
This content originally appeared on Level Up Coding - Medium and was authored by Rahul Suresh

In my previous article, I discussed how Vibe coding is rapidly transforming development workflows, enabling experienced engineers to become significantly more productive. While not yet mature enough for deploying production-ready code directly, Vibe coding has proven invaluable for quickly prototyping and iterating complex applications, provided you approach it with the right mindset and methodology.
I recently challenged myself to build an entirely local, offline GPT-style assistant powered by Retrieval-Augmented Generation (RAG), which I named DeskRAG, within a single afternoon (roughly four hours). My goal was twofold:
- Create a personalized offline AI assistant for quickly searching, querying, and summarizing documents on my laptop.
- Carefully document the entire end-to-end vibe-coding workflow I used in building it, using Cursor powered by Claude 3.5 and 3.7.
In this article, I will walk you through how I built DeskRAG, highlighting key architectural choices and technical considerations. I’ll also share insights into how I shifted into a guiding role, like a program manager or software architect, mentoring my AI assistant through iterative coding cycles, reviewing, refining, and improving the application. I’ll discuss what worked well, what didn’t, and some best practices.
Motivation: Why DeskRAG?
The goal of this project is simple: I wanted to demonstrate how quickly and easily you can build your own GPT-like assistant that runs entirely locally on your laptop. While I regularly use- and love- various cloud-based language models, there are many situations where uploading sensitive or personal documents to a third-party service just isn’t ideal. I often wish that I had a completely local solution that allows me to retain full control over my data and privacy.
For example, you might want to:
- Quickly find specific information or details buried inside hundreds of personal documents without manually scanning each one.
- Instantly summarize long reports, research papers, or notes saved on your laptop, without uploading them anywhere.
- Search through private documents such as financial statements, medical records, or contracts safely and privately.
- Answer specific questions about local files, notes, or meeting minutes instantly, without leaving your desktop.
- Create a secure personal knowledge-base or local reference assistant customized exactly to your preferences.
These are exactly the types of privacy-sensitive I wanted DeskRAG to handle. Sure, there are many existing applications and open-source code bases that can run AI assistants locally, but building my own meant complete control. I could select the exact models, architecture, and features I wanted, all customized to run perfectly offline on my laptop. Plus, it seemed like a great way to spend an afternoon and have fun along the way!
While I’ll use DeskRAG as the example throughout this article, the concepts and architecture I discuss here are broadly applicable to any privacy-driven, local AI assistant use case.
Let’s dive in!
High-Level Architecture
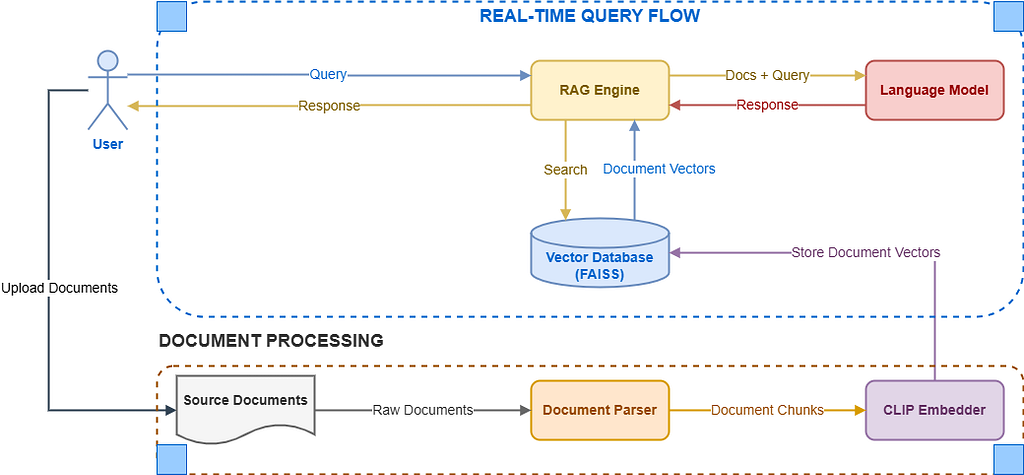
The main workflow for DeskRAG is straightforward and consists of five core steps:
- Select Documents:
Choose individual files or entire folders on your laptop to create your personal knowledge base (PDF, DOCX, TXT, Markdown, images). - Process and Generate Embeddings:
Parse documents into manageable chunks of text or image data, then convert them into numeric multimodal embeddings using CLIP. - Store Embeddings:
Store embeddings locally in a high-performance FAISS vector database for fast and efficient retrieval. - User Query via Selected Language Models:
Select from various supported quantized language models (Falcon, Mistral, TinyLlama, Phi-2, Llama-7B) and enter your queries in the DeskRAG interface. - Retrieve and Respond:
Retrieve relevant document chunks from FAISS, create a contextual prompt, and generate a response locally using your chosen Language Model. Responses include citations linking directly back to source documents.
