
This content originally appeared on Level Up Coding - Medium and was authored by John Damask

My last post, Using LLM-Structured Outputs for Routing, showed how to apply a classic software integration pattern to the new world of AI Engineering. This post shows how to improve the Router’s ability to make the right call. You can get the companion notebook for this post on my GitHub.
It can be tricky to wrap your head around Evals if you have’t used them before. There’s not a ton of technical documentation, LLMs aren’t good at writing Eval code, there are a bunch of options (even OpenAI offers different tools), and OpenAI’s Eval SDK is just plain tough to follow — they heavily use string-based dispatch so if you don’t know the label for a class, you need to dig through the code to find it.
This post was inspired by three very useful cookbooks by Josiah Grace(OpenAI) so I’m paying it forward by adding a string check example to the list.
Quick Visual of Evals
ChatGPT is a great tool to help understand code by visualizing it. I uploaded Josiah’s notebook from his Bulk Prompt Experimentation post and asked it to create a Mermaid-compatible diagram. Take a minute to digest this.
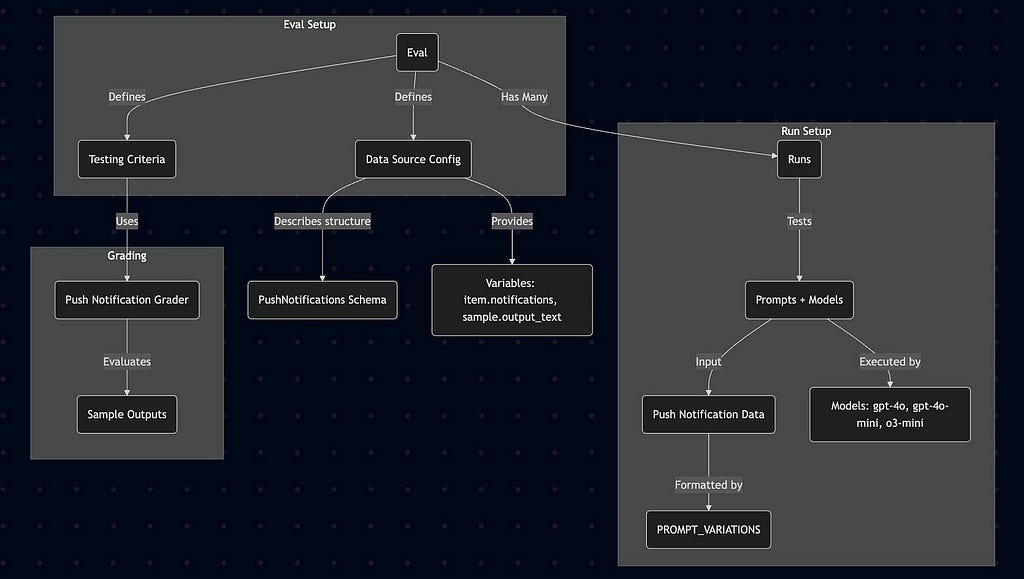
Use Case: Routing Budget Requests with LLMs
I’ve been experimenting making drudge-work more fun by gamifying it. My current project is an app that helps enterprise departments (e.g. IT, HR, Facilities, etc) create high quality annual budgets. It’s a jumpscare/escape game a la Five Nights at Freddy’s where the evil Finance department is fed up with your delays — and they’re coming for you.
In the game, you’re chatting with an AI friend who helps with web research, adds items to your budget, and compiles everything into a spreadsheet you can download. You can see some of the gameplay here.
It’s kind of ridiculous but makes me laugh, and good vibes isn’t an emotion I’ve ever felt building a departmental budget. I may release it as a product — let me know if you’re interested in checking it out.
Since the primary interface for building budgets is a chatbot, the code needs to interpret what the user wants to do from their input. I use an LLM Router to figure it out and need very high accuracy.
For example, a user might say:
“Create a budget item for 10 Mac M1s. They cost $3,500 each.”
The system should recognize that this requires structured data and route it to the structured_response handler so that it can add a line item to the budget. But other requests might need a chat (chat_response) or a data export (download_file).
Generally speaking, proper routing is critical to good user experience — if the LLM gets it wrong the user will be confused, at best, or dismiss the app as “broken” and never use it again. The stakes are much higher with something you rely on, like an Agent for healthcare decisions.
From the developer perspective, messing around with a couple of different prompts until you find one that feels good is a bad idea. A better one is to test a variety of prompts and models over a bunch of inputs to get some real numbers.
