
This content originally appeared on Level Up Coding - Medium and was authored by Hyunjong Lee

1. Introduction
In this article, I’ll walk through the development of a local AI agent that communicates with a previously built MCP(Model Context Protocol) server to generate context-aware responses using tool-calling.
Why I started this project
This article is a follow-up to my previous article, where I introduced a custom MCP server that connects to my personal Obsidian knowledge base. Rather than using the official MCP server with file system access, I chose to build my own for several reasons:
- To enforce read-only access to my file system
- To avoid exposing directory structure of file paths to external AI model
- To deeply understand how the MCP works by implementing it
For more details, please refer to my previous article
How I Built a Local MCP Server to Connect Obsidian with AI
After building the MCP server, I wanted to address a new challenge: dependency on external AI models. While Claude has demonstrated excellent reasoning capabilities, its usage is limited unless you’re on a paid plan. More importantly, relying on external AI services means that the contents of my private knowledge notes are still being sent outside my local environment.
This article covers the next steps in building a fully local, private agent:
- Implementing an MCP client that connects to the MCP server
- Integrating a local LLM model for response generation
- Building an LLM agent that uses both MCP and the model to answer questions
For this purpose, I chose not to use frameworks like LangChain, so the entire flow is transparent and easy to understand.
2. Integration of sLLM with Tool-Calling Support
2.1. Small Language Model for Local Use
In agent development, the most critical thing is the brain — the LLM. The quality of the generated responses depends heavily on the model’s reasoning ability. However, since the goal is to run everything locally, using massive LLM is not feasible. Instead, we must rely on small Language Model(sLLM) that can run on a local GPU or CPU environment.
But not all sLLMs are suitable. If the model’s response quality is too low or it lacks the ability to follow tool-calling instructions, it becomes unusable for this kind of agent architecture.
Previously, I experimented with the Llama 3.1 8B-Instruct model, which delivered impressive results. I used it in a project where multiple models, each with different system prompts(personas), engaged in discussions on selected topics to generate synthetic(artificial) text data. If you’re interested in the details, please check out the article below.
Leveraging AI Conversations to Generate Synthetic Text Data with Llama 3.1
While the Llama 3.1 8B-Instruct model also supports tool-calling, for this project, I opted for Llama 3.2 version model. The 1B and 3B models from Llama 3.2 are lightweight models designed for on-device agentic applications, which keep all data local and help preserve user privacy.
According to Meta’s benchmarking results, the Llama 3.2 models strike a good balance between size and performance. Despite their smaller size, they offer reasonable response quality and support for tool-calling, making them well-suited for this project.
As explained in Meta’s official blog post, the Llama 3.2 models were created by applying structured pruning to the Llama 3.1 8B model in a single-shot manner. To recover performance after pruning, Meta used knowledge distillation from multiple Llama 3.1 models, as illustrated in the diagram below.

I won’t go into the technical details here. If you’re curious, I encourage you to read through Meta’s official blog post.
Llama 3.2: Revolutionizing edge AI and vision with open, customizable models
2.1. The Tool Calling Process of LLM
How does the LLM invoke a tool and generate a response? The overall tool-calling process is illustrated below.
When information about available tools is provided — either through the system prompt or user prompt — the LLM determines whether a tool should be invoked. If so, it generates a function call definition as its response.
The LLM application then parses the function call, executes the corresponding tool, and feeds the result back to the model. Based on the tool’s output, the model can generate a synthesized response.
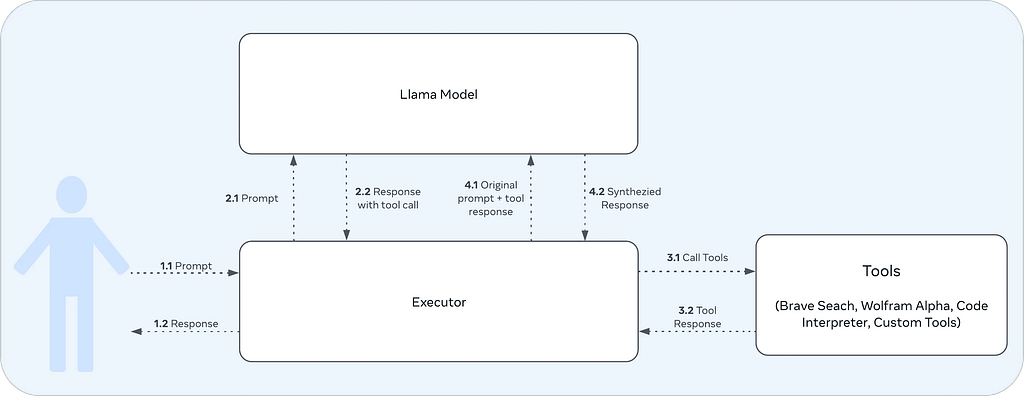
In this project, the Tools component in the diagram is replaced by the MCP Client, which is responsible for invoking tools.
This following explanation is based on the official Llama 3.1 documentation. If you’re already familiar with this, you can skip ahead to the next chapter.
Llama 3.1 | Model Cards and Prompt formats
Let’s briefly review the special tokens and role structure that form the backbone of prompt formatting.
Special Tokens
- <|begin_of_text|> : Specifies the start of the prompt.
- <|start_header_id|> {role} <|end_header_id|> : Enclose the role for a particular message.
- <|eot_id|> : (End of turn); signals to the executor that the model has finished generating a response.
Supported Roles
- system : Defines the context in which the model operates. It usually includes instructions, rules, guidelines, or background information to help the model’s behavior
- user : Represents the input from human user. It includes the inputs, commands, and questions to the model
- assistant: Represents the response generated by the AI model based on the context
- ipython: Semantically, this role means “tool”. This is used to return the output of a tool invocation back to the model from the executor.
Let’s take a look at how the LLM determines when to invoke and how it generates a response.
1) System Prompt with Tool Definition
The system prompt includes tool definitions in JSON format, specifying the available tools and their parameters. This definition can also be included in the user prompt, although placing it in the system prompt is generally preferred for clarity.
<|start_header_id|>system<|end_header_id|>
You are an expert in composing functions. You are given a question and a set of possible functions.
Based on the question, you will need to make one or more function/tool calls to achieve the purpose.
