
This content originally appeared on HackerNoon and was authored by Maksim Nechaev
Introduction
Hey everyone, I’m Max Nechaev - engineering manager at Snoonu, founder, and AI enthusiast. I’ve been in software development for quite a while. Back when I was building iOS apps, there were tons of architectural patterns out there. They felt solid. Thought through. Battle-tested over years. Back then, I never imagined I’d be the one creating a new architecture - especially not for AI systems.
But before we get to the solution, let’s talk about the problem.
Right now, AI is going through an insane hype cycle. Startups pop up and die every day. More and more people are diving into low-code and no-code tools like Make, n8n, and others. And you know what? I think that’s awesome. Millions of people are stepping into a new kind of reality. It feels like the early days of the internet, when websites went from static to interactive, and it suddenly felt like anything was possible.
More people are building AI agents. And I love that. But there’s a catch. There’s still no shared understanding of how to architect flexible, scalable AI systems. No real design patterns. No widely adopted structure. Just vibes.
The more I looked around, the more I saw it. Agents built in n8n look like spaghetti. Impossible to read, debug, or scale. Tutorials on building agents in Python? Same story. Everything dumped into one file, no separation of concerns. Sure, experienced devs might know they should split things out - but beginners don’t. And they end up building systems that are completely unmaintainable.
So today, I want to share the solution I’ve come to rely on. This is how I structure my AI systems. How I separate responsibilities. How I keep things flexible, scalable, and actually sane.
Let me introduce you to my framework, design pattern, or architecture - call it what you want - AAC: Agent Action Chains.
Meet AAC (Agent Action Chains)
At some point, I realized something simple. If chaos keeps happening over and over again, maybe it’s not an accident. Maybe it means the system is missing.
So I started experimenting. First, with blocks inside n8n. Then I began separating logic manually - here’s where I handle input, here’s where I do processing, here’s the core logic. Eventually, roles started to emerge. And then it hit me. This needs structure. This needs architecture.
That’s how AAC was born - Agent Action Chains.
It’s not another framework with a thousand pages of docs.
AAC is a mindset. A way to build AI systems like a grown-up engineer, not like someone stitching things together and hoping for the best.
What’s the core idea?
I split the system into agents with clear roles. Each agent does exactly one thing. They all talk through JSON contracts - no guessing, no magic, no mess. Everything becomes predictable, scalable, and easier to debug.
Think of it like a team.
One handles input.
Another processes data.
A third decides what to do next.
Another agent talks to memory.
One catches failures.
Another watches and logs everything.
Everyone knows their job. And together, the system runs like a Swiss watch.
The beauty of AAC is that it’s platform-agnostic. You can implement it in n8n, in Make.com, in Python using FastAPI, even inside LangChain or LangGraph if you take the time to set it up properly.
Here’s How It Works (In Plain English)
Picture a solid team. Not a chaotic group where everyone’s doing everything at once, but a crew where each person knows their job, owns their space, and delivers a clear result. One takes in requests, another thinks, a third acts, someone else double-checks, and someone logs what actually happened.
That’s exactly how AAC works.
When an input hits the system - whether from a user or an external service - it first passes through an agent that simply opens the door and hands it off. Then comes basic processing. We don’t rush to conclusions. First, we structure the input, clean the noise, normalize it. That step alone saves hours of debugging down the road. A clean input is half the architecture.
Next comes the orchestrator. It’s the brain of the system. It doesn’t execute the task itself. Instead, it figures out who should do what, in what order, with which parameters. The orchestrator’s role is to plan, direct, and manage the flow. Nothing more, nothing less.
Then the specialists take over. These agents are focused. One classifies, another summarizes, a third fetches external data, and so on. Each has a clear purpose. They don’t overlap, they don’t fight over responsibilities, they don’t rewrite each other’s outputs. You can swap them out, improve them, reuse them - just like good software modules.
When the system needs to remember something, memory comes into play. That’s its own agent. It doesn’t store everything blindly. Instead, it knows how to retrieve the right things at the right time - previous conversations, user context, internal facts. This is how your system stops being a goldfish and starts acting like a real assistant.
Error handling is treated just as seriously. AAC includes a dedicated agent for that - the Guard. It monitors for failures, catches exceptions, takes action when something breaks. It’s not a patch, not a random try-catch. It’s a real part of the architecture. And it’s responsible for resilience.
