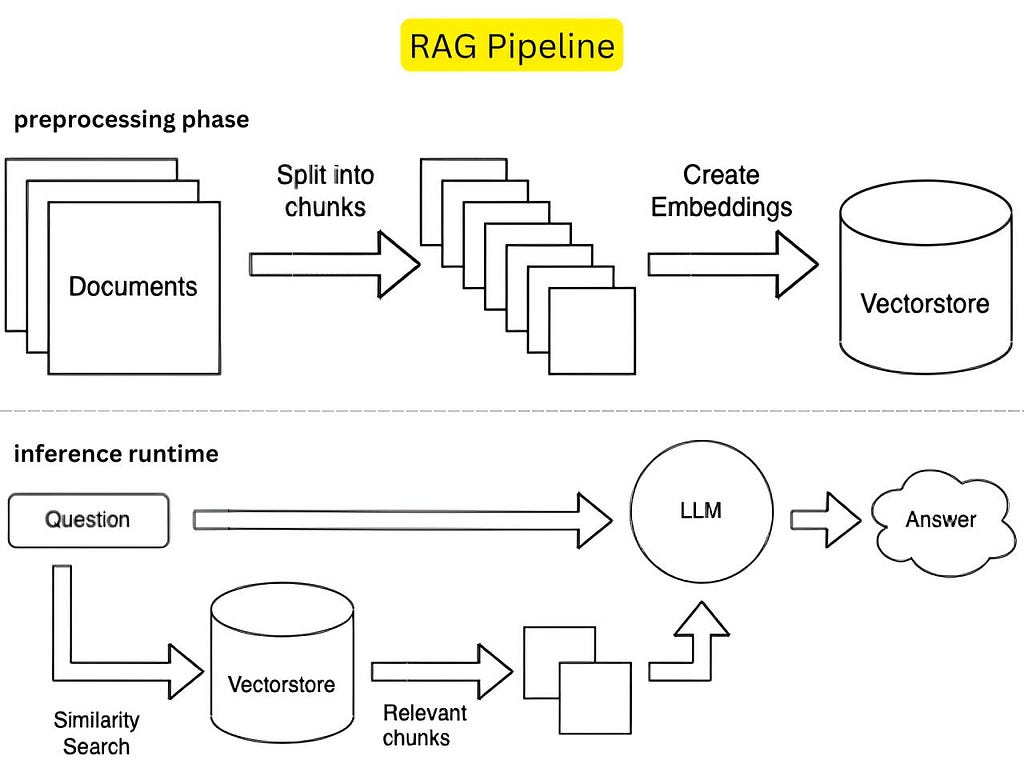
Let’s understand the two main phases of the RAG pipeline!
The first one is preprocessing phase and the second is inference runtime phase. In the preprocessing phase, raw data is collected and transformed into a suitable format for retrieval. This involves several steps: extracting relevant content from various sources, cleaning the data to remove unnecessary characters, and chunking it into smaller segments. Each chunk is then converted into embeddings — numerical representations that capture the semantic meaning of the text — and indexed in a vector database. This indexing is crucial as it allows for efficient querying during the inference phase.The inference runtime phase begins when a user submits a query.
The system generates an embedding for the query and searches the vector database for the most relevant chunks of data based on similarity. The retrieved information is combined with the original query and provided to a large language model (LLM), which generates a coherent and contextually relevant response. This two-phase approach enhances the model’s ability to produce accurate answers by leveraging external knowledge effectively while maintaining the generative capabilities of LLMs.
RAG with LangChain

Well, LangChain has an obvious first mover advantage in the LLM frameworks ecosystem. LangChain took off when RAG started to become the talk of the AI town. Many companies started experimenting with LangChain to build their RAG applications and systems.
LangChain became the first choice of many as it started simplifying the process of building RAG applications by providing modular abstractions for common components like document loaders, embeddings, vector stores, and LLM interactions. Its standardized interfaces enable easy swapping of components, while built-in utilities handle chunking, retrieval, and prompt management.
The framework’s integration with popular tools and databases streamlines development, letting developers focus on application logic rather than infrastructure. LangChain’s active ecosystem and documentation also accelerate development through pre-built chains and examples.
Here is my complete step-by-step RAG tutorial using LangChain.
RAG with LlamaIndex

This framework enables developers to connect their own data sources, allowing for real-time data access and verified responses. By integrating LlamaIndex, developers can enhance the capabilities of LLMs, making them more adaptable and effective in real-world applications.
The popularity of LlamaIndex has been on the rise, as evidenced by its increasing search interest on platforms like Google Trends. Businesses are eager to adopt AI technologies, and LlamaIndex stands out as a robust framework for building LLM-based applications.

