
This content originally appeared on DEV Community and was authored by Diego Pérez
What is this about?
MCP (Model Configuration Protocol) has been gaining attention lately, and it is something more people should be aware of. It has been on the radar for the past few months and is becoming a key part of how systems are built and integrated with AI, both now and in the future.
This post walks through the core ideas behind MCP and shows an implementation built using Spring IA and Java.
MCP and the Rise of a New AI Standard
Nowadays, there’s a wide variety of very powerful LLMs out there. However, a key component has long been missing: a standardized way to provide these models with access to data and functionality from our own systems. This capability is essential for fully leveraging the potential of these models and achieving truly meaningful things within specific business domains.
Because of this need, Anthropic, a very important emerging company in the field of AI development, has proposed a new open standard called the Model Context Protocol (MCP). You can think of it like other ways we share data and functionality between systems, such as REST APIs for exchanging resources and business logic, but in this case, it’s for sharing context with an LLM.
MCP makes it possible for LLMs to actually do useful things with real systems. Instead of giving surface-level responses, they can work with live business data, read files, follow instructions, and take real action. What used to be a basic chat becomes something much more interactive, like asking for a product and having it ordered for you, or triggering a business process with just a sentence and even get meaningful insights from your own data. The more systems you connect, the more creative and practical the use cases become.
MCP General Architecture

MCP Server: A backend program that exposes a variety of capabilities and data through the MCP protocol. It can connect to databases or other services to bring in useful features or information the model might need.
MCP Client: In a nutshell, it handles 1:1 communication with MCP Servers.
MCP Host: This is essentially an app used to interact with an LLM. Through that interaction, you can be able to access and use the different tools available behind MCP Servers. Some examples of MCP Hosts are Claude Desktop, Cursor, and OpenAI Agents SDK, and the list keeps growing.
MCP Transports
MCP is the protocol used for communication between the client and the server. At a high level, it relies on JSON-RPC 2.0 as the data exchange format. Basically, it’s responsible for translating MCP messages into JSON-RPC for transmission, and then converting the responses back into MCP messages on the way in. It’s the layer that makes everything flow between both sides.
At a high level, you can imagine this communication as illustrated below:

In practice there are two implementations of MCP standard transport protocol:
Standard Input/Output (STDIO): In this case communication happens through the standard input and output streams. It’s perfect for local setups, fast, efficient, and easy to wire together with low latency and minimal overhead.
Server-Sent Events (SSE): On the other hand, with SSE the server pushes responses using HTTP streaming, and the client sends requests via HTTP POST. SSE works great for remote servers, supports multiple users, and fits naturally into HTTP-based architectures.
One big difference worth pointing out is that when using STDIO, the client is the one that starts and stops the MCP server. That doesn’t happen with SSE, where the server just runs on its own and listens for requests.
What can we expose through an MCP server?
With MCP servers we have three primitives that we can expose:
Resources: Basically read-only data such as file images, logs, database info, or API responses. In summary, any kind of data you want to make available to the MCP client.
Prompts: These are reusable message templates that can be used to guide interactions. This is useful when you want to structure the way users interact and shape the workflows for those interactions.
Tools: This is where we really want to focus our attention, because it’s the most important and powerful primitive. Tools let us expose executable actions that can interact with our systems, perform tasks, and actually change the state of things. Basically, we can expose any functionality we want to our MCP client.
For further details please check: https://modelcontextprotocol.io/docs/concepts/transports
Building a MCP server with Spring IA
To put all this theory into practice the idea is to create an MCP server for a real use case.
There’s an official SDK for popular languages like Python, Java, and TypeScript, and plenty of community implementations for others. In this case, the Spring AI MCP implementation is the one being used. It works especially well for those already familiar with the Spring ecosystem.
