
This content originally appeared on HackerNoon and was authored by Text Generation
Table of Links
2 Background
2.2 Fragmentation and PagedAttention
3 Issues with the PagedAttention Model and 3.1 Requires re-writing the attention kernel
3.2 Adds redundancy in the serving framework and 3.3 Performance Overhead
4 Insights into LLM Serving Systems
5 vAttention: System Design and 5.1 Design Overview
5.2 Leveraging Low-level CUDA Support
5.3 Serving LLMs with vAttention
6 vAttention: Optimizations and 6.1 Mitigating internal fragmentation
6.2 Hiding memory allocation latency
7.1 Portability and Performance for Prefills
7.2 Portability and Performance for Decodes
7.3 Efficacy of Physical Memory Allocation
7.4 Analysis of Memory Fragmentation
7.2 Portability and Performance for Decodes
To evaluate decode performance, we focus on long-context scenarios (16K) because the latency of attention kernel becomes significant only for long contexts[4]. We evaluate the following configurations:
\ vLLM: We use vLLM v0.2.7 as the primary baseline. vLLM pioneered PagedAttention and uses a custom paged kernel for decodes, derived from FasterTransformer [4].
\
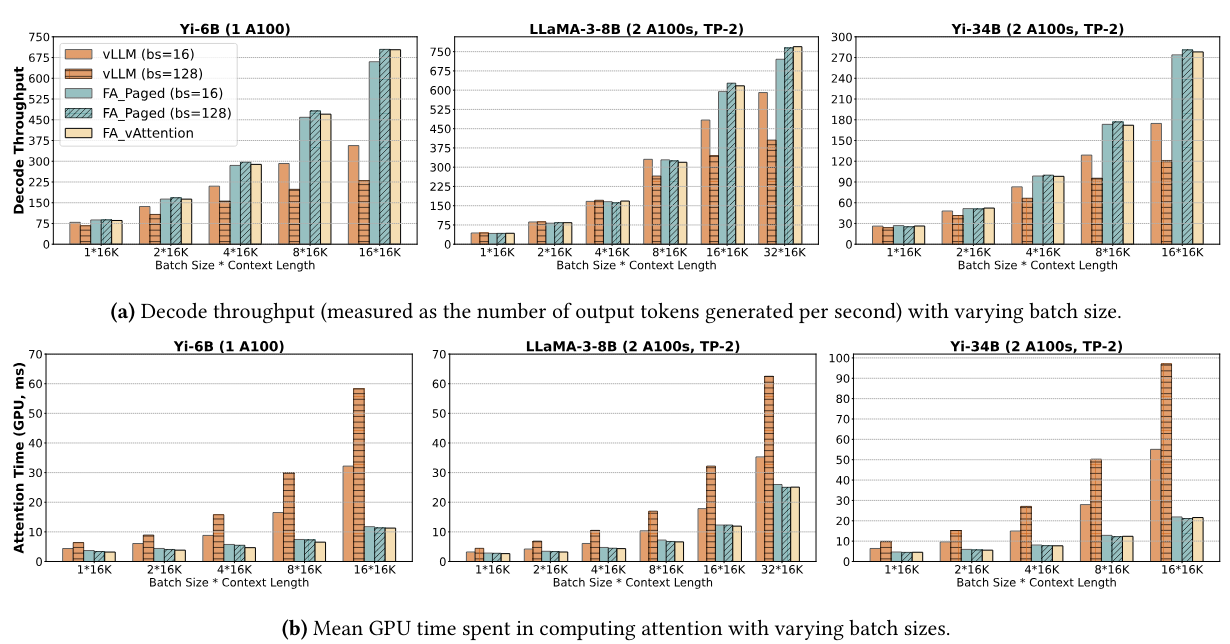
\ FA_Paged: For the second baseline, we integrate the FlashAttention kernel into vLLM’s serving stack. This represents a state-of-the-art PagedAttention kernel that includes optimizations such as sequence parallelism and in-place copy of new key and value vectors into the KV-cache. We evaluate the paged kernels of vLLM and FlashAttention with two different block sizes – 16 and 128 – to capture the effect of block size on performance.
\ FA_vAttention: For vAttention, we integrated the vanilla kernel of FlashAttention into vLLM’s serving stack. The kernel works with a virtually contiguous KV-cache to which we dynamically allocate physical memory using 2MB pages.
\ Figure 9a shows the decode throughput of Yi-6B, Llama3-8B and Yi-34B with varying batch sizes wherein the initial context length of each request is 16K tokens and we generate 256 tokens for each request. We compute decode throughput based on the mean latency of 256 decode iterations. We summarize the key takeaways below.
\ First, vAttention outperforms vLLM (both block sizes) and FAPaged (block size 16), while roughly matching the best configuration of FAPaged (block size 128). The maximum improvement over vLLM is 1.97× for Yi-6B, 1.3× for Llama3-8B and 1.6× for Yi-34B. The relative gains over vLLM also increase as the batch size grows. For example, the gain increases from about 1.1× to 1.97× as batch size increases from 1 to 8 for Yi-6B. This is because the latency of attention computation grows proportional to the total number of tokens in the batch (see Figure 9b) whereas the cost of linear operators remains roughly the same [25, 26, 41]. Therefore, the contribution of attention kernel in the overall latency – and subsequently gain with a more efficient kernel – increases with the batch size. While FAPaged (block size 128) provides similar gains as vAttention, note that FAPaged requires a new implementation of the GPU kernel whereas vAttention simply leverages the vanilla kernel of FlashAttention.
\ Second, Figure 9b confirms that performance difference between vLLM and FA_Paged/vAttention is indeed due to the attention kernels. In the worst case, the latency of vLLM’s best PagedAttention kernel (block size 16) is up to 2.85× higher for Yi-6B, up to 1.45× for Llama-3-8B and up to 2.62× for Yi-34B than the FlashAttention kernel.
\ Finally, throughput can be sensitive to block size even when memory capacity is not a constraint. For example, as discussed in §3.3, vLLM’s attention kernel has a significantly higher latency with block size 128 than with block size 16 (also see Figure 9b). In the worst case, block size 128 degrades vLLM’s throughput by 36%. While block size has a smaller
\
\
\ impact on FlashAttention, using a small block size can still hurt throughput due to CPU overheads, particularly due to the overhead of creating Block-Tables for every iteration (§3.3). For example, FlashAttention with block size 128 delivers 7% higher throughput than block size 16 for Llama-3-8B (531 vs 494 tokens per second with batch size 32).
\
:::info This paper is available on arxiv under CC BY 4.0 DEED license.
:::
[4] For short contexts, the computation time of the feed-forward-network dominates inference latency [25]
:::info Authors:
(1) Ramya Prabhu, Microsoft Research India;
(2) Ajay Nayak, Indian Institute of Science and Contributed to this work as an intern at Microsoft Research India;
(3) Jayashree Mohan, Microsoft Research India;
(4) Ramachandran Ramjee, Microsoft Research India;
(5) Ashish Panwar, Microsoft Research India.
:::
\
This content originally appeared on HackerNoon and was authored by Text Generation
Text Generation | Sciencx (2025-06-13T17:15:03+00:00) Boosting LLM Decode Throughput: vAttention vs. PagedAttention. Retrieved from https://www.scien.cx/2025/06/13/boosting-llm-decode-throughput-vattention-vs-pagedattention/
Please log in to upload a file.
There are no updates yet.
Click the Upload button above to add an update.