If none of the functions can be used, point it out. If the given question lacks the parameters required by the function,also point it out. You should only return the function call in tools call sections.
If you decide to invoke any of the function(s), you MUST put it in the format of [func_name1(params_name1=params_value1, params_name2=params_value2...), func_name2(params)]
You SHOULD NOT include any other text in the response.
Here is a list of functions in JSON format that you can invoke.
[
{
"name": "get_user_name",
"description": "Retrieve a name for a specific user by their unique identifier. Note that the provided function is in Python 3 syntax.",
"parameters": {
"type": "dict",
"required": [
"user_id"
],
"properties": {
"user_id": {
"type": "integer",
"description": "The unique identifier of the user. It is used to fetch the specific user details from the database."
}
}
}
}
]
<|eot_id|>
2) User Prompt to LLM
The system prompt, which includes the tool definitions, is combined with the user prompt that contains the actual query. To make the LLM to generate a response by completing the sentence, the message is concluded with an assistant header.
<|start_header_id|>user<|end_header_id|>
Can you retrieve the name of the user with the ID 7890?
<|eot_id|>
<|start_header_id|>assistant<|end_header_id|>
3) Response with tool-call
In this step, the LLM determines that answering the user’s query requires a function call. It responds by generating a function call expression that matches the format specified in the system prompt.
[get_user_name(user_id=7890)]
<|eot_id|>
4) Original Prompt + Tool Response
The application executes the requested function and appends the result back to the prompt. The role ipython is used to mark this tool result when passing it back to the model.
...
<|start_header_id|>user<|end_header_id|>
Can you retrieve the name of the user with the ID 7890?
<|eot_id|>
<|start_header_id|>assistant<|end_header_id|>
[get_user_name(user_id=7890)]
<|eot_id|>
<|start_header_id|>ipython<|end_header_id|>
{"output": "Hyunjong Lee"}
<|eot_id|>
<|start_header_id|>assistant<|end_header_id|>
5) Synthesized Response
Finally, the model produces a complete response using the tool output:
The name of user who has the ID is “Hyunjong Lee”.
<eot_id>
Even lightweight models like Llama 3.2 1B and 3B are capable of performing tool-calling. However, according to Meta’s official documentation, for building stable tool-aware conversational applications, it is recommended to use either the 70B-Instruct or 405B-Instruct models.
