
This content originally appeared on HackerNoon and was authored by Web Fonts
Table of Links
1.1 Printing Press in Iraq and Iraqi Kurdistan
1.2 Challenges in Historical Documents
Related work and 2.1 Arabic/Persian
Method and 3.1 Data Collection
3.2 Data Preparation and 3.3 Preprocessing
3.4 Environment Setup, 3.5 Dataset Preparation, and 3.6 Evaluation
Experiments, Results, and Discussion and 4.1 Processed Data
5.1 Challenges and Limitations
Following is the list of main challenges and limitations we faced during this research:
\ • The limited availability of resources posed significant challenges during our data collection
\
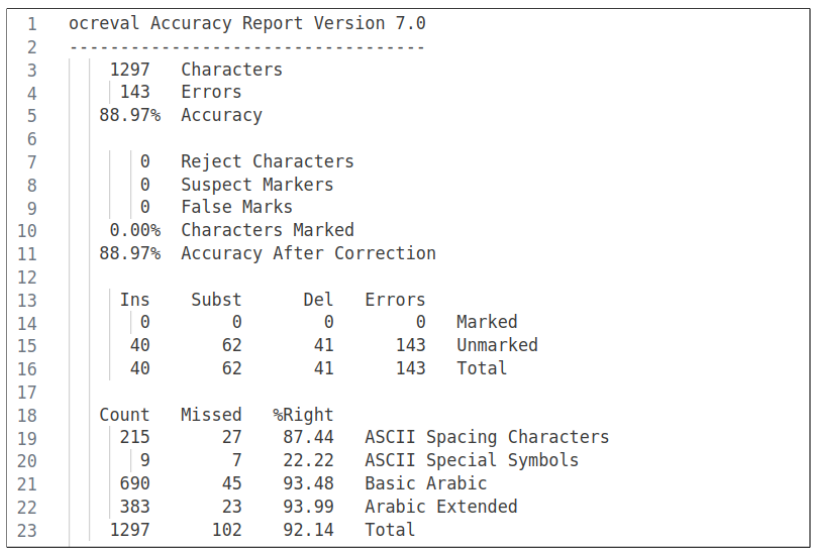
\ process. Converting the collected data into a digital format proved an additional obstacle. Manual transcription of the documents was difficult due to unclear text, non-standard spacing, and unique vocabulary influenced by Arabic letters and terminologies. We attempted to create the dataset synthetically, crafting a small tool that assembled letters from a given collection of character images. Regrettably, the outcomes were unsatisfactory, and given our time constraints, we discontinued this approach.
\ • The non-standard spacing between the words and characters was challenging for transcribing the documents and needed to be more apparent for the model. The model interpreted the excessive gaps between characters or words as space characters. In contrast, in other cases where there should have been a space character, the minimal spacing went unnoticed by the model.
\ • Extracting text from multi-column pages was another limitation of the model.
\ • Recognizing mathematical equations was another limitation of our model.
\ Considering the challenges and limitations and based on the discussion on the results, we are interested in exploring several areas in the future as follows:
\ • Expanding the dataset is an aspect that requires further attention and effort.
\ • An observed issue pertained to the misalignment of spaces between words and characters. To address this, a post-processing phase is suggested for rectifying the misaligned space characters. • Ocr’ing the multi-column pages property is another area requiring more effort.
\ • Extracting mathematical equations accurately.
\
Online Resources
The dataset is partially publicly available for non-commercial use under the CC BY-NC-SA 4.0 license at https://github.com/KurdishBLARK/OCR4OldTextsInSorani.
Acknowledgments
We would like to extend our gratitude to the Zheen Center for Documentation and Research in Sulaymaniyah, Kurdistan Region, Iraq for their generous support in providing us with digital copies of certain historical publications.
References
Ahmadi, S., Hassani, H., and Jaff, D. Q. (2022). Leveraging multilingual news websites for building a Kurdish parallel corpus. Transactions on Asian and Low-Resource Language Information Processing, 21(5):1–11.
\ Antonacopoulos, A., Karatzas, D., Krawczyk, H., and Wiszniewski, B. (2004). The lifecycle of a digital historical document: structure and content. In Proceedings of the 2004 ACM Symposium on Document Engineering, pages 147–154.
\ Ataer, E. and Duygulu, P. (2007). Matching Ottoman words: an image retrieval approach to historical document indexing. In Proceedings of the 6th ACM International Conference on Image and Video Retrieval, pages 341–347.
