
This content originally appeared on HackerNoon and was authored by Language Models (dot tech)
Table of Links
3 Method and 3.1 Phase 1: Taxonomy Generation
3.2 Phase 2: LLM-Augmented Text Classification
4 Evaluation Suite and 4.1 Phase 1 Evaluation Strategies
4.2 Phase 2 Evaluation Strategies
5.3 LLM-Augmented Text Classification
5.4 Summary of Findings and Suggestions
6 Discussion and Future Work, and References
3.2 Phase 2: LLM-Augmented Text Classification
After the taxonomy is finalized, we next train a text classifier that can be reliably deployed to perform label assignments at very large-scale and in real-time. Following recent work that shows the strengths of LLMs as annotators of training data [8, 15], we propose to leverage LLMs to obtain a “pseudo-labeled” corpus set
\
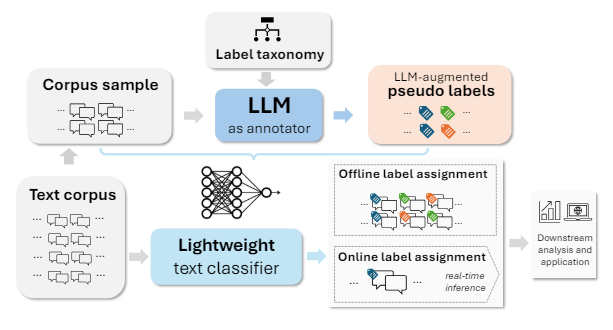
\ using the taxonomy yielded in Phase 1, then use these labels to train more efficient classifiers at scale. Specifically, we prompt an LLM to infer the primary label (as a multiclass classification task) and all applicable labels (as a multilabel classification task) on a “medium-to-large” scale corpus sample that covers the range of labels in the taxonomy, creating a representative training dataset that can be used to build a lightweight classifier, such as a Logistic Regression model or a Multilayer Perceptron classifier. In this way, we can induce “pseudo labels” from the LLM classifier and transfer its knowledge to a more efficient and manageable model that can be deployed and served at scale. An illustrative figure of this phase is presented in Figure 3.
\
:::info This paper is available on arxiv under CC BY-NC-ND 4.0 DEED license.
:::
:::info Authors:
(1) Mengting Wan, Microsoft Corporation and Microsoft Corporation;
(2) Tara Safavi (Corresponding authors), Microsoft Corporation;
(3) Sujay Kumar Jauhar, Microsoft Corporation;
(4) Yujin Kim, Microsoft Corporation;
(5) Scott Counts, Microsoft Corporation;
(6) Jennifer Neville, Microsoft Corporation;
(7) Siddharth Suri, Microsoft Corporation;
(8) Chirag Shah, University of Washington and Work done while working at Microsoft;
(9) Ryen W. White, Microsoft Corporation;
(10) Longqi Yang, Microsoft Corporation;
(11) Reid Andersen, Microsoft Corporation;
(12) Georg Buscher, Microsoft Corporation;
(13) Dhruv Joshi, Microsoft Corporation;
(14) Nagu Rangan, Microsoft Corporation.
:::
\
This content originally appeared on HackerNoon and was authored by Language Models (dot tech)
Language Models (dot tech) | Sciencx (2025-04-18T02:11:01+00:00) TnT-LLM: LLMs for Automated Text Taxonomy and Classification. Retrieved from https://www.scien.cx/2025/04/18/tnt-llm-llms-for-automated-text-taxonomy-and-classification/
Please log in to upload a file.
There are no updates yet.
Click the Upload button above to add an update.