While the 8B-Instruct model supports zero-shot tool calling, Meta’s blog notes that it cannot reliably maintain a conversation when tool definitions are included in the prompt. Therefore, when working with smaller models, it’s often necessary to remove tool instructions from the prompt to ensure smoother interaction between the user and the AI model.
This is a critical consideration for generating high-quality responses and one you should definitely keep in mind.
Note: We recommend using Llama 70B-instruct or Llama 405B-instruct for applications that combine conversation and tool calling. Llama 8B-Instruct can not reliably maintain a conversation alongside tool calling definitions. It can be used for zero-shot tool calling, but tool instructions should be removed for regular conversations between the model and the user. — from meta AI notes
3. Building LLM Agent
Now, let’s take a look at the architecture of the agent I built. It closely follows the tool-calling process described above, with a few additional components to enable communication with MCP server.
The core components are: MCP Client & Manager, LLM, and Agent
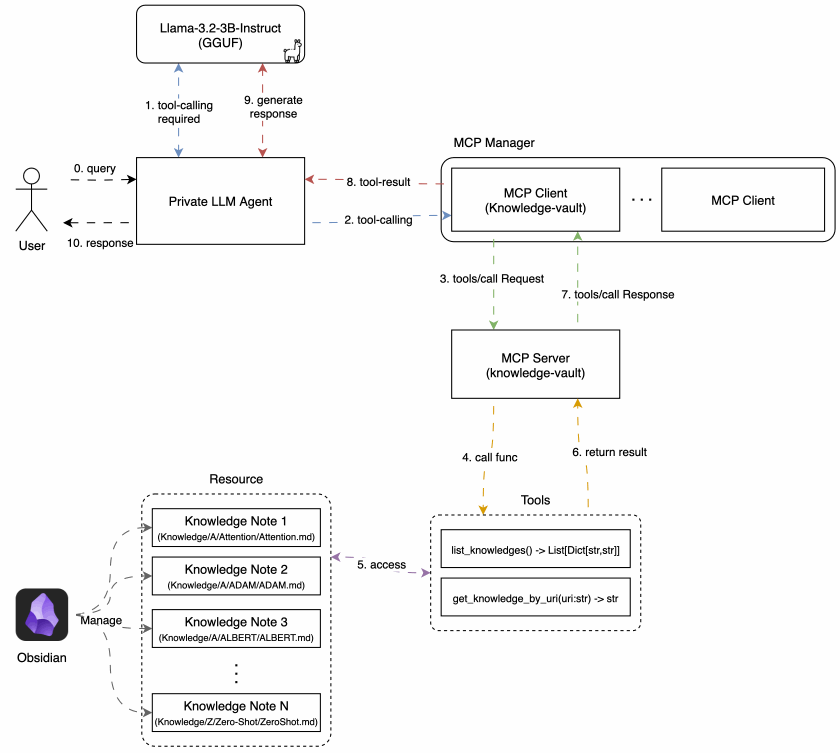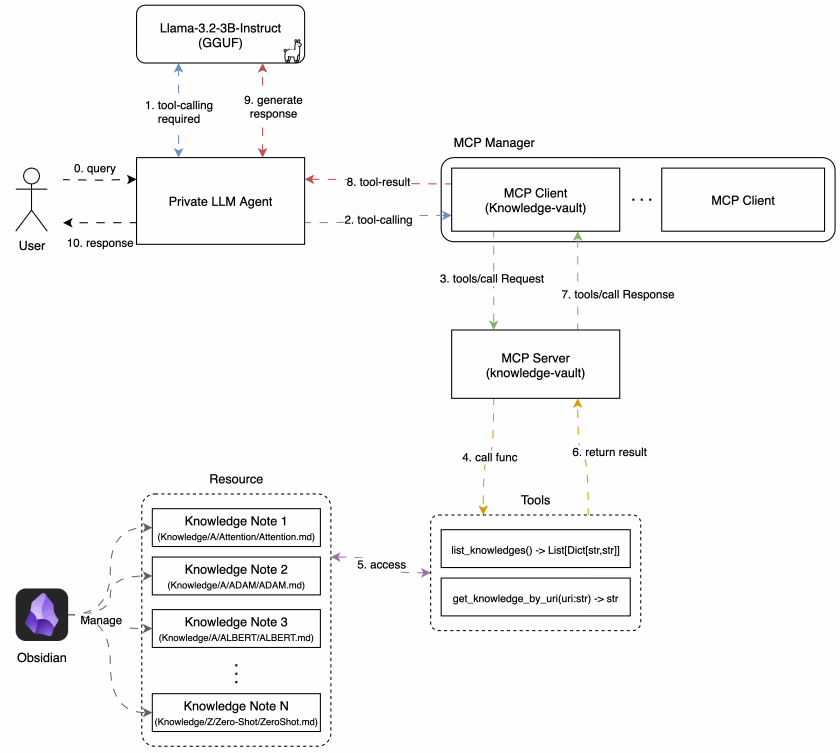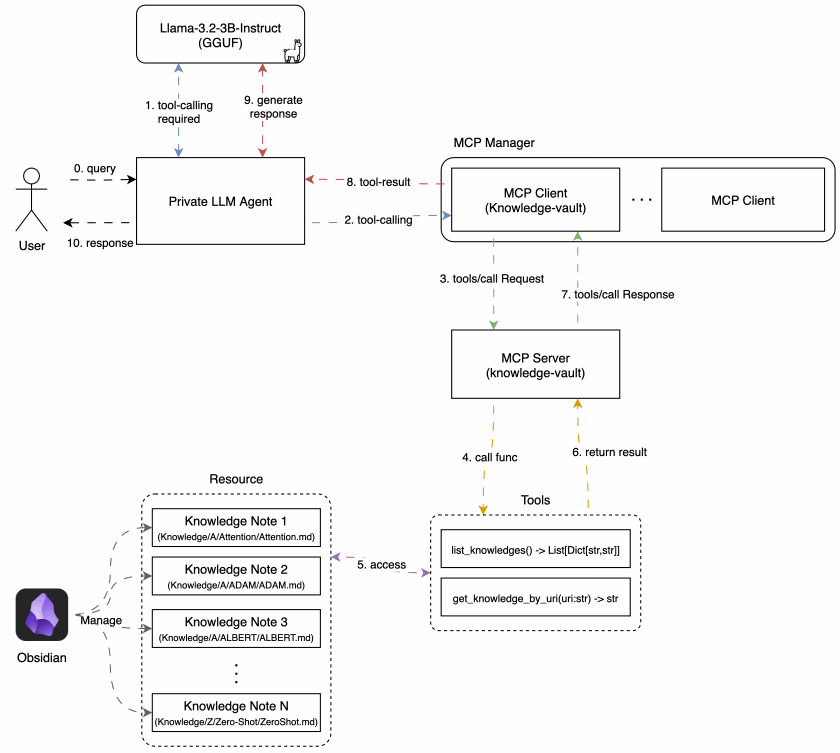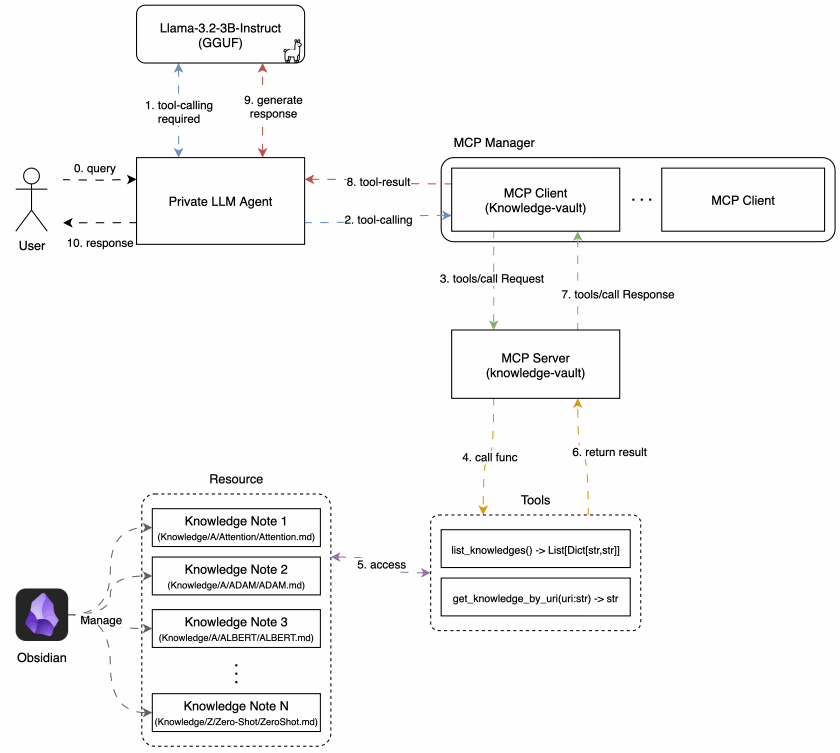
As this article contains a significant amount of code, only essential parts are shown here for clarity. You can fine the full source code in the GitHub repository below.
3.1. MCP Client and Manager
A. MCP Client
First, we need an MCP Client capable of establishing a 1:1 connection with the MCP server. This was implemented using the Python MCP SDK, following the official MCP documentation:
For Client Developers - Model Context Protocol
Below is the MCPClient class, which handles the connection to the server. Since the custom MCP server I built communicates over standard input/output(stdio), the client spawns the server process, connects to it via its read/write streams.
class MCPClient:
def __init__(self):
self.session = None
self.name = ''
self.exit_stack = AsyncExitStack()
async def connect_to_server(self, server_script_path:str):
server_params = StdioServerParameters(
command = "python",
args=[server_script_path],
env=None
)
# spawaning a process for running a mcp server
stdio_transport = await self.exit_stack.enter_async_context(stdio_client(server_params))
self.read, self.write = stdio_transport
# init session using read/write pipes of the process spawned
self.session = await self.exit_stack.enter_async_context(ClientSession(self.read, self.write))
...
After creating the client session, the client follows the MCP connection lifecycle. It first sends an initialize request to the MCP server, waits for a response, and then complete the handshake by sending an initialized notification as an acknowledgement.