Below are detailed sequence diagrams explaining the document ingestion and query flows.


Tools and Frameworks
The table below summarizes each key architectural component, along with the selected tools, reasoning behind these choices, and alternatives I considered during design.

Key Trade-Offs and Considerations
Of course, the architecture outlined above reflects the final choices I made for DeskRAG. However, as with any software architecture, each component typically comes with multiple viable options, and there’s rarely a single “best” answer that fits all scenarios. The decisions you make must ultimately align with your specific use case, constraints, and goals. With that in mind, I wanted to share some insights into my own thought process and explain the key factors and trade-offs I considered while choosing among different architectural components.
1. Embedding Model Selection
When selecting an embedding model, the key considerations you must consider are:
- Embedding quality (high retrieval accuracy)
- Multimodal capability (text and image support)
- Efficiency through quantization (for local GPU execution)
- Open-source availability and widespread adoption
Considering these factors, I chose CLIP (ViT-B/32, 8-bit quantized) because it produces unified embeddings for both text and images, supporting potential future image-based queries. Its quantization capability ensures efficient local execution on my RTX 4070 GPU.
Another great option is Sentence Transformers based embeddings, which excel specifically at text-only tasks and can sometimes offer better performance for purely textual content.
You can also consider other alternatives, including specialized encoders for text (e.g., BERT-based models) and images (e.g., ResNet embeddings). However, these approaches would have increased complexity and maintenance overhead without sufficient benefit given DeskRAG’s scope.
2. Vector Storage
Here are some factors I considered when choosing a vector storage:
- Open-source, mature, and widely adopted
- Fast local retrieval performance
- Easy integration with Python and Hugging Face ecosystem
- Efficient local resource consumption (memory and disk usage)
Given these requirements, I selected FAISS, a widely recognized industry standard vector database developed by Meta, primarily because it offers exceptional retrieval performance, easy Python integration, and minimal complexity for local storage scenarios. FAISS is specifically optimized for high-speed vector searches on CPUs and GPUs, making it ideal for DeskRAG’s offline, lightweight use case.
There are many other popular vector databases, and they all have their pros and cons. Chroma, Qdrant, Pinecone, OpenSearch, ElasticSearch, and Redis all offer a wide range of features to create, store, and retrieve embeddings, some of which also allow you to run locally. If you prefer any of these other vector databases, you can use them instead for your use case.
FAISS was ultimately the most practical, efficient, and optimal solution for this problem, given DeskRAG’s local execution and simplicity requirements.
3. Language Model Choices
Language Models supporting DeskRAG should fulfill the following criteria:
- Compatibility with local GPU (RTX 4070, 12 GB VRAM)
- Model size and parameter count (directly affecting GPU memory and speed)
- Robust quantization support (4-bit quantization for local efficiency)
- Open-source availability, popularity, and ease of access via Hugging Face
- Good documented performance benchmarks
Keeping flexibility in mind, I chose to explicitly support and test several quantized language models: Falcon-7B-Instruct, Mistral-7B-Instruct, TinyLlama-1.1B, Phi-2, and Llama-7B. All these models comfortably fit within my RTX 4070 GPU memory, achieve inference speeds of a few seconds or less, and have strong community adoption, performance benchmarks, and Hugging Face availability. While I chose these models, DeskRAG’s architecture easily supports any Hugging Face transformer model meeting similar criteria.