Building a Tool to Interact with AWS S3
As an idea for an MCP server implementation, an interesting use case is to build a tool that allows users to interact with the AWS S3 service using natural language through an LLM. The goal is to enable the model to perform basic actions on this service, such as:
- List available S3 buckets
- List objects
- Get object metadata
- Upload an object
- Download an object
- Delete an object
The purpose is to expose these tools so an LLM can interact with the AWS service and perform actions on behalf of the user. To make this work, it is only necessary to provide some basic configuration, such as the access key, secret key, and the region of the AWS account to be used.
The idea is to connect this MCP server with tools like Cursor, enabling interaction with S3 buckets during development, all in one place. This avoids the need to switch to the AWS Console or use the AWS CLI for common tasks. Instead, everything can be done through prompts, in a much simpler and more integrated way.
For this use case, the STDIO transport is a great fit, and it is the one selected here. Since the only requirement is a process running locally that brings this functionality to the models, nothing more than that is needed.
Creating the Project
The first step is to generate the project using Spring Initializr. For this example, the configuration is as follows:

Configuring Project Dependencies
After generating the project, the necessary MCP dependencies will be included, assuming the MCP Server dependency was selected in Spring Initializr:
<properties>
...
<spring-ai.version>1.0.0</spring-ai.version>
</properties>`
<dependencyManagement>
<dependencies>
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-bom</artifactId>
<version>${spring-ai.version}</version>
<type>pom</type>
<scope>import</scope>
</dependency>
...
</dependencies>
</dependencyManagement>
<dependencies>
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-starter-mcp-server</artifactId>
</dependency>
...
</dependencies>
To access the AWS S3 service, the official Java SDK will be used. To enable this, the following dependency must be added by including the following in the pom.xml:
<properties>
...
<aws.sdk.version>2.31.39</aws.sdk.version>
</properties>
<dependencyManagement>
<dependencies>
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-bom</artifactId>
<version>${spring-ai.version}</version>
<type>pom</type>
<scope>import</scope>
</dependency>
...
</dependencies>
</dependencyManagement>
<dependencies>
...
<dependency>
<groupId>software.amazon.awssdk</groupId>
<artifactId>s3</artifactId>
</dependency>
</dependencies>
Configuring MCP Server (STDIO)
To configure the application as an MCP server using STDIO as the transport, the following settings should be added to the application.properties file:
spring.application.name=s3-toolbox-mcp-server
spring.ai.mcp.server.enabled=true
spring.ai.mcp.server.stdio=true
spring.ai.mcp.server.name=s3-toolbox-mcp-server
spring.ai.mcp.server.version=1.0.0
spring.ai.mcp.server.capabilities.tool=true
spring.ai.mcp.server.capabilities.resource=false
spring.ai.mcp.server.capabilities.prompt=false
# DISABLE Spring banner and console logging to keep STDIO clean for MCP JSON-RPC only.
spring.http.client.factory=simple
spring.main.banner-mode=off
spring.main.web-application-type=NONE
logging.pattern.console=
logging.file.name=.logs/s3-inspector-mcp-server.loglogging.pattern.console=
The config under spring.ai.mcp.server is the basic setup to enable our MCP server. For more details about these params, you can refer the official reference documentation.
Also, keep in mind there’s some extra configuration related to logging. We are basically turning off all console logging because the output should stay clean for MCP JSON-RPC interactions only. Any extra text printed to the output can break the connection between the server and the client. That’s why we’re sending all logging output to a file instead.
MCP Server Implementation
The project is organized like this:

This is a pretty common and self-explanatory way to structure Java projects with Spring. The only package that’s kind of new here is the tool package. That’s where we’re going to define our MCP primitives. In this case, the tools.
Below are the main code snippets from the implementation. Some boilerplate code, such as imports and exception handling, has been omitted to keep things simple and easier to follow.
Model: The following models help simplify data transport for some of the operations that will be exposed as MCP tools.
...
import org.springframework.ai.tool.annotation.ToolParam;
public record PutS3ObjectRequest(
@ToolParam(description = "Name of the target S3 bucket (e.g., 'my-bucket')")
String bucketName,
@ToolParam(description = "Optional path prefix/folder inside the bucket (e.g., 'invoices/2025/'). Leave empty or omit to upload to the bucket root.")