\ Aula, L. (2021). Improvement of optical character recognition on scanned historical documents using image processing.
\ Bukhari, S. S., Kadi, A., Jouneh, M. A., Mir, F. M., and Dengel, A. (2017). anyOCR: An opensource OCR system for historical archives. In 2017 14th IAPR International Conference on Document Analysis and Recognition (ICDAR), volume 1, pages 305–310. IEEE.
\ Bulert, K., Miyagawa, S., and B¨”uchler, M. (2017). Optical character recognition with a neural network model for printed coptic texts. In Digital Humanities 2017 Conference Abstracts, pages 657–9.
\ Do˘gru, M. (2016). Ottoman-Turkish Optical Character Recognition and Latin Transcription. Ph.D. thesis, Ankara Yıldırım Beyazıt ¨”Universitesi Fen Bilimleri Enstit¨”us¨”u.
\ Dolek, I. and Kurt, A. (2021). Ottoman OCR: Printed Naskh font. In 2021 International Conference on INnovations in Intelligent SysTems and Applications (INISTA), pages 1–5. IEEE.
\ Feng, J., Peng, L., and Lebourgeois, F. (2015). Gaussian process style transfer mapping for historical chinese character recognition. In Document Recognition and Retrieval XXII, volume 9402, pages 104– 115. SPIE.
\ Gilbey, J. D. and Sch¨”onlieb, C.-B. (2021). An end-to-end optical character recognition approach for ultra-low-resolution printed text images. arXiv preprint arXiv:2105.04515.
\ Google. (2023a). How to train lstm/neural net tesseract. Accessed on 30-04-2023.
\ Google. (2023b). Improving the quality of the output. Accessed on 15-04-2023.
\ Hassani, H., Medjedovic, D., et al. (2016). Automatic Kurdish dialects identification. Computer Science & Information Technology, 6(2):61–78.
\ Hassanpour, A. (1992). Nationalism and language in Kurdistan, 1918-1985. San Francisco: Mellen Research University Press.
\ Idrees, S. and Hassani, H. (2021). Exploiting Script Similarities to Compensate for the Large Amount of Data in Training Tesseract LSTM: Towards Kurdish OCR. Applied Sciences, 11(20):9752.
\ Idrees, S. (2020). Improving Document Processing in the Public Organizations of the Kurdistan Region of Iraq (KRI) Using an Optical Character Recognition (OCR) System. Master Thesis.
\ Kilic, N., Gorgel, P., Ucan, O. N., and Kala, A. (2008). Multifont ottoman character recognition using support vector machine. In 2008 3rd international symposium on communications, control and signal processing, pages 328–333. IEEE.
\ Koistinen, M., Kettunen, K., and Kervinen, J. (2017). How to improve optical character recognition of historical finnish newspapers using open source tesseract ocr engine. Proc. of LTC, pages 279–283.
\ K¨u¸c¨uk¸sahin, N. (2019). Design of an Offline Ottoman Character Recognition System for Translating Printed Documents to Modern Turkish. Ph.D. thesis, Izmir Institute of Technology (Turkey).
\ Li, B., Peng, L., and Ji, J. (2014). Historical chinese character recognition method based on style transfer mapping. In 2014 11th IAPR International Workshop on Document Analysis Systems, pages 96–100. IEEE.
\ Ly, N. T., Nguyen, C. T., and Nakagawa, M. (2020). An attention-based row-column encoder-decoder model for text recognition in japanese historical documents. Pattern Recognition Letters, 136:134–141.
\ Munivel, M. and Enigo, V. (2022). Optical character recognition for printed tamizhi documents using deep neural networks. DESIDOC Journal of Library & Information Technology, 42(4).
\ Nashwan, F. M., Rashwan, M. A., Al-Barhamtoshy, H. M., Abdou, S. M., and Moussa, A. M. (2017). A holistic technique for an arabic ocr system. Journal of Imaging, 4(1):6.
\ Nguyen, H. T., Ly, N. T., Nguyen, K. C., Nguyen, C. T., and Nakagawa, M. (2017). Attempts to recognize anomalously deformed kana in japanese historical documents. In Proceedings of the 4th International Workshop on Historical Document Imaging and Processing, pages 31–36.
\ Nunamaker, B., Bukhari, S. S., Borth, D., and Dengel, A. (2016). A tesseract-based ocr framework for historical documents lacking ground-truth text. In 2016 IEEE International Conference on Image Processing (ICIP), pages 3269–3273. IEEE.