4. Optimizations
To achieve optimal local performance, I implemented three primary optimizations:
Quantization: I applied 4-bit quantization for all language models (LLMs/SLMs) and 8-bit quantization for CLIP embeddings. Quantization significantly reduces memory usage and inference latency, enabling all chosen models to run comfortably on a consumer-grade GPU, such as my RTX 4070.
Embedding Caching: Embeddings are computed once and cached locally, eliminating redundant computations for frequently accessed documents. This dramatically reduces processing time during retrieval, especially after initial indexing is complete.
Built-in GPU and CPU Optimizations: Leveraged standard performance optimizations provided by PyTorch and Hugging Face Transformers, ensuring full utilization of available GPU resources for model inference and embedding generation. The FAISS retrieval process was also tuned to effectively utilize available CPU resources, balancing overall system load.
As a next step, I intend to enable FlashAttention, a high-performance transformer optimization known to further speed up inference.
My Workflow Using Vibe Coding
This project was one of those rare instances where I was able to move from idea to a fully functioning prototype in just a single afternoon session. The key enabler was Vibe coding, which allowed me to step away from directly writing every line of code and instead focus on clearly communicating my intent. Throughout the process, I wore two hats simultaneously: a software product manager, clearly defining the detailed functional requirements, and a software architect, specifying technical choices, key optimizations, and overall workflow.
I began by preparing a detailed initial prompt for Cursor (shared below), describing the functional requirements, the overall architectural vision, and the technical specifics like model selection, embedding strategy, and optimizations. After submitting this prompt, Cursor generated the first iteration of the codebase.
PRODUCT-LEVEL REQUIREMENTS
- Build a desktop application named DeskRAG that runs locally and lets users query, summarise, and retrieve information from personal documents stored on their machine, entirely offline.
DOCUMENT SELECTION AND INGESTION
- User can point the app at a single file or an entire folder.
- Supported formats: PDF, DOCX, TXT, Markdown, JPG, PNG.
- Each document is split into manageable chunks for downstream embedding.
FAST, ACCURATE LOCAL RETRIEVAL
- For every query, retrieve the most relevant chunks from the local vector store.
- Responses must cite the original document and exact page or image.
PRIVACY GUARANTEE
- No user data ever leaves the device.
- Internet connectivity is required only to download open-source models from Hugging Face; runtime queries and documents stay local.
CHAT-STYLE USER INTERFACE
- Lightweight desktop GUI shows ingestion progress, supports drag-and-drop, and streams answers back to the user.
ARCHITECTURAL AND TECHNICAL REQUIREMENTS
EMBEDDINGS
- Primary: CLIP ViT-B/32 (8-bit) for unified text + image embeddings.
- Optional: Sentence-Transformer model for text-only retrieval, switchable via config.
LANGUAGE MODELS
- Support 4-bit Falcon-7B-Instruct, Mistral-7B-Instruct, TinyLlama-1.1B, Phi-2, and Llama-7B.
- Architecture must allow other Hugging Face models with minimal changes.
OPTIMISATIONS
- Quantise LLMs to 4-bit and embeddings to 8-bit.
- Cache embeddings to avoid redundant work.
- Enable PyTorch and Transformers GPU optimisations.
- Keep code ready for FlashAttention (disabled for now on Windows).
VECTOR STORE
- Use FAISS for local similarity search because it is fast, lightweight, and well-supported for desktop environments.
DOCUMENT PARSING AND UI
- Select mature Python libraries with minimal setup for parsing and GUI.
HIGH-LEVEL WORKFLOW
- Document ingestion → Embedding generation → FAISS storage → User query → Retrieval → LLM generation with context → Streamed response to GUI with citations.