String prefix,
@ToolParam(description = "Filename to save in S3 (e.g., 'report.pdf')")
String fileName,
@ToolParam(description = "MIME type of the file (e.g., 'application/pdf', 'image/png')")
String contentType,
@ToolParam(description = "The file's binary content, provided as a Base64-encoded string and deserialized into a byte array")
String base64Content
) {
}
It is worth noting that in this case the @ToolParam annotation is used. This annotation is part of the MCP API and is useful for providing additional detail or context about an input parameter for a given tool.
public record PutS3ObjectResponse(String eTag) {
}
public record GetS3ObjectResponse(String fileName, byte[] content, String contentType) {
}
public record GetS3ObjectMetadataResponse(String contentType, Long contentLength, Instant lastModified, String eTag,
String storageClass, Map<String, String> customMetadata) {
}
Config:
The S3Client is configured as shown below. This client is used to perform the different actions against the AWS S3 service:
...
import software.amazon.awssdk.auth.credentials.DefaultCredentialsProvider;
import software.amazon.awssdk.services.s3.S3Client;
@Configuration
public class S3Config {
@Bean
public S3Client s3Client() {
return S3Client.builder()
.credentialsProvider(DefaultCredentialsProvider.create())
.build();
}
}
Please note that for this client to work, we need to configure the following environment variables:
- AWS_ACCESS_KEY_ID
- AWS_SECRET_ACCESS_KEY
- AWS_REGION
Service:
This layer contains the logic that interacts with the AWS S3 client to execute the defined operations.
public interface S3ActionsService {
List<String> listBuckets();
List<String> listObjects(String bucketName, String prefix);
GetS3ObjectMetadataResponse getObjectMetadata(String bucketName, String keyName);
PutS3ObjectResponse putObject(PutS3ObjectRequest putS3ObjectRequest);
GetS3ObjectResponse getObject(String bucketName, String key);
void deleteObject(String bucketName, String keyName);
}
Contract implementation:
@Service
@RequiredArgsConstructor
@Slf4j
public class S3ActionsServiceImpl implements S3ActionsService {
private final S3Client s3Client;
@Override
public List<String> listBuckets() {
final var response = s3Client.listBuckets();
return Optional.ofNullable(response.buckets())
.orElse(Collections.emptyList())
.stream()
.map(Bucket::name)
.collect(Collectors.toList());
}
@Override
public List<String> listObjects(final String bucketName, final String prefix) {
final var request = ListObjectsV2Request.builder()
.bucket(bucketName)
.prefix(prefix)
.build();
final var response = s3Client.listObjectsV2(request);
return Optional.ofNullable(response.contents())
.orElse(Collections.emptyList())
.stream()
.map(S3Object::key)
.collect(Collectors.toList());
}
@Override
public Map<String, Object> getObjectMetadata(final String bucketName, final String key) {
final var headFuture = CompletableFuture.supplyAsync(() -> {
var headRequest = HeadObjectRequest.builder()
.bucket(bucketName)
.key(key)
.build();
return s3Client.headObject(headRequest);
});
final var attrFuture = CompletableFuture.supplyAsync(() -> {
var attrRequest = GetObjectAttributesRequest.builder()
.bucket(bucketName)
.key(key)
.objectAttributes(ObjectAttributes.STORAGE_CLASS)
.build();
return s3Client.getObjectAttributes(attrRequest);
});
return headFuture.thenCombine(attrFuture, (headResponse, attrResponse) ->
new GetS3ObjectMetadataResponse(headResponse.contentType(), headResponse.contentLength(),
headResponse.lastModified(), headResponse.eTag(), attrResponse.storageClassAsString(),
headResponse.metadata())
).join();
}
@Override
public PutS3ObjectResponse putObject(final PutS3ObjectRequest putS3ObjectRequest) {
final var request = PutObjectRequest.builder()
.bucket(putS3ObjectRequest.bucketName())
.key(putS3ObjectRequest.prefix().concat(putS3ObjectRequest.fileName()))
.contentType(putS3ObjectRequest.contentType())
.build();
final var response = s3Client.putObject(request,