As a result of the initialize request, the client receives information about the server, which is structured as shown below.
class InitializeResult(Result):
"""After receiving an initialize request from the client, the server sends this."""
protocolVersion: str | int
"""The version of the Model Context Protocol that the server wants to use."""
capabilities: ServerCapabilities
serverInfo: Implementation
instructions: str | None = None
"""Instructions describing how to use the server and its features."""
class Implementation(BaseModel):
"""Describes the name and version of an MCP implementation."""
name: str
version: str
After establishing the connection, the MCP Client can obtain the server’s name and version information. If the server is implemented using the FastMCP class and no explicit version is specified, the version defaults to the MCP SDK’s package version.
class MCPClient:
...
async def connect_to_server(self, server_script_path:str):
...
# connect server by sending initialize request
init_result = await self.session.initialize()
server_info = init_result.serverInfo
self.name = f"{server_info.name}(v{server_info.version})"
The MCP Client includes essential methods such as list_tools() and list_resources() to enumerate available tools and resources, as well as call_tool(name, args) to invoke a specific tool. Their implementations are shown below.
class MCPClient:
...
async def list_tools(self) -> list[types.Tool]:
response = await self.session.list_tools()
tools = response.tools
return tools
async def list_resources(self) -> list[types.Resource]:
response = await self.session.list_resources()
resources = response.resources
return resources
async def call_tool(self, name, args) -> tuple[bool, list[types.TextContent]]:
response = await self.session.call_tool(name, args)
return [response.isError, response.content]
B. MCP Manager
Since each MCP Client maintains a one-to-one connection with an MCP server, supporting multiple servers requires managing multiple client instances.
To handle this, I defined an MCP Client Manager, which is responsible for initializing and cleaning up clients for each registered MCP server path.
class MCPClientMaanger:
def __init__(self):
self.server_path:list[str] = []
self.clients:list[MCPClient] = []
def register_mcp(self, server_path:str):
self.server_path.append(server_path)
async def init_mcp_client(self):
for path in self.server_path:
c = MCPClient()
await c.connect_to_server(path)
self.clients.append(c)
async def clean_mcp_client(self):
for c in self.clients:
await c.cleanup()
Another important responsibility of the class is to fetch resource and tool information from the appropriate registered MCP client. To support this, the manager maintains a mapping that keeps track of which MCP client is associated with which each tool or resource.
class MCPClientMaanger:
def __init__(self):
...
self.tool_map:dict[str, int] = dict()
self.tool_info:dict[str, dict[str, str]] = dict()
self.resource_map:dict[str, int] = dict()
...
async def get_resource_list(self) -> list[dict[str, str]]:
resource_list = []
for idx, c in enumerate(self.clients):
resources = await c.list_resources()
for rsrc in resources:
resource_list.append(utils.resource2dict(rsrc))
self.resource_map[utils.uri2path(rsrc.uri)] = idx
return resource_list
async def get_func_scheme(self) -> list[dict[str, str]]:
func_scheme_list = []
for idx, c in enumerate(self.clients):
tools = await c.list_tools()
for tool in tools:
func_scheme_list.append(utils.tool2dict(tool))
self.tool_map[tool.name] = idx
func_info = self.tool_info.get(self.clients[idx].name, {})
func_info[tool.name] = tool.description
self.tool_info[self.clients[idx].name] = func_info
return func_scheme_list
async def call_tool(self, name:str, param:dict[str, Any]) -> tuple[bool, list[types.TextContent]]:
idx = self.tool_map.get(name, -1)
if idx < 0:
raise errors.MCPException(f"Unknown tool name{name}")
client = self.clients[idx]
result = await client.call_tool(name, param)
return result
3.2. LLM Agent
A. LLM Model
For the agent’s language model, I used Llama, running locally on my MacBook via Llama.cpp.
GitHub - ggml-org/llama.cpp: LLM inference in C/C++
The first step to using a model with Llama.cpp is to download the model weights from Hugging Face. You can do this using the Hugging Face utility, which allows you to fetch a snapshot of the model repository as shown below.
from huggingface_hub import snapshot_download
model_id = "meta-llama/Llama-3.2-3B-Instruct"
snapshot_download(repo_id=model_id, local_dir="./models/llama-3.2-3B-Instruct", revision="main")
Llama.cpp requires language models to be in the GGUF format. After downloading the model from Hugging Face, you can use the conversion script provided by Llama.cpp to convert the model into GGUF format, as shown below:
$ python convert_hf_to_gguf.py ./models/llama-3.2-3B-Instruct --outfile ./models/llama-3.2-3B-Instruct.gguf --outtype f16 --verbose
A custom wrapper class was implemented using the Llama.cpp Python bindings, allowing prompts to be passed in and responses to be generated programmatically.
class LlamaCPP(BaseModel):
def __init__(self, name:str, model:Llama):
self.name = name
self.model = model
self.max_tokens = 1024
@classmethod
def from_path(cls, model_path:str, n_ctx:int=0, **kwargs) -> Self:
model = Llama(
model_path=model_path,
n_ctx=n_ctx,
verbose=False,
**kwargs
)
return cls(name = os.path.basename(model_path), model=model)
def generate(self, prompt:str, **kwargs) -> str:
if 'max_tokens' not in kwargs:
kwargs['max_tokens'] = self.max_tokens
output = self.model(prompt, **kwargs)
choices = output['choices']
response = choices[0]['text'].strip()
return response
B. Prompt
Llama.cpp provides a high-level API function, create_chat_completion(), which allows you to generate responses by passing in structured messages in a simple format, as shown below.
response = llm.create_chat_completion(
messages = [
{
"role": "system",
"content": "You are an assistant who perfectly describes images."
},
{
"role": "user",
"content": "Describe this image in detail please."
}
]
)
However, to gain more control over prompt construction and handling, I implemented helper classes: LlamaMessage and LlamaPrompt.
The LlamaMessage class is responsible for formatting messages according to the expected Llama prompt structure. It handles the assigned role, content, and optionally a tool_scheme, depending on whether tool_enabled is set — I’ll discuss the role of tool_enabled in a later section.
class LLamaMessage(BaseMessage):
def __init__(self, role:str, content:str='', tool_scheme:str=''):
self.role:str = role
self.content:str = content
self.tool_scheme:str = tool_scheme
def template(self, tool_enabled:bool=False) -> str:
#* Llama CPP insert BOS token internally
prompt = f"<|start_header_id|>{self.role}<|end_header_id|>"
if tool_enabled and self.tool_scheme:
prompt += f"{self.tool_scheme}"
if self.content:
prompt += f"{self.content}<|eot_id|>"
return prompt
The Prompt class manages the conversation history between the model and the user, and is responsible for constructing multi-turn prompts. This class is used directly by the agent, and provides APIs to add messages according to their roles, such as user or assistant.
