
This content originally appeared on HackerNoon and was authored by Language Models (dot tech)
:::info Authors:
(1) Corby Rosset, Microsoft Research and Correspondence to corbyrosset@microsoft.com;
(2) Ching-An Cheng, Microsoft Research;
(3) Arindam Mitra, Microsoft Research;
(4) Michael Santacroce, Microsoft Research;
(5) Ahmed Awadallah, Microsoft Research and Correspondence to hassanam@microsoft.com;
(6) Tengyang Xie, Microsoft Research and Correspondence to tengyangxie@microsoft.com.
:::
Table of Links
2.1 RLHF Based on Reward Models
2.2 RLHF with General Preferences
3 Direct Nash Optimization and 3.1 Derivation of Algorithm 1
4 Practical Algorithm – Iterative Contrastive Self-Improvement
5 Experiments and 5.1 Experimental Setup
\ Appendix
A Extension to Regularized Preferences
C Additional Experimental Details
A Extension to Regularized Preferences
In this section, we discuss how to extend the DNO framework to the case of regularized preferences (defined in Eq. (5)),
\
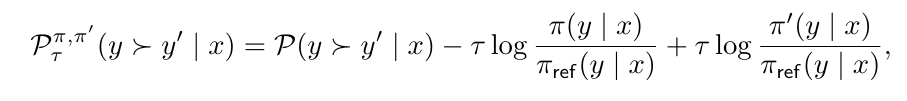
\ which was first introduced and solved by Munos et al. (2023) via Nash-MD introduced earlier.
\

\

\

\

\
:::info This paper is available on arxiv under CC BY 4.0 DEED license.
:::
\
This content originally appeared on HackerNoon and was authored by Language Models (dot tech)
Language Models (dot tech) | Sciencx (2025-04-17T13:00:02+00:00) Extending Direct Nash Optimization for Regularized Preferences. Retrieved from https://www.scien.cx/2025/04/17/extending-direct-nash-optimization-for-regularized-preferences/
Please log in to upload a file.
There are no updates yet.
Click the Upload button above to add an update.