Evals for Better Get Done
Evals are task-oriented and iterative, they’re the best way to check how your LLM integration is doing and improve it.
In this eval, the task is to pick the model-prompt combination that provides the best performance, consistency, and cost for our use-case:
- We’ve created an LLM-based Router for our budget chatbot. The router’s job is to triage user requests and direct them to the proper component. Components can be other AI functions or native function calls that don’t require AI.
- We have a predetermined set of possible routes the model can choose from.
- We have created a dataset of user inputs and the ideal response for comparison.
- We want to see how detailed our prompt needs to be to achieve a high percentage of matches between the model output and the ideal response as labeled in our data file.
Data
First, I made a file with 100 records. Each record has an input showing what the user might ask and the ideal response. For example:
{"item": {"input": "Create a budget item for 10 Mac M1s. They cost $3500 each.", "ideal": "structured_response"}}
{"item": {"input": "Save it!", "ideal": "download_file"}}
{"item": {"input": "What are some IT helpdesk MSPs in the greater Boston area?", "ideal": "chat_response"}}Next, upload the file to OpenAI.
curl https://api.openai.com/v1/files \
-H "Authorization: Bearer $OPENAI_API_KEY" \
-F purpose="evals" \
-F file="@llm-as-router-IT-budget-requests.jsonl"
This gives the file id to use later on.
{
"object": "file",
"id": "file-F5vpTawCEy1MSj6bymt9hF",
"purpose": "evals",
"filename": "llm-as-router-IT-budget-requests-expanded.jsonl",
"bytes": 11755,
"created_at": 1746025101,
"expires_at": null,
"status": "processed",
"status_details": null
}dataset_file_id = "file-F5vpTawCEy1MSj6bymt9hF"
In the notebook I have a class that makes it easy to handle the data in the Eval. (Note that “item” seems to be an internal key used by OpenAI Evals so we don’t need to include it in our Class.)
This structure allows for variable expansion at runtime,{{item.input}} and {{item.ideal}}
class Record(BaseModel):
input: str
ideal: str
Setting up your eval
An Eval holds the configuration that is shared across multiple Runs, it has two components:
- Data source configuration data_source_config - the schema (columns) that your future Runs conform to.
- Testing Criteria testing_criteria - How you'll determine if your integration is working for each record.
# This data_source_config defines what variables are available throughout the eval.
data_source_config = {
"type": "custom", # We set this to custom because we're providing our own item_schema
"item_schema": Record.model_json_schema(), # This lets our code access Record properties
"include_sample_schema": True, # Necessary to access LLM response
}
# This is our testing_criteria. It tells the Eval engine check if input==reference
router_grader = {
"name": "Router Grader",
"type": "string_check", # String-based dispatch. Must map to an Eval type define in OpenAI SDK
"input": "{{sample.output_text}}", # LLM response to our query
"reference": "{{item.ideal}}", # Expected response from our dataset
"operation": "eq" # Operations: eq, ne, like, ilike
}
Create the Eval
Creating an Eval means registering it on OpenAI’s platform. It acts as a template so you can run it many times with different datasets, duplicate it, etc.
We create it here and store the result so we can reference the Eval’s ID later on.
eval_create_result = openai.evals.create(
name="Route check Eval",
metadata={
"description": "This eval tests several prompts and models to find the best performing combination.",
},
data_source_config=data_source_config, # Defined above
testing_criteria=[router_grader], # Defined above
)
eval_id = eval_create_result.id
print(eval_id)
Prompts of Increasing Specificity
We start with a generic prompt and build on it (partial view):
PROMPT_PREFIX = """
You are a router.
Your only job is to determine which route best matches the user's query.
"""
PROMPT_VARIATION_BASIC = f"""
{PROMPT_PREFIX}
Your choices are:
- chat_response
- structured_response
- download_file
You should return just the route and nothing else.
# Instructions
- Always review the entire user input message before responding
- You will choose the appropriate type of response based on your text_format instructions.
This will contain a set of structured outputs.
- You will always respond with text from the structured output set
- You will always return only one structured output
- If you unsure about what type to choose for response, you will respond with 'chat_response'.
- If the user asks for multiple things at once, you will go with respond with 'chat_response' unless it's clear
that the user wants to add multiple budget items, in which case you will returned 'structured_response'.
- You will only return 'download_file' if a reasaonable person would think that this is what the user is requesting.