Ultimately, it generates the final input prompt (also known as the generation prompt) that is passed to the LLM for response generation.
class LlamaPrompt(BasePrompt):
ROLE_SYSTEM = 'system'
ROLE_USER = 'user'
ROLE_ASSISTANT = 'assistant'
ROLE_TOOL = 'ipython'
def __init__(self) -> None:
self.system_prompt:BaseMessage = LLamaMessage('system', "You are a helpful assistant.")
self.history:History = History()
def append_history(self, message:LLamaMessage):
self.history.append_message(message)
def set_system_prompt(self, system_prompt:LLamaMessage):
self.system_prompt = system_prompt
def get_system_prompt(self, system_prompt:str):
return LLamaMessage(LlamaPrompt.ROLE_SYSTEM, system_prompt)
def get_user_prompt(self, question:str, tool_scheme:str='') -> LLamaMessage:
return LLamaMessage(LlamaPrompt.ROLE_USER, question, tool_scheme=tool_scheme)
def get_assistant_prompt(self, answer:Optional[str]="") -> LLamaMessage:
return LLamaMessage(LlamaPrompt.ROLE_ASSISTANT, answer)
def get_tool_result_prompt(self, result:str) -> LLamaMessage:
return LLamaMessage(LlamaPrompt.ROLE_TOOL, result)
def get_generation_prompt(self, tool_enabled:bool=False, last:int=50) -> str:
prompt = [self.system_prompt]
prompt += self.history.get_chat_history(last=last)
prompt += [self.get_assistant_prompt(answer='')] #* generation prompt
return ''.join([p.template(tool_enabled=tool_enabled) for p in prompt])
Currently, the prompt format follows the Llama prompt template, since the agent uses a Llama model under the hood. However, the design is modular — other AI models can be supported by subclassing and implementing the BaseMessage and BaseModel interfaces accordingly.
The History class, used by the Prompt class, is responsible for maintaining the record of past messages. It is designed to optionally return only the latest k messages, depending on the context or application requirements.
class History:
def __init__(self, max_history:int=50) -> None:
self._history:list[BaseMessage] = []
self._max_history:int = max_history
def append_message(self, msg:BaseMessage):
self._history.append(msg)
self._history = self._history[-self._max_history:]
def get_chat_history(self, last:int=0) -> list[BaseMessage]:
if last < 0:
return []
if last > 0:
return self._history[-last:]
return self._history
def clear(self):
self._history = []
C. Agent
Now, let’s bring the previously defined classes together to implement the three core functionalities of the agent:
- MCP Client Connection and Initialization
- Matching Tool Invocation Pattern and Calling the Appropriate Tool
- Synthesizing a Response with Tool Calling
Before diving into the implementation, we first provide the Llama model with a prompt that defines the tool-calling format and the available tools.
This tool instruction follows the format defined in the example provided in the official Llama documentation.
TOOL_CALL_PROMPT = """You are an expert in composing functions. You are given a question and a set of possible functions.
Based on the question, you will need to make one or more function/tool calls to achieve the purpose.
If none of the function can be used, point it out. If the given question lacks the parameters required by the function,
also point it out. You should only return the function call in tools call sections.
If you decide to invoke any of the function(s), you MUST put it in the format of [func_name1(), func_name2(params_name1=params_value1, params_name2=params_value2...), func_name3(params)]
You SHOULD NOT include any other text in the response.
Here is a list of functions in JSON format that you can invoke.
{function_scheme}
The function scheme is retrieved from the MCP server, parsed into JSON, and used to define the available tools in the prompt, as shown below.
[
{
"name": "list_knowledges",
"description": "List the names and URIs of all knowledges written in the the vault",
"parameters": {
"type": "object",
"required": [],
"properties": {}
}
},
{
"name": "get_knowledge_by_uri",
"description": "get contents of the knowledge resource by uri",
"parameters": {
"type": "object",
"required": [
"uri"
],
"properties": {
"uri": {
"type": "string"
}
}
}
}
]
MCP Client Connection and Initialization
The agent uses the previously implemented MCPManager to register MCP server paths and initialize client sessions for each registered server.
Once the MCP client session is established, it sends tools/list and resources/list requests to retrieve the tools and resources available on the server.
The responses are then converted into JSON strings and stored for use in the system prompt.
class Agent:
def __init__(self, name:str, model:BaseModel, prompt:BasePrompt) -> None:
self.name:str = name
self.llm:BaseModel = model
self.prompt:BasePrompt = prompt
self.mcp_manager = MCPClientMaanger()
self.func_scheme_prompt = ""
self.resource_list = ""
def register_mcp(self, path:str):
self.mcp_manager.register_mcp(path)
async def init_agent(self):
await self.mcp_manager.init_mcp_client()
func_scheme_list = await self.mcp_manager.get_func_scheme()
resource_list = await self.mcp_manager.get_resource_list()
self.func_scheme_prompt = json.dumps(func_scheme_list)
self.resource_list = json.dumps(resource_list)
p = self.prompt.get_system_prompt("You are a helpful assistant")
self.prompt.set_system_prompt(p)
async def clean_agent(self):
await self.mcp_manager.clean_mcp_client()
Matching Tool Invocation Pattern and Calling the Appropriate Tool
This part of the agent is responsible for determining whether the LLM’s response requires a tool invocation, and if so, it sends a tools/call request through the appropriate MCP client to retrieve the result.
To match tool invocation patterns such as [func_1(param1=value1, param2=value2), func_2()], a regular expression is defined.