While all of this is happening, the Observer is quietly watching. It tracks what each agent does, how long things take, what decisions are made. Not just for fun - this gives you visibility into the system. Not “did it work?” but how it worked, why it worked, and where it could fail.
And finally, when the whole chain has done its job, the result is formatted and delivered - back to the user, into an API response, or wherever it needs to go. Clean, structured, and easy to consume.
That’s AAC. A system built not just to function, but to evolve, scale, and stay under control.
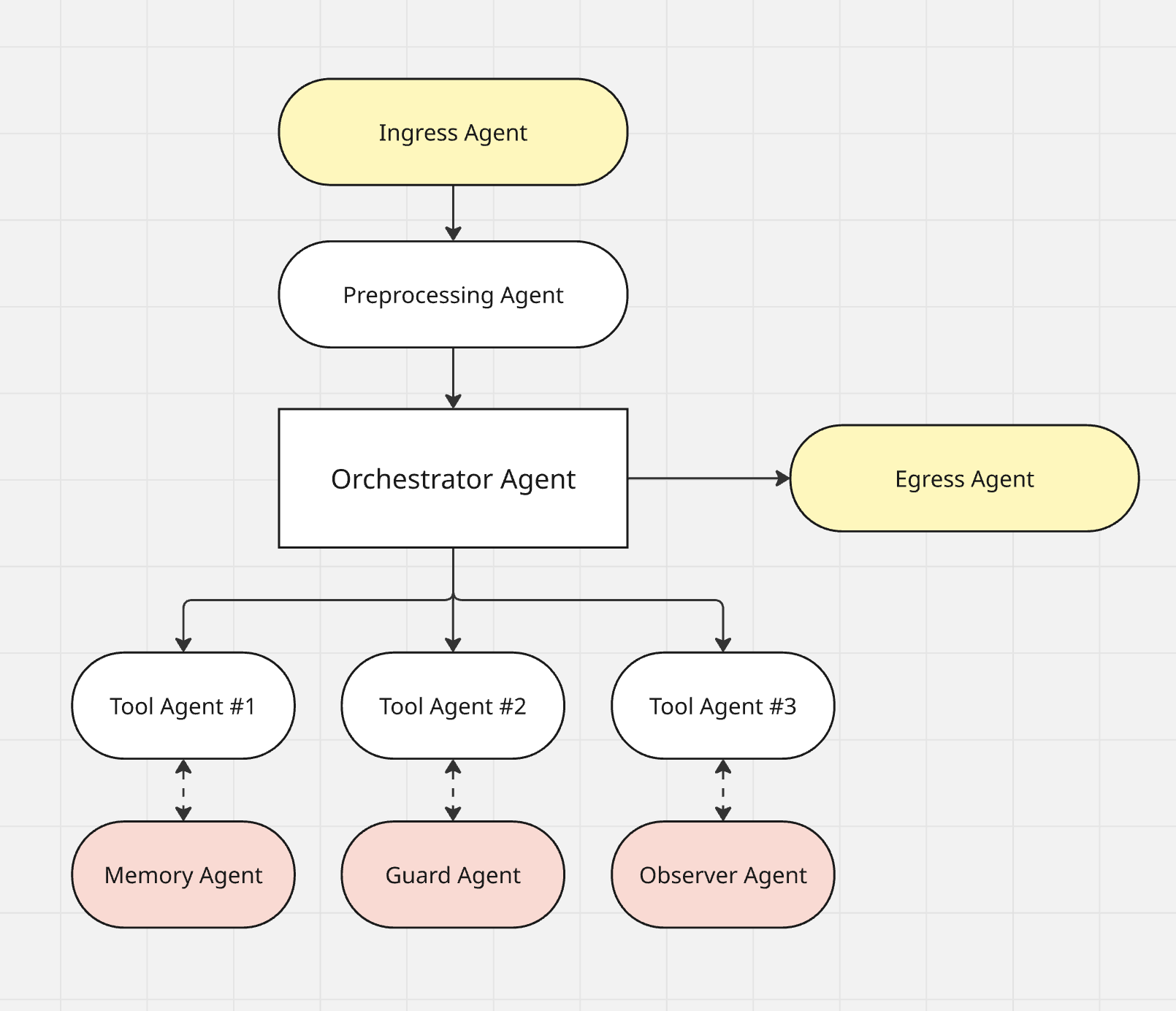
All AAC Roles: Who Does What and Why It Matters
AAC is built on clear separation of responsibilities. Each agent isn’t just a technical block - it’s a logical unit with a defined role and a communication contract. This section breaks down what these roles are for, how they interact, and why skipping even one of them often leads to architectural pain later.