RequestBody.fromBytes(Base64.getDecoder().decode(putS3ObjectRequest.base64Content())));
return new PutS3ObjectResponse(response.eTag());
}
@Override
public GetS3ObjectResponse getObject(final String bucketName, final String key) {
final var request = GetObjectRequest.builder()
.bucket(bucketName)
.key(key)
.build();
final var responseBytes = s3Client.getObjectAsBytes(request);
final var metadata = responseBytes.response();
final var fileName = key.contains("/") ? key.substring(key.lastIndexOf("/") + 1) : key;
return new GetS3ObjectResponse(fileName, responseBytes.asByteArray(), metadata.contentType());
}
@Override
public void deleteObject(final String bucketName, final String key) {
final var request = DeleteObjectRequest.builder()
.bucket(bucketName)
.key(key)
.build();
s3Client.deleteObject(request);
}
}
Tool:
Since the goal in this case is to expose actionable operations that LLMs can use to perform the desired tasks, the @Tool primitive from the MCP API is used, as it is a better fit for this scenario.
You can think of these tool definitions like how we define @Controller classes for our REST APIs. In the end, it's the way we define the tools contract for our MCP server. In other words, the actions or capabilities that our service is going to offer. Please note that @Tool comes from the MCP API.
...
import org.springframework.ai.tool.annotation.Tool;
import org.springframework.ai.tool.annotation.ToolParam;
import org.springframework.stereotype.Component;
@RequiredArgsConstructor
public class S3Tool {
private final S3ActionsService s3ActionsService;
@Tool(name = "list_s3_buckets", description = "Lists all the s3 buckets for the given account.")
public List<String> listS3Buckets() {
return s3ActionsService.listBuckets();
}
@Tool(name = "list_s3_files", description = "Returns a list of object keys in the specified S3 bucket, optionally filtered by a prefix.")
public List<String> listS3Files(@ToolParam(description = "Name of the S3 bucket to search") String bucketName, @ToolParam(description = "Optional prefix to filter results (e.g. 'invoices/'). Use empty string or omit to list all objects.") String prefix) {
return s3ActionsService.listObjects(bucketName, prefix);
}
@Tool(name = "get_s3_object_metadata", description = "Retrieves metadata (e.g., size, content-type, last modified) for the specified S3 object.")
public GetS3ObjectMetadataResponse getS3ObjectMetadata(@ToolParam(description = "Name of the S3 bucket containing the object") String bucketName, @ToolParam(description = "Key (path and filename) of the S3 object to retrieve metadata for") String key) {
return s3ActionsService.getObjectMetadata(bucketName, key);
}
@Tool(name = "put_s3_object", description = "Upload file bytes to S3 with optional prefix, returning ETag")
public PutS3ObjectResponse putS3Object(PutS3ObjectRequest putS3ObjectRequest) {
return s3ActionsService.putObject(putS3ObjectRequest);
}
@Tool(name = "get_s3_object", description = "Download an object from S3 by bucket name and key, returning its content and metadata such as content type, size, and ETag.")
public GetS3ObjectResponse getS3Object(@ToolParam(description = "The name of the S3 bucket where the object is stored.") String bucketName,
@ToolParam(description = "The full key (path/filename) of the object to retrieve.") String key) {
return s3ActionsService.getObject(bucketName, key);
}
@Tool(name = "delete_s3_object", description = "Delete an object from S3 by bucket name and key. Returns DeleteMarker and VersionId if applicable.")
public void deleteS3Object(@ToolParam(description = "Name of the S3 bucket that contains the object to delete.") String bucketName, @ToolParam(description = "Key (path/filename) of the object to delete from the bucket.") String key) {
s3ActionsService.deleteObject(bucketName, key);
}
}
Here it is important to note the use of the following annotations:
@Tool: This one is used to define a specific tool we want to expose.