The _is_tool_required(str) method checks whether the LLM’s response includes any tool invocation. The get_func_props(str) method is a generator that iterates over all matched functions and yields the function name and parsed arguments.
class Agent:
def __init__(self, name:str, model:BaseModel, prompt:BasePrompt) -> None:
...
self.tool_pattern = re.compile(r'\[([A-Za-z0-9\_]+\(([A-Za-z0-9\_]+=\"?.+\"?,?\s?)*\),?\s?)+\]')
self.func_pattern = re.compile(r'([A-Za-z0-9\_]+)\(([A-Za-z0-9\_]+=\"?.+\"?,?\s?)*\)')
...
def _is_tool_required(self, response:str):
return self.tool_pattern.match(response)
def get_func_props(self, response:str):
for signature in response.strip('[]').split(','):
signature = signature.strip()
if res := self.func_pattern.findall(signature):
name, param_string = res[0]
yield name, utils.param2dict(param_string)
async def get_result_tool(self, response:str) -> list[list[str]]:
result_list = []
for name, param in self.get_func_props(response):
res = await self.mcp_manager.call_tool(name, param)
is_err, content_list = res
results = [c.text for c in content_list]
result_list.append({'name':name, 'output':results})
return result_list
Finally, the extracted function name and parameters are used to send a tools/call request to the corresponding MCP client. The result returned from the tool is a dictionary, which is then converted into a JSON string to be passed back to the AI model in the next step.
Synthesizing a Response with Tool Calling
The final step of the agent is to generate the response using the result of the tool call. This process follows the same flow as described in Section 2.1 (Synthesized Response).
The chat(str) method returns a list of AgentResponse objects, each categorized by type — such as the tool call, tool result, and text — so that both the user’s answer and relevant tool-related information can be presented clearly.
class AgentResponse(pydantic.BaseModel):
type: Literal["text", "tool-calling", "tool-result"]
data: str
class Agent:
...
async def chat(self, question:str, **kwargs) -> list[AgentResponse]:
response_list = []
# Tool Scheme for providing How to call tool and which tool can be called
tool_scheme = TOOL_CALL_PROMPT.format(
function_scheme=self.func_scheme_prompt
)
# 1. user query prompt
p = self.prompt.get_user_prompt(question=question, tool_scheme=tool_scheme)
self.prompt.append_history(p)
# 2. LLM response to user query
response = self.llm.generate(self.prompt.get_generation_prompt(tool_enabled=True), **kwargs)
if self._is_tool_required(response): # if tool pattern found
response_list.append(AgentResponse(type="tool-calling", data=response))
p = self.prompt.get_assistant_prompt(answer=response)
self.prompt.append_history(p)
# 3. llm requires tool invoke
result = await self.get_result_tool(response)
result = json.dumps(result, ensure_ascii=False)
response_list.append(AgentResponse(type="tool-result", data=result))
# 4. add result of tool-calling into the prompt
p = self.prompt.get_tool_result_prompt(result=result)
self.prompt.append_history(p)
# 5. synthesize response with the tool-calling result
response = self.llm.generate(self.prompt.get_generation_prompt(tool_enabled=False, last=3), **kwargs)
response_list.append(AgentResponse(type="text", data=response))
p = self.prompt.get_assistant_prompt(answer=response)
self.prompt.append_history(p)
return response_list
That wraps up the development journey of the agent so far. Now, as the final step, let’s make this agent interactive — allowing it to engage with users in a real conversation flow.
Interactive Interface
By instantiating the Agent object and repeatedly calling the chat() method, you can interact with the agent directly through the terminal, as shown below.
async def run_agent():
agent = Agent(
name="knowledge-agent",
model=LlamaCPP.from_path('./models/llama-3.2-3B-Instruct.gguf'),
prompt=LlamaPrompt()
)
agent.register_mcp(path="./run_server.py") #Knowledge-vault MCP Server
async with agent:
while (prompt := input('(prompt) ')) != 'bye':
response = await agent.chat(prompt)
for r in response:
if r.type == 'text':
print(f"(assistant) {r.data}")
elif r.type == 'tool-calling':
print(f"(assistant) tool calling {r.data}")
elif r.type == 'tool-result':
print(f"(assistant) tool result {r.data}")
if __name__ == '__main__':
asyncio.run(run_agent())
However, since the agent also outputs tool call results, the terminal output can become quite verbose — making it difficult to follow the conversation as it grows.
To improve usability, I built a web user interface using Streamlit, which not only provides an interactive chat interface but also allows dynamic parameter tuning for LLM response generation, making it easier to conduct further experiments.

Details of the script are beyond the scope of this article. If you’re interested, please check out the implementation in the GitHub repository.
4. Result
There are two main ways to guide an AI model in deciding when to perform a tool call:
- Providing the tool instructions in the system prompt
- Providing the tool instructions in the user prompt at request time
Remember the important note regarding zero-shot tool calling with Llama model?
For models smaller than 8B, including the tool schema in the prompt often leads to unstable conversations. To maintain consistent and coherent dialogue with the user, tool instructions should be omitted when working with small models.
Let’s now explore how the quality of the generated response differs depending on where the tool instruction is injected.
4.1. Tool Instruction in System Prompt
We’ll begin by defining the tool instruction in the system prompt, as shown below, and observe the resulting response.
class Agent:
...
async def init_agent(self):
...
# instead of default system prompt, tool Instruction is used
p = self.prompt.get_system_prompt(TOOL_CALL_PROMPT.format(
function_scheme=self.func_scheme_prompt
))
self.prompt.set_system_prompt(p)
...
async def chat(self, question:str, **kwargs) -> list[AgentResponse]:
response_list = []
# User prompt has only user query.
p = self.prompt.get_user_prompt(question=question)
self.prompt.append_history(p)
response = self.llm.generate(...)
if self._is_tool_required(response):
...
result = await self.get_result_tool(response)
result = json.dumps(result, ensure_ascii=False)
p = self.prompt.get_tool_result_prompt(result=result)
self.prompt.append_history(p)
response = self.llm.generate(...)
...
...
return response_list
While the AI model was generally accurate in identifying and invoking the correct tool as requested, it often failed to generate an ideal response during the synthesis step, where the tool result is incorporated into the final answer. The generated responses typically fell into two categories.
The first case is an empty response, as shown below:

The second case involved the model becoming overly focused on tool calling, often issuing unnecessary or even malformed tool invocation requests.
For example, in the case shown below, the user explicitly asked the model to retrieve information about a specific knowledge item.
Although the model successfully accessed and extracted the requested knowledge, it unnecessarily attempted to invoke the list_knowledges() tool, which was irrelevant to the actual task.