From there, I went through around 25 iterations, each short and interactive, initially to fix environmental setup and dependency issues, and later to debug, optimize, and refine the application. During these interactions, I transitioned from debugging initial errors to collaboratively refining the logic and ensuring system efficiency.
After debugging dependency and environmental issues, the DeskRAG’s responses were incorrect or irrelevant. A deeper look revealed that the embedding generation logic wasn’t correctly tied to the document parser, resulting in random embeddings. After highlighting this critical issue explicitly, Cursor corrected it quickly, significantly improving the application’s accuracy and response quality.
Ultimately, this iterative, conversational process allowed me to complete DeskRAG in just a few hours, far less than the multiple days such an effort typically demands.
Here are some key learnings using Vibe coding for this project:
- Be Explicit in Your Architectural Intent: It was crucial to clearly outline requirements and architectural decisions upfront. The more precise and explicit I was, especially around key technologies (like CLIP embeddings, FAISS database, and quantized models), the more accurate and relevant the generated code became. Conversely, vagueness led to unnecessary iterations and corrections.
- Expect Iteration and Debugging, Especially on Integration Points: Integration points between modules (e.g., embedding generation and document parsing, embeddings and the vector database) required the most debugging effort. Cursor’s generated code initially struggled with these connections, and significant interaction was needed before the code properly linked these critical modules. Paying close attention to these points early on would have saved considerable time.
- Prioritize Quick Environment and Dependency Checks: Initial interactions frequently revolved around environment setup and resolving dependency conflicts. Quickly establishing a stable environment (e.g., through Conda or Docker) and testing basic imports upfront significantly reduced friction later in the coding process.
- Collaborate and Iterate Rapidly for Optimizations: The iterative nature of Vibe Coding shines in performance tuning and optimization phases. Rather than manually tweaking code, conversationally exploring various optimizations (quantization, caching, GPU utilization) allowed me to quickly assess trade-offs and achieve substantial performance improvements in minimal time.
Implementation Details
As I have mentioned before, the entire code was generated by Cursor, powered by Claude 3.5 (and Claude 3.7 in some instances). Let us examine the final structure of code package generated by the tool:
deskrag/
├── src/
│ ├── core/
│ │ ├── config.py
│ │ ├── logging.py
│ │ └── rag_engine.py
│ ├── processors/
│ │ └── document.py
│ ├── models/
│ │ ├── embedding.py
│ │ └── llm.py
│ ├── db/
│ │ └── vector_store.py
│ └── ui/
│ ├── app.py
│ └── components.py
├── scripts/
│ └── download_models.py
├── tests/
│ └── test_rag.py
├── requirements.txt
└── README.md
- Configuration (src/core/config.py): Manages directories under ~/.deskrag, loads/saves JSON configuration, and tracks available models.
- Document Processing (src/processors/document.py): Reads PDFs, DOCX, text files, markdown, and images, splitting them into overlapping chunks for embedding. The process_file method dispatches to format-specific handlers.
- Vector Store (src/core/vector_store.py): Uses FAISS to store CLIP embeddings, including caching, batch processing, and optional index optimization.
- RAG Engine (src/core/rag_engine.py): Coordinates processing, embedding, storing, and querying. The query method retrieves relevant documents (via text or image search), assembles context, and asks the LLM to generate a response.
- Models (src/models/embedding.py and src/models/llm.py): Provide CLIP-based embeddings and an LLM interface with optional 4‑bit quantization and response caching.
- User Interface (src/ui/app.py, src/ui/components.py): Tkinter-based GUI with file selection, progress tracking, and a chat interface. DeskRAGApp initializes configuration and the RAG engine, and displays the main window.
- Scripts (scripts/download_models.py, scripts/cleanup_models.py): Utilities for downloading or cleaning up model files from Hugging Face.