Ingress Agent: the Entry Point
Purpose: handle the incoming signal.
This could be a webhook, a form submission, a Telegram message, a Kafka event - it really doesn’t matter. What matters is isolating input handling from business logic.
Why? Because mixing logic with integration layers is the first step toward building a monolith. And monoliths don’t scale - they break.
In n8n, this is usually just a webhook node. It receives the request, logs the data, and passes a clean JSON payload into the system.
Example (pseudocode):
{
"source": "user",
"payload": {
"message": "I’d like to return my order"
}
}
Preprocessing Agent: the Filter and Normalizer
Purpose: turn raw input into something usable.
This agent cleans up the noise. It fixes casing, strips weird symbols, validates structure, and extracts key fields. It makes sure that everything passed into the system is predictable and consistent.
A lot of people skip preprocessing. Big mistake. It’s not just a “nice-to-have” - it’s the foundation. Especially when you’re dealing with LLMs, context hygiene is everything. One messy input and the whole reasoning chain can fall apart.
In n8n, this is typically a function node.
In code, it could be middleware, a handler, or a small utility class.
const cleanInput = input.message.trim().toLowerCase()
Orchestrator Agent: the Brain of the System
Purpose: decide what needs to happen.
The orchestrator doesn’t do the work itself. Its job is to plan, delegate, and monitor. It takes the cleaned input, figures out the user’s intent, and activates the right specialist agents.
In simple cases, this could just be an if/else block. In more advanced setups, it’s a full-blown LLM running with carefully designed prompts. For example, you can have GPT-4 return a structured execution plan in JSON:
{
"steps": [
{"agent": "Classifier", "input": {...}},
{"agent": "Memory", "input": {...}},
{"agent": "Responder", "input": {...}}
]
}
You can even pass it a list of available agents and let it choose the best path forward.
The key idea is this: the orchestrator doesn’t solve the problem. It builds the route. It decides who needs to do what, and in what order.
Specialist Agents: Focused Experts (TOOLS)
Purpose: perform a single, well-defined task.
These agents aren’t here to solve the whole problem - just one specific piece of it, and do it well. Think of tasks like:
- Classifying a request
- Generating a reply
- Extracting entities
- Calling an external API
- Translating text
You might end up with dozens of these. Each is a separate function, a clean module, or a subflow in n8n. And that’s exactly what makes the system flexible and scalable. Want to add a new capability? Just create a new specialist and register it. The orchestrator doesn’t need to be rewritten - it just needs to know this tool exists.
Example of a contract between the orchestrator and a specialist:
{
"agent": "Classifier",
"input": {
"text": "My order never arrived"
},
"output_expected": {
"label": "delivery_problem"
}
}
Memory Agent: the Interface to the Past
Purpose: provide relevant context.
This agent fetches facts. That’s it. It queries a database, a vector store, a Redis cache - whatever you’ve got - and returns exactly what’s needed. It doesn’t make decisions, doesn’t guess, doesn’t hallucinate. Just pulls real data.
Think of it as the system’s memory. You can use it to retrieve a user’s past orders, match vector embeddings from a knowledge base, or grab previous interactions.
In AAC, memory is always its own thing. That way, you can scale it, cache it, or even plug it into multiple systems.
SELECT * FROM orders WHERE user_id = "user_42" ORDER BY created_at DESC LIMIT 3
Guard Agent: Protection from Chaos
Purpose: catch and handle failures.
If a specialist crashes or the orchestrator breaks down, the guard steps in. It logs the error, sends alerts, and optionally runs fallback logic - like retrying with a different agent or returning a safe default response.
In production, this role is non-negotiable. Errors will happen. GPT might return garbage. APIs might timeout. You need a layer that knows what to do when things go sideways.
Example: GPT returns invalid JSON. The guard catches it, logs the issue, notifies Slack, and sends a fallback message.