@ToolParam: With this annotation, we can give more details about the input parameters of a tool.
It is key to write clear descriptions for both the operations and their parameters. The clearer they are, the fewer misunderstandings the models will have when trying to use them.
In you want to explore this annotations in more detail please refer to: https://docs.spring.io/spring-ai/reference/api/tools.html/.
Finally, once the tool is created, the following configuration should be added. This ensures that Spring AI wraps the S3Tool as a ToolCallback. By defining it as a bean, the MCP server automatically registers it and makes the tool available for invocation.
package com.github.dvindas.mcpserver.s3toolbox.config;
import com.github.dvindas.mcpserver.s3toolbox.tool.S3Tool;
import org.springframework.ai.support.ToolCallbacks;
import org.springframework.ai.tool.ToolCallback;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import java.util.List;
@Configuration
public class MCPConfiguration {
@Bean
public List<ToolCallback> registerTools(S3Tool S3Tool) {
return List.of(ToolCallbacks.from(S3Tool));
}
Wiring Up Cursor with Our MCP Server
In this case, given the nature of this MCP server, the connection will be made to Cursor. This setup enables seamless interaction during development, although it could also be connected to Claude Desktop or any other host that supports the standard.
1- To do this, go to File > Preferences > Cursor Settings. There, we’ll see something like this:

2- Then, go to the MCP tab and click the Add new global MCP server button.

3- Once you click that button, Cursor will open the mcp.json config file, where we’re going to configure our MCP server as follows:
{
"mcpServers": {
"s3-toolbox-mcp-server": {
"command": "java",
"args": [
"-jar",
"PATH_TO_MCP_SERVER_JAR\s3-toolbox-mcp-server-1.0.0.jar"
],
"env": {
"AWS_ACCESS_KEY_ID": "access_key_id",
"AWS_SECRET_ACCESS_KEY": "secret_access_key",
"AWS_REGION": "us-east-1"
}
}
}
}
After adding this config, the MCP server should appear as active in Cursor:

With that in place, the tools are ready to use directly from Cursor. No additional setup is needed.
MCP Tool Discovery Flow
Now, a high-level overview of what happens once the MCP server is configured:
1- Cursor reads the config from mcp.json and starts the MCP server process locally based on the command provided. If there are environment variables defined, those will be added to the process environment when it runs.
2- After that, the MCP client sends a JSON-RPC initialize request. In this case, this request is used to check the protocol version and capabilities like Resources, Prompts, and Tools. Once that's done, the session with the server is considered started.
3- If the Tools capability is enabled, the client then makes a JSON-RPC 2.0 call to tools/list to discover which tools the MCP server is exposing.
4- After this flow is completed, the client knows all the available tools and how to call them. The session stays open, ready to handle calls and interactions through JSON-RPC.