Based on my observations above, after providing the initial prompt, the generated code structure and package organization appeared reasonable. The project was nicely separated into clean, logical units, with each module clearly having a focused responsibility. While I haven’t performed an in-depth, line-by-line code review yet, at a structural and functional level, I found the overall organization to be satisfactory for the purposes of this prototype.
Results

I primarily built DeskRAG to organize my personal documents and easily find answers to queries based on my local files. However, for the sake of demonstrating the capabilities here, I created a test folder with a selection of well-known research papers — including the original Transformer paper (“Attention is All You Need”), the ResNet paper (“Deep Residual Learning for Image Recognition”), and a few other classic research articles. I then ingested these papers into the system, asked specific questions related to their content, and captured some of the resulting responses, as shown above.
Clearly, the answers are not as sophisticated or nuanced as you’d expect from today’s frontier language models. But remember — DeskRAG runs entirely on small, quantized models with only around 7 billion parameters (or lower), suitable for a lightweight desktop environment. These models aren’t designed to handle extremely complex queries or intricate reasoning tasks. Instead, they’re optimized for straightforward questions and organizing information from your personal documents.
From that perspective, as your “personal GPT” focused on your own files and documents, the results are quite satisfactory. DeskRAG is intended to quickly and reliably handle routine document-search and organization tasks, and it performs those functions well.
In my very non-scientific latency measurements, I observed notable differences between models when asking similar queries about the ingested research documents — questions like “What is positional encoding?” or “Explain the attention mechanism,” or simple factual inquiries about paper results. On the lower end, Phi-2 and TinyLlama produced short, concise responses within roughly 1 to 2 seconds, but these answers were terse and lacked depth. At the other end, Falcon, Mistral, and Llama-7B provided richer, more detailed responses, but took significantly longer, approximately 8 to 10 seconds, to complete their answers. Among these, Falcon and Llama delivered the highest-quality results.
Moving forward, I’ll continue experimenting with different models, tweaking the embedding strategies, and refining the UX to make the app more functionally useful.
Conclusion
I was able to move from an idea to a working demo and a fully functional prototype in just a single afternoon- something that traditionally would have taken days or weeks. That itself was an incredible productivity boost. While the initial results look promising, DeskRAG remains primarily a fun, exploratory project for me right now. I plan to continue refining it, adding new features, and enhancing existing functionalities over time.
Have I thoroughly reviewed all the generated code line-by-line yet? Not completely. I’ve tested the basic functionality, verified key architectural components, and ensured that the prototype meets my initial requirements. However, if you ask whether I’d feel comfortable deploying this code in a production environment today, my answer is clearly “no.” To reach that point, the code would require careful unit testing, comprehensive end-to-end functional testing, thorough code reviews, and many other software development best practices. I plan to undertake all these steps before making this tool publicly available.
Yet, despite the remaining work ahead, the overall productivity gain remains substantial. Even considering the additional tasks required to make the code production-ready, I’ve already saved significant development time compared to building from scratch. And importantly, I now have a useful tool I’m actively enjoying and benefiting from each day — exactly the kind of outcome I’d hoped for.
What’s Next?
I do intend to make DeskRAG publicly available as an open-source project on GitHub in the near future. Before doing so, I’m currently in the process of adding more features, performing thorough code reviews, and extensive testing. I’ll post updates and announcements via new articles on Medium or my personal website — stay tuned!
Disclaimer The views and opinions expressed in my articles are my own and do not represent those of my current or past employers, or any other affiliations.
DeskRAG: Create an Offline AI Assistant in One Afternoon was originally published in Level Up Coding on Medium, where people are continuing the conversation by highlighting and responding to this story.
This content originally appeared on Level Up Coding - Medium and was authored by Rahul Suresh
Rahul Suresh | Sciencx (2025-05-20T12:04:34+00:00) DeskRAG: Create an Offline AI Assistant in One Afternoon. Retrieved from https://www.scien.cx/2025/05/20/deskrag-create-an-offline-ai-assistant-in-one-afternoon/
Please log in to upload a file.
There are no updates yet.
Click the Upload button above to add an update.