\ Ozturk, A., Gunes, S., and Ozbay, Y. (2000). Multifont ottoman character recognition. In ICECS 2000. 7th IEEE International Conference on Electronics, Circuits and Systems (Cat. No. 00EX445), volume 2, pages 945–949. IEEE.
\ Poncelas, A., Aboomar, M., Buts, J., Hadley, J., and Way, A. (2020). A tool for facilitating ocr postediting in historical documents. arXiv preprint arXiv:2004.11471.
\ Poulos, M., Kokkonas, Y., Papavlasopoulos, S., and Bokos, G. (2010). An ocr system for greek printed early books based on computational geometry algorithms.
\ Qania, M. (2012). Le Barey Ragayandinewe. Chwarchra.
\ Reul, C., Springmann, U., Wick, C., and Puppe, F. (2018). State of the art optical character recognition of 19th century fraktur scripts using open source engines. arXiv preprint arXiv:1810.03436.
\ Romanello, M., Najem-Meyer, S., and Robertson, B. (2021). Optical character recognition of 19th century classical commentaries: the current state of affairs. In The 6th International Workshop on Historical Document Imaging and Processing, pages 1–6.
\ Shafii, M. (2014). Optical character recognition of printed persian/arabic documents.
\ Sihang, W., Jiapeng, W., Weihong, M., and Lianwen, J. (2020). Precise detection of chinese characters in historical documents with deep reinforcement learning. Pattern Recognition, 107:107503.
\ Simistira, F., Ul-Hassan, A., Papavassiliou, V., Gatos, B., Katsouros, V., and Liwicki, M. (2015). Recognition of historical greek polytonic scripts using lstm networks. In 2015 13th International Conference on Document Analysis and Recognition (ICDAR), pages 766–770. IEEE.
\ Skelbye, M. B. and Dann´ells, D. (2021). Ocr processing of swedish historical newspapers using deep hybrid cnn–lstm networks. In Proceedings of the International Conference on Recent Advances in Natural Language Processing (RANLP 2021), pages 190–198.
\ Springmann, U., Fink, F., and Schulz, K. U. (2016). Automatic quality evaluation and (semi-) automatic improvement of ocr models for historical printings. arXiv preprint arXiv:1606.05157.
\ Springmann, U., Reul, C., Dipper, S., and Baiter, J. (2018). Ground truth for training ocr engines on historical documents in german fraktur and early modern latin. arXiv preprint arXiv:1809.05501.
\ Stahlberg, F. and Vogel, S. (2016). Qatip–an optical character recognition system for arabic heritage collections in libraries. In 2016 12th IAPR Workshop on Document Analysis Systems (DAS), pages 168–173. IEEE.
\ Sulaiman, A., Omar, K., and Nasrudin, M. F. (2019). Degraded historical document binarization: A review on issues, challenges, techniques, and future directions. Journal of Imaging, 5(4):48.
\ Vamvakas, G., Gatos, B., Stamatopoulos, N., and Perantonis, S. J. (2008). A complete optical character recognition methodology for historical documents. In 2008 The Eighth IAPR International Workshop on Document Analysis Systems, pages 525–532. IEEE.
\ Yang, H., Jin, L., and Sun, J. (2018). Recognition of chinese text in historical documents with pagelevel annotations. In 2018 16th International Conference on Frontiers in Handwriting Recognition (ICFHR), pages 199–204. IEEE.
\ Yousefi, M. R., Soheili, M. R., Breuel, T. M., Kabir, E., and Stricker, D. (2015). Binarization-free OCR for historical documents using lstm networks. In 2015 13th International Conference on Document Analysis and Recognition (ICDAR), pages 1121–1125. IEEE.
\
:::info Authors:
(1) Blnd Yaseen, University of Kurdistan Howler, Kurdistan Region - Iraq (blnd.yaseen@ukh.edu.krd);
(2) Hossein Hassani University of Kurdistan Howler Kurdistan Region - Iraq (hosseinh@ukh.edu.krd).
:::
:::info This paper is available on arxiv under ATTRIBUTION-NONCOMMERCIAL-NODERIVS 4.0 INTERNATIONAL license.
:::
\
This content originally appeared on HackerNoon and was authored by Web Fonts
Web Fonts | Sciencx (2025-08-20T08:00:07+00:00) Key Challenges in OCR Research and Future Directions. Retrieved from https://www.scien.cx/2025/08/20/key-challenges-in-ocr-research-and-future-directions/
Please log in to upload a file.
There are no updates yet.
Click the Upload button above to add an update.