{
"error": "Invalid JSON from Summarizer",
"fallback_response": "Sorry, I couldn’t process your request. Forwarding it to a human operator."
}
Observer Agent: the System’s Black Box
Purpose: log, analyze, and give you visibility into what actually happened.
This agent doesn’t interfere - it just watches. Want to track how long each agent took to respond? What data the Memory agent pulled? How often the Guard had to trigger a fallback? Observer logs all of it to whatever tool you’re using - Supabase, Amplitude, Segment, or something custom.
Think of it like the black box in an airplane. You hope you won’t need it, but when something breaks, it’s the only way to understand what went wrong.
Without an Observer, you’re flying blind. With it, you get a full picture.
Egress Agent: the Final Touch
Purpose: wrap up the process cleanly.
This agent takes the final output, formats it, and delivers it wherever it needs to go - to the user, an API, a webhook, Slack, whatever. It doesn’t make decisions. It just finalizes the response and sends it out.
One of the most common mistakes is to forget this step. Without a dedicated egress agent, you risk sending broken data, raw logs, or responses to the wrong place. Egress is about having control over the last mile.
{
"status": "success",
"reply": "We’ve reviewed your case. Thank you for reaching out!"
}
Each of these agents is a building block. You can run them in parallel, replace them independently, reuse them across chains.
What’s Next? How to Start Using AAC in Your Projects
If you’re reading this, chances are you’ve already faced the same issues I did.
Your project keeps growing. Use cases multiply. The logic spreads wider. The agents get “smarter” - but the system gets more fragile. What was a neat MVP yesterday has now turned into a tangled mess. Want to add a new branch? It’s a hassle. Trying to debug why GPT returned something weird? No idea where it even happened.
This is the moment you start asking - is there another way?
There is.
Implementing AAC means changing the way you think. It’s a shift from magic to engineering.
And the starting point isn’t code. It’s looking at your system differently. Clearly. Without illusions.
Try imagining your logic as a chain of independent specialists. One takes the input. Another prepares the data. A third decides what to do. Then comes the executor. After that - memory. Then someone catches failures. Finally, someone logs what happened. That’s your future agent, AAC-style. Right now, though, all those roles are either implicit or tangled together so badly that no one knows what’s what.
The first real step is making those roles explicit. Even just mentally. Sketch them out. Give them names. Start asking the right questions: who’s responsible for orchestration here? Where’s memory? How do I know if things actually worked? What happens if one block fails?
Once you do that, the value of modularity becomes obvious. When everything is bundled into one place, one error breaks the whole system. But when things are structured as loosely coupled agents, failures get isolated - and the system keeps running. That’s why in AAC, every agent is isolated, communicates through contracts, and has no awareness of the others. It’s like microservices inside one pipeline. Only simpler. And faster.
And then the fun begins.
You suddenly realize you can reuse pieces of the system. The same classifier agent that handles one flow can be used in another. The memory block can be shared across multiple chains. You can even make the orchestrator smarter - let it choose which agents to trigger. This isn’t fantasy. This is the baseline maturity AAC brings.
On no-code platforms like n8n, this becomes a real superpower.
You start building a library of agents. Each one is a subflow with a defined contract. Want to build a new bot? Just call the agents you need, in the order you need them. Want to replace a block? Do it without fear. Want to monitor performance or track where things fail most? You’ve already got it - Observer logs everything, Guard captures every failure. You start seeing the system like an engineer, not someone afraid to touch the code.
And that’s the goal. You’re designing. You’re turning a chain of GPT calls into real architecture - something that lives, scales, logs, evolves.
And if you don’t have time to rebuild everything right now - that’s fine. Start with one flow. One entry point. One honest moment where you say, “Alright, let me try a new approach here. Let me separate the roles. Add some control.”
That’s the moment you start building with AAC.
And chances are - you won’t want to go back.
This content originally appeared on HackerNoon and was authored by Maksim Nechaev
Maksim Nechaev | Sciencx (2025-07-25T05:53:17+00:00) You’re Building AI Agents Wrong. Here’s How to Fix That with AAC. Retrieved from https://www.scien.cx/2025/07/25/youre-building-ai-agents-wrong-heres-how-to-fix-that-with-aac/
Please log in to upload a file.
There are no updates yet.
Click the Upload button above to add an update.