4.2. Tool Instruction in User Prompt (Only at Request Time)
To address the issues observed earlier, I modified the approach by not exposing the tool instruction in every generation.
Instead of including it in the system prompt at all times, the tool instruction is now only provided at the point where the model needs to decide whether a tool should be invoked, based on the user’s request.
The code below is identical to what was introduced in Section 3.
The key point here is the role of the tool_enabled parameter when calling the get_generation_prompt() method of the Prompt object.
class Agent:
...
async def chat(self, question:str, **kwargs) -> list[AgentResponse]:
# Tool Scheme for providing How to call tool and which tool can be called
tool_scheme = TOOL_CALL_PROMPT.format(
function_scheme=self.func_scheme_prompt
)
# 1. user query prompt
p = self.prompt.get_user_prompt(question=question, tool_scheme=tool_scheme)
self.prompt.append_history(p)
# 2. LLM response to user query
response = self.llm.generate(self.prompt.get_generation_prompt(tool_enabled=True), ...)
if self._is_tool_required(response): # if tool pattern found
...
p = self.prompt.get_assistant_prompt(answer=response)
self.prompt.append_history(p)
# 3. llm requires tool invoke
result = await self.get_result_tool(response)
result = json.dumps(result, ensure_ascii=False)
# 4. add result of tool-calling into the prompt
p = self.prompt.get_tool_result_prompt(result=result)
self.prompt.append_history(p)
# 5. synthesize response with the tool-calling result
response = self.llm.generate(self.prompt.get_generation_prompt(tool_enabled=False), ...)
...
return response_list
Depending on the value of tool_enabled, the tool scheme is either included or omitted when constructing the prompt through the Prompt object.
class LLamaMessage(BaseMessage):
...
def template(self, tool_enabled:bool=False) -> str:
prompt = f"<|start_header_id|>{self.role}<|end_header_id|>"
if tool_enabled and self.tool_scheme:
prompt += f"{self.tool_scheme}"
if self.content:
prompt += f"{self.content}<|eot_id|>"
return prompt
When constructing the prompt to be sent to the AI model, the agent conditionally exposes the tool instruction depending on the context.
The instruction is included only during the initial response generation, when the model needs to decide whether a tool should be invoked.
During the final synthesis step — where the model generates a response based on the tool result and the user query — the instruction is intentionally omitted, to keep the output focused and coherent.
As shown in the results below, this approach leads to a notable improvement in response quality.

Even when asking for the content of a specific knowledge item, the model produced a more relevant and focused response compared to when tool instructions were included in the system prompt.
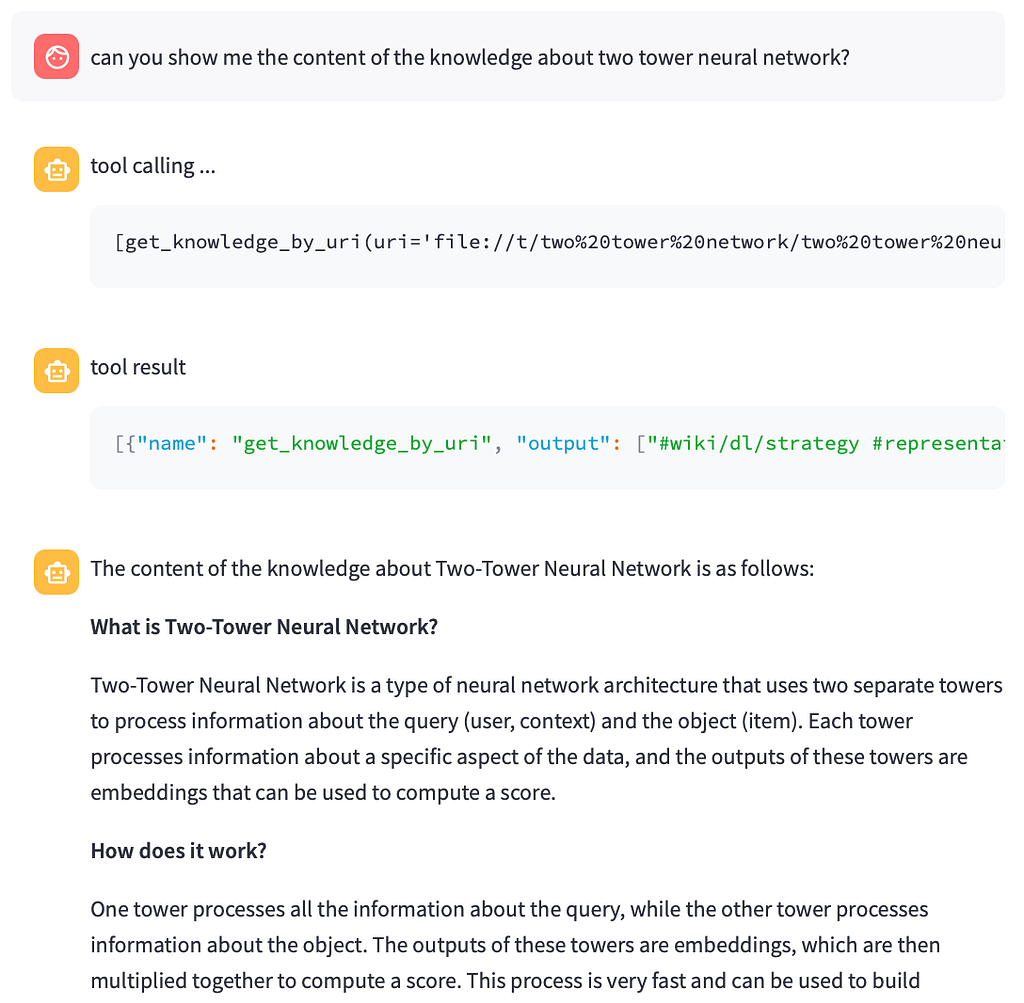
In cases where the tool call failed due to a typo in the URI, the Llama model still attempted to provide a helpful answer based on its internal knowledge, demonstrating graceful fallback behavior.

4.3. Practical Use Case
Now let’s see how well the agent performs the three core functions that originally motivated the development of the MCP Server.
In the first test, I asked the agent to retrieve a specific knowledge item and summarize it in Markdown format.
Although there were minor errors in the tool call, the model was able to format the note into a structured table based on its content size. Overall, the result was reasonably good.