The LlamaIndex workflow is designed to streamline the process of building AI applications. It begins with the ingestion of documents, which are then processed and indexed for efficient storage in a vector database.
When a user query is received, it is transformed into a vector embedding and searched against the indexed data. The relevant chunks are identified and sent to the LLM for response generation, ensuring that the answers are both accurate and contextually relevant.
This workflow allows for the integration of both structured and unstructured data sources, making it a versatile solution for various applications.
Here is my step-by-step hands-on video tutorial you can follow and build your first RAG application using LlamaIndex.
RAG with Haystack

Haystack is an open-source framework that significantly simplifies the process of building Retrieval Augmented Generation (RAG) systems by providing a comprehensive set of tools to manage the retrieval of relevant information from large document collections, allowing developers to easily integrate this data with a generative language model to create more accurate and contextually relevant responses to user queries; essentially acting as a complete pipeline for building production-ready RAG applications with advanced features like semantic search and ranking mechanisms.
Haystack empowers developers to quickly and efficiently build robust RAG systems by providing a comprehensive framework for managing data retrieval, integrating with various language models, and fine-tuning the retrieval process for optimal results.
Here is my complete tutorial on building RAG systems using Haystack.
LLM Framework Ecosystem

Choosing the right RAG framework can significantly impact your AI application’s performance and development efficiency.
AI frameworks have become essential tools for building sophisticated AI applications, each addressing specific challenges in the AI development landscape. The workflow diagram shown above illustrates how to choose between key frameworks based on specific project requirements.
LlamaIndex excels in Retrieval-Augmented Generation (RAG) applications, providing robust capabilities for knowledge graphs, document indexing, and structured data access, making it ideal for applications requiring sophisticated data integration.
LangGraph specializes in sequential workflows and state management, perfect for applications needing structured pipelines and multi-step document analysis processes.
CrewAI shines in team-based collaboration scenarios, enabling effective task delegation and role-based coordination among AI agents, particularly useful in projects requiring specialized agent roles working together.
AutoGen focuses on autonomous agent interactions, facilitating complex reasoning and group problem-solving through multi-agent conversations, making it suitable for applications requiring emergent problem-solving capabilities.
Haystack stands out in search-oriented applications, offering modular pipeline construction for question-answering systems and document processing.
Each framework serves a distinct purpose: LlamaIndex handles data integration, LangGraph manages workflows, CrewAI coordinates team efforts, AutoGen enables autonomous interactions, and Haystack focuses on search functionality.
The choice between these frameworks depends on specific project requirements: whether you need RAG capabilities, sequential workflows, team collaboration, autonomous agent interaction, or search-focused solutions. Understanding these distinctions helps developers choose the most appropriate framework for their AI applications.
Vectorize: Building RAG Pipelines Made Easy!