"""
... (other prompts not shown here) ...
prompts = [
("prefix_only", PROMPT_PREFIX),
("basic", PROMPT_VARIATION_BASIC),
("with_samples", PROMPT_VARIATION_WITH_SAMPLES),
("with_examples", PROMPT_VARIATION_WITH_EXAMPLES),
]
Models
Next we define the list of models we want to try.
models = ["gpt-4o-mini", "gpt-4.1-mini", "gpt-4.1-nano"]
Creating Runs
Our Eval, prompts, and models are set so now we can create Runs. To do this, we make a nested loop so each prompt is tested against every model.
The input_messages template shows where we're passing in the prompt as a parameter and we're also passing in the {{item.input}} from data set.
You may notice that we’re not looping over our dataset in the code. This is because the eval engine does that for us. As long as we tell the eval how to access the data (done here via the file_id), we're good to go.
tasks = []
for prompt_name, prompt in prompts:
for model in models:
run_data_source = {
"type": "completions",
"input_messages": {
"type": "template",
"template": [
{
"role": "developer",
"content": prompt,
},
{
"role": "user",
"content": "{{item.input}}",
},
],
},
"model": model,
"source": {
"type": "file_id",
"id": dataset_file_id
}
}
# run_create_result = openai.evals.runs.create(
tasks.append(client.evals.runs.create(
eval_id=eval_id,
name=f"{prompt_name}_{model}",
data_source=run_data_source,
))
result = await asyncio.gather(*tasks)
View Results
Lastly, the notebook has some code to plot the results of our runs. You can get the same thing from OpenAI’s Evals dashboard but why not save an alt-tab by charting it here?
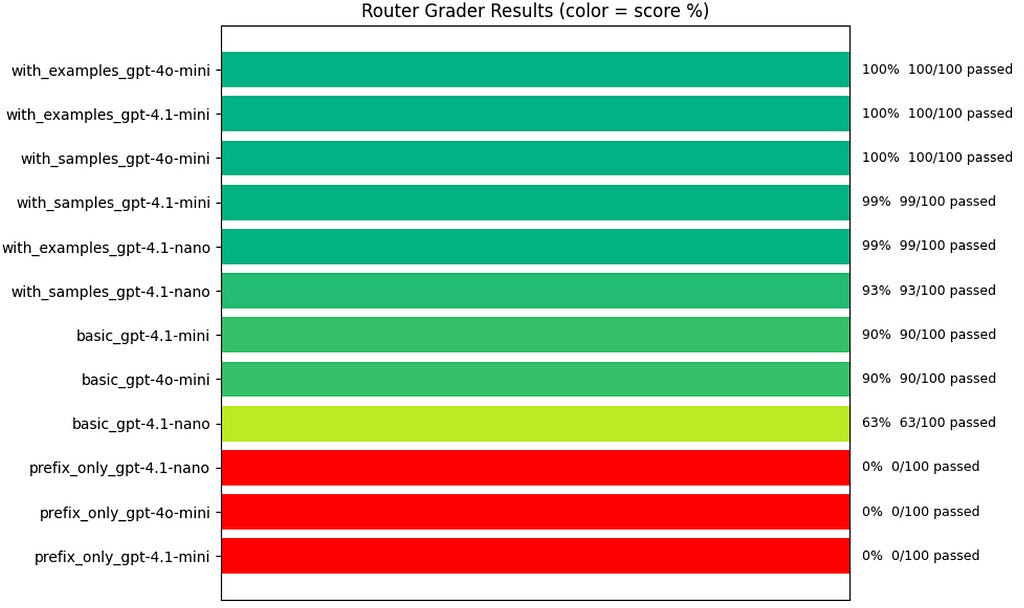
We see that score correlates with the prompt more so than the model, though both are important.
Conclusion
These data drove the decision to go with the most elaborate prompt (with examples) paired with 4o-mini ($0.15/million tokens).
Routers need to be right all of the time — or at least as close as possible. This simple eval can be re-run each time a new route is added, a new model is released, or routinely using actual user chats logged by the app.
OpenAI Evals: Choosing a Model-Prompt Combination was originally published in Level Up Coding on Medium, where people are continuing the conversation by highlighting and responding to this story.
This content originally appeared on Level Up Coding - Medium and was authored by John Damask
John Damask | Sciencx (2025-05-07T14:17:52+00:00) OpenAI Evals: Choosing a Model-Prompt Combination. Retrieved from https://www.scien.cx/2025/05/07/openai-evals-choosing-a-model-prompt-combination/
Please log in to upload a file.
There are no updates yet.
Click the Upload button above to add an update.