
This content originally appeared on HackerNoon and was authored by Writings, Papers and Blogs on Text Models
:::info Authors:
(1) Arkadiy Saakyan, Columbia University (a.saakyan@cs.columbia.edu);
(2) Shreyas Kulkarni, Columbia University;
(3) Tuhin Chakrabarty, Columbia University;
(4) Smaranda Muresan, Columbia University.
:::
:::tip Editor's note: this is part 5 of 6 of a study looking at how well large AI models handle figurative language. Read the rest below.
:::
Table of Links
- Abstract and 1. Introduction
- 2. Related Work
- 3. V-FLUTE Task and Dataset
- 3.1 Metaphors and Similes
- 3.2 Idioms and 3.3 Sarcasm
- 3.4 Humor and 3.5 Dataset Statistics
- 4. Experiments and 4.1 Models
- 4.2 Automatic Metrics and 4.3 Automatic Evaluation Results
- 4.4 Human Baseline
- 5. Human Evaluation and Error Analysis
- 5.1 How Do Models Perform According to Humans?
- 5.2 What Errors Do Models Make? and 5.3 How Well Does the Explanation Score Predict Human Judgment on Adequacy?
- 6. Conclusions and References
- A Dataset Statistics
- B API models Hyperparameters
- C Fine-tuning Hyperparameters
- D Prompts for LLMs
- E Model Taxonomy
- F By-Phenomenon Performance
- G Annotator Recruitment and Compensation
5 Human Evaluation and Error Analysis
We conduct human evaluation of generated explanation to more reliably assess their quality and identify key errors in multimodal figurative language understanding. We recruit two expert annotators with background in linguistics for the task and sample 95 random instances from the test set. For each instance, we first provide the annotators with the image, claim and reference explanation and ask the annotators to choose the right label. If the annotator succeeds, they can view the rest of the task, which consists of 3 explanations from our top models by F1@0 in each category: LLaVAeViL-VF, LLaVA-34B-SG, GPT-4-5shot. The explanations are taken for both correct and incorrect model predictions. For each explanation, we ask whether the explanation is adequate (accurate, correct, complete and concise). If not, we ask them to identify one of the three main types of errors based on the following taxonomy:
• Hallucination: explanation is not faithful to the image, indicating difficulties with basic visual comprehension (see prediction of a blunt tip when the pencil tip is actually sharp in row 1 of Table 5).
• Unsound reasoning: sentences do not adhere to natural logic or violate common sense (e.g., concluding than an upwards arrow and lots of money imply an economic crisis, see row 3).
• Incomplete reasoning: while overall the explanation makes sense, it does not address the key property reasons why the image entails or contradicts the claim (for example, does not address the figurative part in the image, see row 2).
• Too Verbose: the explanation is too verbose to the point it would interfere rather than help one decide the correct label.
5.1 How Do Models Perform According to Humans?
In Table 6, we show adequacy and preference rates for explanations from the 3 systems, where an explanation is deemed adequate if both annotators agreed it is, and inadequate if both agreed it is not. The preference percentage is also taken among instances where the annotators agreed that the model’s explanation is preferred among all the adequate explanations. The average IAA using Cohen’s κ is 0.47, indicating moderate agreement (Cohen, 1960). We observe that the teacher model is leading in terms of the adequacy of the explanations and preference rate, as expected from a larger system equipped for higher quality reasoning and generation capabilities. Yet still only half of its explanations are considered adequate. This further confirms that despite impressive performance on the F1@0 scores, the models are not yet capable of producing adequate textual explanations in many instances.
5.2 What Errors Do Models Make?
We also analyze to understand what type of errors do each model make when they are considered not adequate in the above evaluation. In Figure 7, we illustrate the normalized frequency of error types when both annotators agree that the explanation is not adequate (i.e., out of all errors for this model, what percentage is each type of error?). In general, annotators did not consider verbosity to be a
\

\
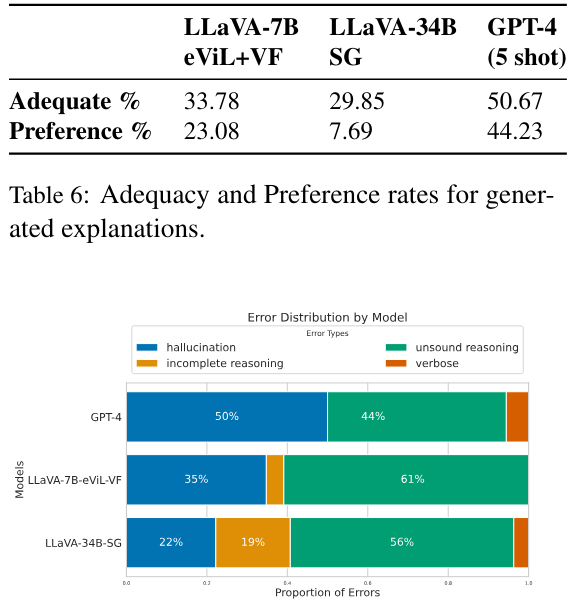
\ \ \ major issue of the systems. For GPT-4, the leading error type is hallucination, indicating the need to improve faithful image recognition even in the most advanced models. For the fine-tuned model and LLaVA-34B-SG, the main error type is unsound reasoning, indicating that it is challenging for the models to reason about multimodal figurative inputs consistently.
5.3 How Well Does the Explanation Score Predict Human Judgment on Adequacy?
We explore whether the proposed explanation score can capture human judgement of explanation adequacy. We collect all instances where both annotators agreed on the adequacy judgement for the explanation. We evaluate if the explanation score described in Section 4.2 can act as a good predictor for the human adequacy judgment. We find that the area under the Precision-Recall curve is 0.79, and the maximum F1 score is 0.77, obtainable at the explanation score threshold of 0.53. Hence, we use this threshold to report the results in Table 3. We also use the threshold of 0.6 since it maximizes F1 such that both precision and recall are above 0.75.
:::info This paper is available on arxiv under CC BY 4.0 DEED license.
:::
\
This content originally appeared on HackerNoon and was authored by Writings, Papers and Blogs on Text Models
Writings, Papers and Blogs on Text Models | Sciencx (2025-06-18T15:44:31+00:00) AI Still Can’t Explain a Joke—or a Metaphor—Like a Human Can. Retrieved from https://www.scien.cx/2025/06/18/ai-still-cant-explain-a-joke-or-a-metaphor-like-a-human-can/
Please log in to upload a file.
There are no updates yet.
Click the Upload button above to add an update.