If you want more details about this flow, refer to the official reference documentation: https://modelcontextprotocol.io/docs/concepts/architecture#connection-lifecycle
Showing the S3 Toolbox MCP Server in Action
The images below show how these tools operate directly within the Cursor chat interface:
Listing S3 Bucket
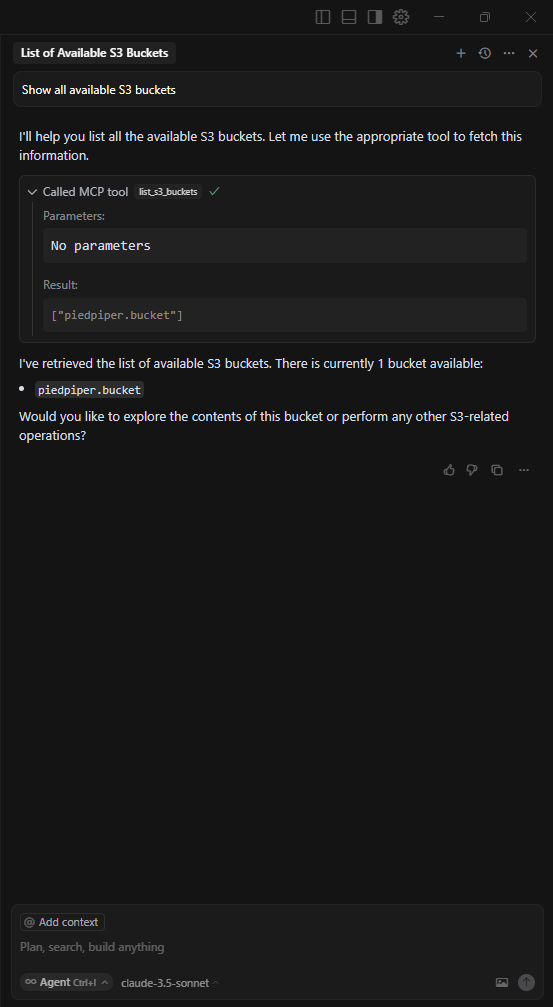
Putting an S3 Object

Listing S3 Objects
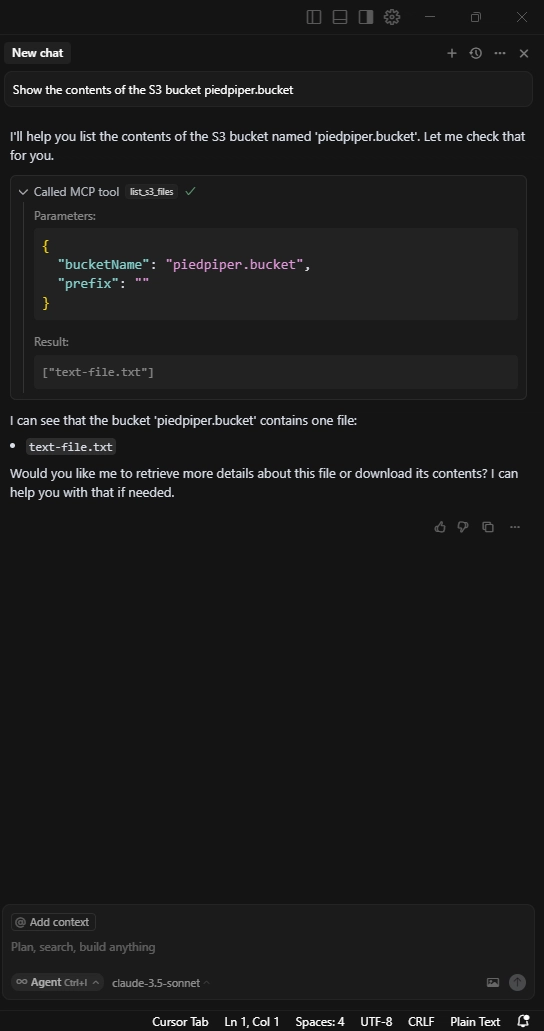
Getting object metadata
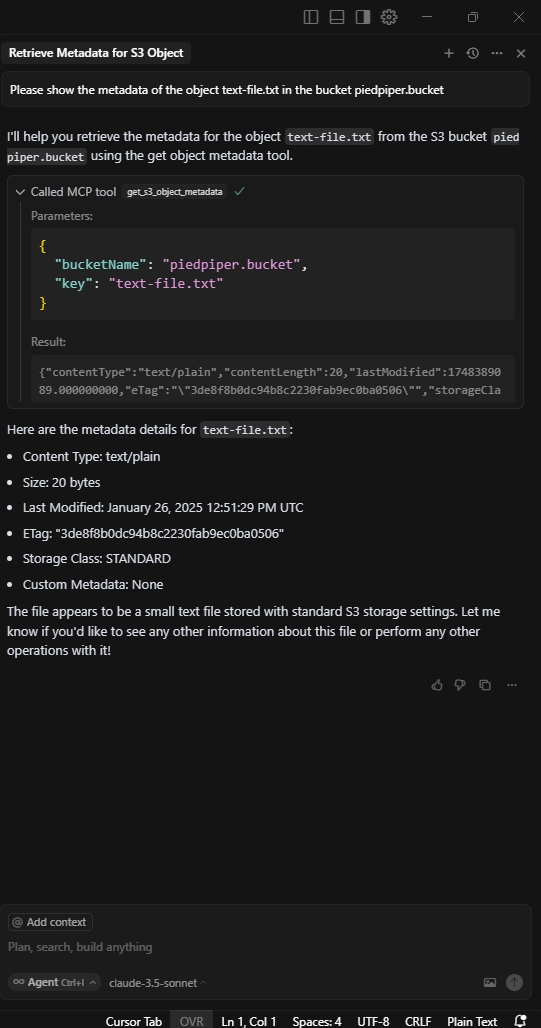
Getting an S3 Object
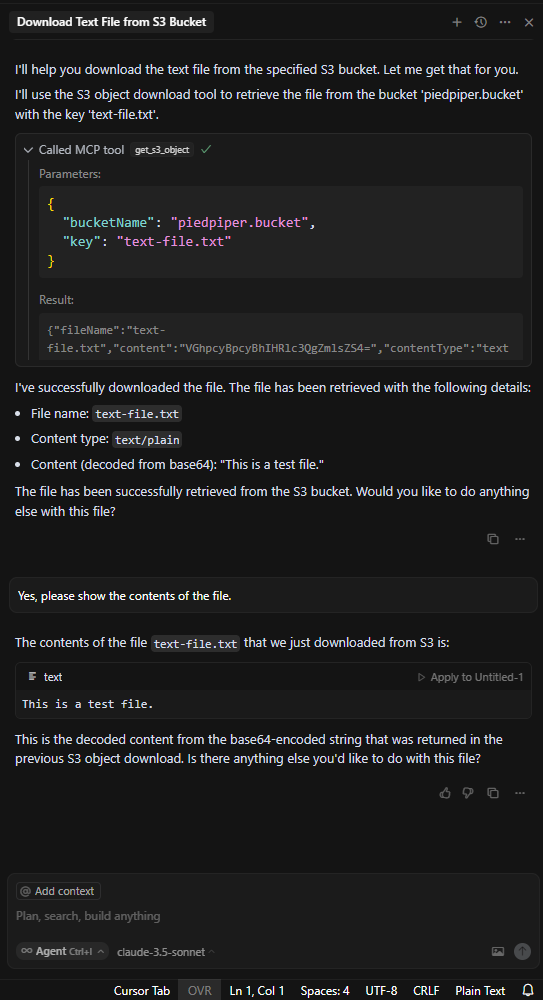
Deleting an S3 Object

Summary
All in all, standards in technology are always a good thing. Without them, everyone starts doing things their own way. For example, when it comes to adding tools to an LLM, there are many different approaches. Some models let you register API endpoints directly and configure functionality that way. But with this open standard from Anthropic, they’re basically saying: here’s a clean and consistent way to do it, built on good practices.
The adoption of this standard is growing, and several native integrations have already been announced, which is great to see. More and more services are starting to create and publish their own MCP servers as a new way to expose and interact with their features. One example of this is GitHub. Another cool thing is that there’s now an active and growing community behind this standard. There’s even a marketplace for MCP servers: https://mcpmarket.com/
Show Me the Code
The full code for this article is available here: https://github.com/dvindas/s3-toolbox-mcp-server.
This content originally appeared on DEV Community and was authored by Diego Pérez
Diego Pérez | Sciencx (2025-05-28T01:08:54+00:00) Model Context Protocol (MCP): An Open Standard for Connecting LLMs to Business Context. Retrieved from https://www.scien.cx/2025/05/28/model-context-protocol-mcp-an-open-standard-for-connecting-llms-to-business-context/
Please log in to upload a file.
There are no updates yet.
Click the Upload button above to add an update.