
This content originally appeared on HackerNoon and was authored by Phonology Technology
Table of Links
Related Work
RapVerse Dataset
Method
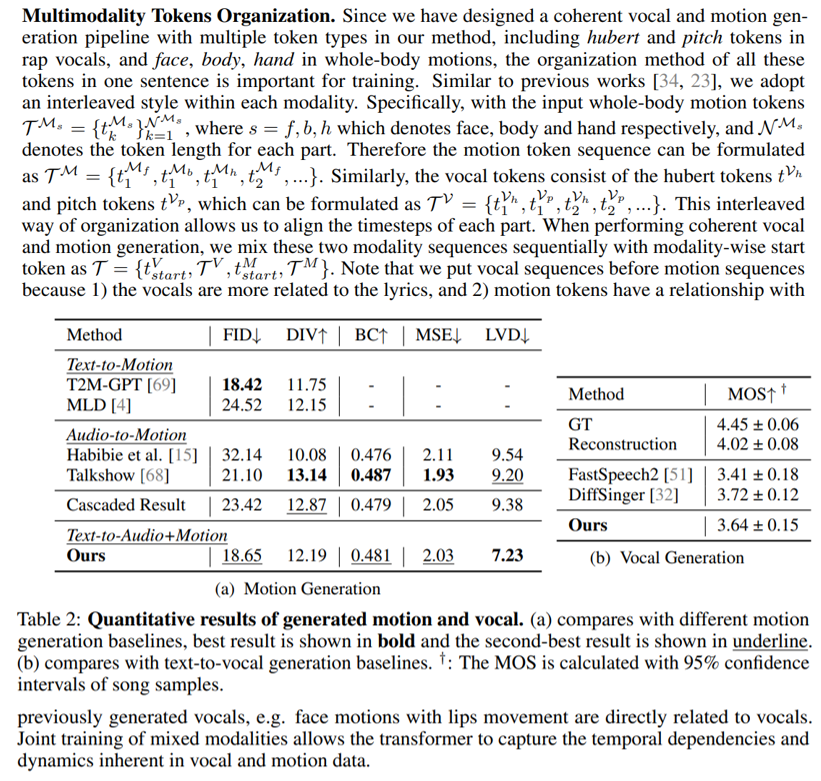
Experiments
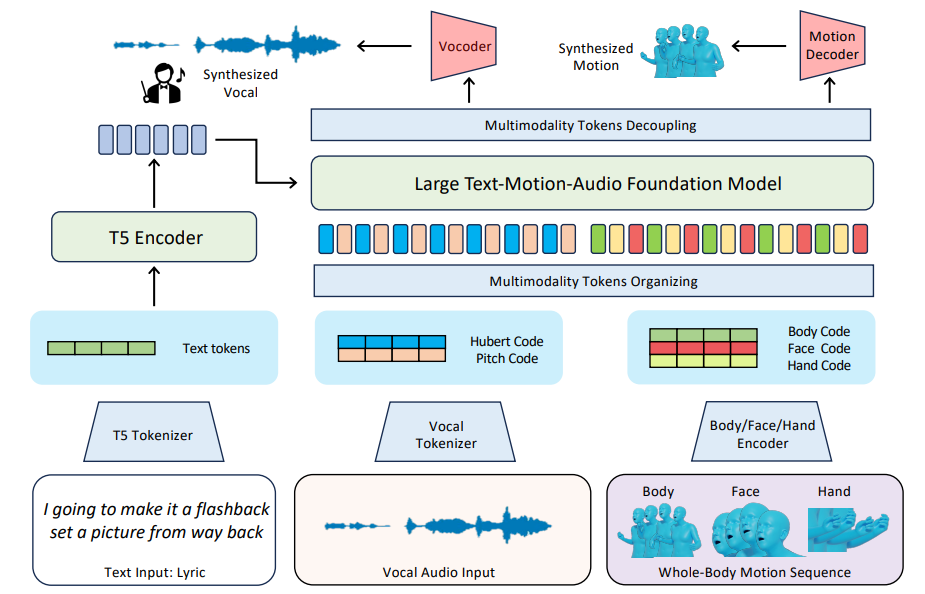
\ Given a piece of lyrics text, our goal is to generate rap-style vocals and whole-body motions, including body movements, hand gestures, and facial expressions that resonate with the lyrics. With the help of our RapVerse dataset, we propose a novel framework that not only represents texts, vocals, and motions as unified token forms but also integrates token modeling in a unified model. As illustrated in Fig. 3, our model consists of multiple tokenizers for motion (Sec. 4.2) and vocal (Sec. 4.3) token conversions, as well as a general Large Text-Motion-Audio Foundation Model (Sec. 4.4) that targets for audio token synthesize and motion token creation, based on rap lyrics.
4.1 Problem Formulation

\
\
4.2 Motion VQ-VAE Tokenizer
\

\
4.3 Vocal2unit Audio Tokenizer
Overall, we leverage the self-supervised framework [45] in speech resynthesis domain to learn vocal representations from the audio sequences. Specifically, we train a Vocal2unit audio tokenizer to build a discrete tokenized representation for the human singing voice. The vocal tokenizer consists of three encoders and a vocoder. The encoders include three different parts: (1) the semantic encoder; (2) the F0 encoder; and (3) the singer encoder. We will introduce each component of the model separately.
\
\

4.4 General Auto-regressive Modeling
\

\ \ After optimizing via this training objective, our model learns to predict the next token, which can be decoded into different modality features. This process is similar to text word generation in language models, while the “word” in our method such as <face_02123>, does not have explicit semantic information, but can be decoded into continuous modality features.
\
\
\ \ Inference and Decoupling. In the inference stage, we use different start tokens to specify which modality to generate. The textual input is encoded as features to guide token inference. We also adopt a top-k algorithm to control the diversity of the generated content by adjusting the temperature, as generating vocals and motions based on lyrics is a creation process with multiple possible answers. After token prediction, a decoupling algorithm is used to process output tokens to make sure tokens from different modalities are separated and temporally aligned. These discrete tokens will be further decoded into text-aligned vocals and motions
\ \
:::info Authors:
(1) Jiaben Chen, University of Massachusetts Amherst;
(2) Xin Yan, Wuhan University;
(3) Yihang Chen, Wuhan University;
(4) Siyuan Cen, University of Massachusetts Amherst;
(5) Qinwei Ma, Tsinghua University;
(6) Haoyu Zhen, Shanghai Jiao Tong University;
(7) Kaizhi Qian, MIT-IBM Watson AI Lab;
(8) Lie Lu, Dolby Laboratories;
(9) Chuang Gan, University of Massachusetts Amherst.
:::
:::info This paper is available on arxiv under CC BY 4.0 DEED license.
:::
\
This content originally appeared on HackerNoon and was authored by Phonology Technology
Phonology Technology | Sciencx (2025-08-07T18:41:37+00:00) Text-to-Rap AI Turns Lyrics Into Vocals, Gestures, and Facial Expressions. Retrieved from https://www.scien.cx/2025/08/07/text-to-rap-ai-turns-lyrics-into-vocals-gestures-and-facial-expressions/
Please log in to upload a file.
There are no updates yet.
Click the Upload button above to add an update.