Vectorize is a platform designed to simplify the creation of production-ready Retrieval Augmented Generation (RAG) pipelines. It aims to address the complexities of developing RAG pipelines, from basic to agentic implementations, by providing a tool that allows users to build these pipelines in a seamless way.
Here’s how Vectorize streamlines RAG pipeline development:
• Ease of Use: Vectorize provides a platform where users can create RAG pipelines with confidence. The platform offers a user-friendly interface where users can set up and manage their pipelines.
- RAG Evaluation: Vectorize helps users evaluate different aspects of their RAG pipelines, including:
◦ Embedding models: It helps users find the best embedding model
◦ Chunking strategy: It assists in determining the optimal chunking strategy for their data
◦ Retrieval approach: It enables users to select the most accurate retrieval approach - Data-driven approach: Vectorize uses a data-driven approach to help users select the best configurations for their RAG applications, ensuring accurate results. It achieves this by generating synthetic questions based on the user’s content and using these questions to test different configurations and determine the winning approach.
- Vector Search Indexes: For each RAG evaluation, Vectorize creates and populates multiple vector search indexes using the content of the provided documents. Each index uses a specific vectorization plan including the embedding model and chunking strategy.
- RAG Sandbox: Vectorize offers a RAG sandbox, an end-to-end test environment, where users can compare different vector search indexes and large language models (LLMs). This allows for real-time testing and comparison of different RAG pipeline configurations
- Integration with Vector Databases: Vectorize allows integration with various vector databases, such as Pinecone, SingleStore and many more. This flexibility enables users to choose the database that best suits their needs.
- Source Connectors: Vectorize offers different source connectors, such as web crawlers, which simplifies the process of adding data sources to the RAG pipeline.
- LLM Selection: Vectorize allows users to select different LLMs, such as those from OpenAI or Llama. This enables users to test and compare different LLMs to see what best fits their needs.
- Advanced RAG Pipelines: Vectorize enables the creation of advanced RAG pipelines. It allows for the use of web crawlers as source connectors and provides integration with platforms like OpenAI for embedding models and SingleStore as a vector database.
- Real-world applications: The platform is designed to help users build practical RAG applications by connecting to real world data sources via connectors and integrating with various LLMs and vector databases.
- Evaluation Metrics: Vectorize provides key evaluation metrics such as average relevancy score and NDCG (Normalized Discounted Cumulative Gain) to help users assess the quality of their RAG pipeline results.
- Detailed Results: Vectorize provides detailed results, including the retrieved context, LLM prompts, and generated responses.
- Efficiency: Vectorize allows for building production-ready RAG applications in minutes.
Build Your First RAG Pipeline with Vectorize
Getting started with Vectorize is a straightforward process. Users can create a free account by visiting the Vectorize website. Once registered, you will have the opportunity to create your organization, which serves as the foundation for building your RAG pipelines.
The onboarding process is designed to be user-friendly, guiding you through the initial setup. After creating your organization, you will access the dashboard, where you can begin exploring the features and tools available for building RAG pipelines.

You can select your required choice of integrations. As you can see I have already created my RAG pipeline with SingleStore as a vector database and OpenAI.

A more detailed walkthrough is below,

Next, you can see the sandbox and see the magic of your RAG pipeline.

You can learn how to create a robust production-ready RAG pipeline in my in-depth hands-on video.
My Top 3 LLM Frameworks
BTW, my top three LLM frameworks will be LlamaIndex, LangChain and Haystack.

LangChain follows a modular approach, starting with Document Loaders that feed into Text Splitters for content chunking, followed by an Embeddings component that vectorizes the text. These vectors are stored in a Vector Store and accessed via a Retriever. The workflow incorporates Memory for context retention, Output Parsers for structured responses, and Prompt Templates for query formulation, ultimately connecting to an LLM for generation.
LlamaIndex emphasizes structured data handling, beginning with Data Connectors that feed into a Document Store. Its Node Parser creates structured representations, while the Index Structure organizes information efficiently. It features a dedicated Response Synthesizer and Query Transform components, with both Retrieval and Query Engines working together for optimal information access.
Haystack takes a pipeline-centric approach, starting with File Converters for multiple formats and PreProcessors for text preparation. It employs a Document Store and Retriever, complemented by a Ranker for result scoring and an Answer Generator for response creation. Unique to Haystack is its Evaluator component for quality assessment and a Pipeline orchestrator for workflow management. Each framework, while sharing core RAG concepts, offers distinct advantages: LangChain excels in modularity, LlamaIndex in structured data handling, and Haystack in pipeline customization and evaluation.
But no matter what framework you choose, having a robust data platform for your AI applications is a must. I highly recommend using SingleStore as your all-in-one data platform. SingleStore supports all types of data, has capabilities like hybrid search, fast data ingestion, integration with all the AI frameworks.
LLM Frameworks in Action: Building RAG Systems with LangChain, LlamaIndex, and Haystack! was originally published in Level Up Coding on Medium, where people are continuing the conversation by highlighting and responding to this story.
This content originally appeared on Level Up Coding - Medium and was authored by Pavan Belagatti
Pavan Belagatti | Sciencx (2025-01-24T01:57:33+00:00) LLM Frameworks in Action: Building RAG Systems with LangChain, LlamaIndex, and Haystack!. Retrieved from https://www.scien.cx/2025/01/24/llm-frameworks-in-action-building-rag-systems-with-langchain-llamaindex-and-haystack/
Please log in to upload a file.
There are no updates yet.
Click the Upload button above to add an update.