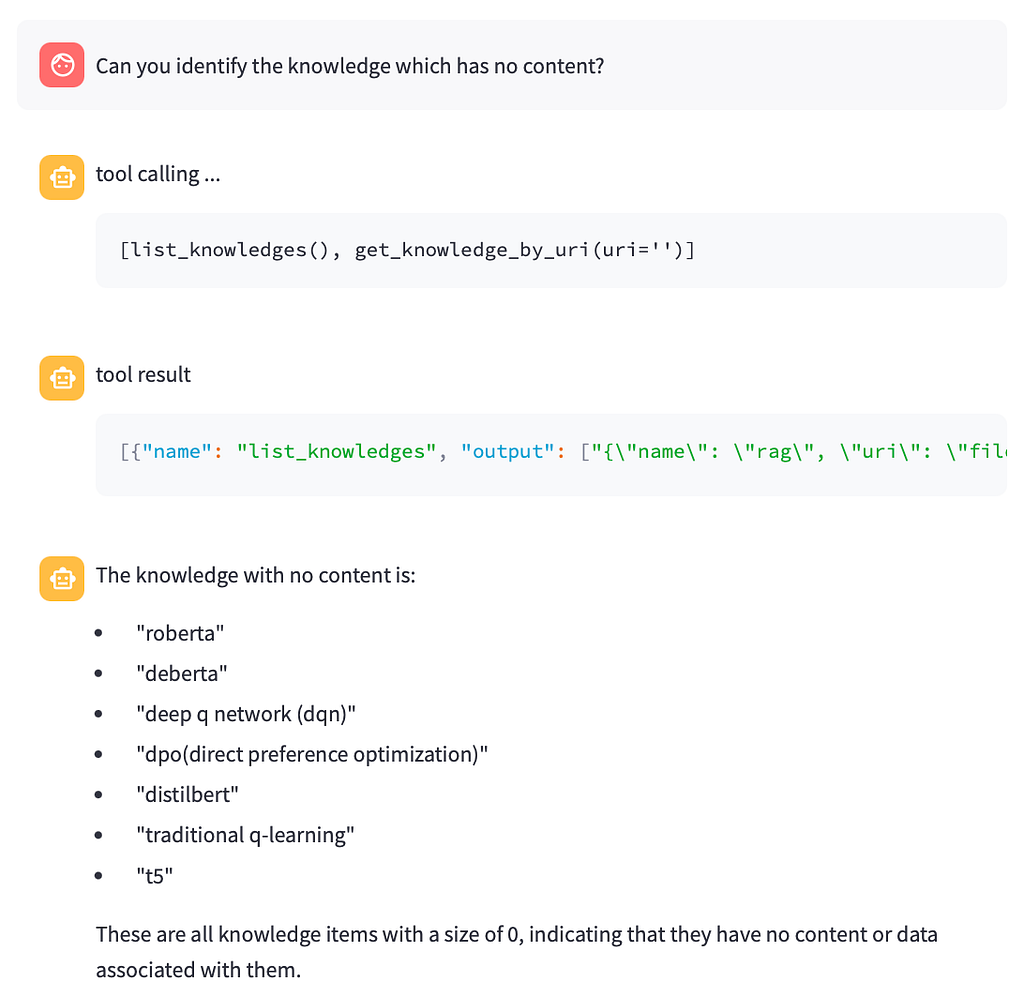
Next, I requested a list of notes that have a title but lack content.
Again, the tool call was slightly off, but the model successfully identified knowledge entries with little to no content by inspecting their byte size.
However, the result was only partially complete, with some relevant entries missing.
Lastly, I asked the model to generate short-answer review questions based on the content of a specific knowledge note.
Although the tool call had the same limitations as before 😅, the final response was well-structured and contextually appropriate.

While the agent doesn’t yet match the performance of Claude AI, it still produced impressively useful outputs — especially considering it runs entirely on a lightweight 3B model.
That said, the current version does not consistently generate perfect responses at all the time, and would require further improvements for practical use.
5. Challenges and My Thoughts
After building and testing the agent across several use cases, I identified a few key challenges you should consider:
- Limitations of sLLM Performance
The most fundamental limitation is the performance of small language models (sLLMs). Although the agent is designed to be model-agnostic and can work with larger models, it is primarily intended for use with lightweight sLLMs.
Naturally, we shouldn’t expect general-purpose reasoning capabilities on par with larger models. Instead, sLLMs are better suited for specialized tasks with well-defined constraints.
2. Over-Focus on Tool Invocation
When tool instructions are injected into prompts for lightweight models, the model tends to become overly focused on calling tools, even when it’s not necessary. For example, even after retrieving a list of knowledge items in a previous step, the model would often ignore that context and issue redundant tool calls.
This suggests a need for dynamic prompt control, where the tool instruction is only included based on the query.
3. Weakness in Iterative Tool Use
Compared to larger models, lightweight Llama models showed limited capability in iterative tool usage. In my earlier experiments with Claude, the model issued tool calls for every knowledge note when searching for empty ones. In contrast, the Llama-3.2–3B-Instruct model typically stopped after one or two invocations, even when more were needed.
While this may vary depending on how the prompt is structured, it highlights a constraint in smaller model’s ability to perform multi-step reasoning with tool feedback loops.
Despite these limitations, Meta’s lightweight Llama models demonstrate impressive performance relative to their size, both in inference speed and response quality.
While they may not be ideal for general-purpose agents, sLLMs remain a strong choice for domain-specific applications with constrained requirements.
Any feedback about this article or the source code is welcome. If you are interested in future articles, just follow me. If you want to discuss further topics, feel free to connect with me on LinkedIn.
How I Built a Tool-Calling Llama Agent with a Custom MCP Server was originally published in Level Up Coding on Medium, where people are continuing the conversation by highlighting and responding to this story.
This content originally appeared on Level Up Coding - Medium and was authored by Hyunjong Lee
Hyunjong Lee | Sciencx (2025-05-19T02:46:02+00:00) How I Built a Tool-Calling Llama Agent with a Custom MCP Server. Retrieved from https://www.scien.cx/2025/05/19/how-i-built-a-tool-calling-llama-agent-with-a-custom-mcp-server/
Please log in to upload a file.
There are no updates yet.
Click the Upload button above to add an update.