
This content originally appeared on HackerNoon and was authored by hackernoon
Artificial Intelligence based systems are the talk of the town, and AI assisted processes and systems are being created like never before. Whilst creating such systems involves numerous complexities, one thing that lies at the backbone is Large Language Models. In this article, we’ll be discussing one key aspect of LLMs, which is sentence representations.
Formally, we can define sentence representations as dense vector encodings that help us capture the meanings of complete sentences. They differ from word embeddings in that they help us understand and model the semantics, syntax, and context of the entire sentence. This capability helps us in the clustering and classification of sentences and in their comparison.
Today, we are using AI for paraphrasing sentences, generating summaries, and doing semantic searches and so on, and sentence representations are the building blocks of it. Their capability of helping us understand long-range dependencies is what drives these LLMs and helps us generate coherent text. Some models that are efficient in learning sentence representations include BERT, specifically Sentence BERT.
Prior to transformer based architecture we had something known as Deep Averaging Networks or DANs. Although, not a dominant architecture in today’s scenario they were crucial building blocks towards LLMs and still prove valuable where computational resources are limited. Typically in production environments where we are concerned about resource constraints, we have to apply techniques such as knowledge distillation to transformer based models in order for them to be applicable. However, upon doing that we have observed that the performance of DANs become comparable to them and are much less computationally intensive making them a handy alternative.
Also, in tasks such as Genome Variant Calling which are critical in identifying variations in genetic information we need to have utmost faith in our predictions and interpretability of the model becomes critical. This is where networks such as DANs become critical as their network architecture allows transparency in model explainability. One is able to identify the influence and impact of a particular embedding towards the output.
But, when it comes to understanding longer sequences and nuances we have observed DAN to struggle.
In such scenarios wherein we want to capture sequences and their dependencies but still can’t afford to meet the computational requirements of transformers, Gated Recurrent Unit networks are still our best friend and are often used in tasks such as time series forecasting, speech recognitions, etc. They capture the sequences and dependencies via their recurrent gating architecture. The primary advantage of GRUs are their capability to maintain their memory across various steps thereby allowing them to gather context. However, in terms of interpretability they are less transparent as compared to DANs and in terms of efficiency they lie in the middle i.e heavier compared to DANs but much lighter than transformers thereby becoming the perfect candidate for maintaining balance between performance and efficiency.
They are favored for tasks that require the preservation of order such as translations, sequential data forecasting, etc., compared to DANs which are more favored for tasks resembling bag of words structure.
To do a quick evaluation of these two networks, let’s take a quick look on how they can be set up.
Deep Averaging Network:
- The average of the word embeddings can be represented as a fixed length vector and can be retrieved using “reduce_mean” function.
- Now, once you have the fixed length vector you can apply non linear transformations to get the output.
- Then we would stack the feed forward networks with a tanh non linearity. You can think of this as a stacked logistic regression model giving the final prediction. Then build the feed-forward netowrks with Dense layers and activation='tanh'.
- To adjust for the dropout, update the sequence mask with the appropriate dropout values.
- You would need to run the loop same times as num_layers.
- For each loop you would save the output of each layer and stack them to form the layer representations. Once you reach the final layer then take the last state of the last layer as the combined vector.
\ One concern you might have is that averaging can reduce the important differences; but if you add more transformations then these differences can be recovered in the subsequent layers.
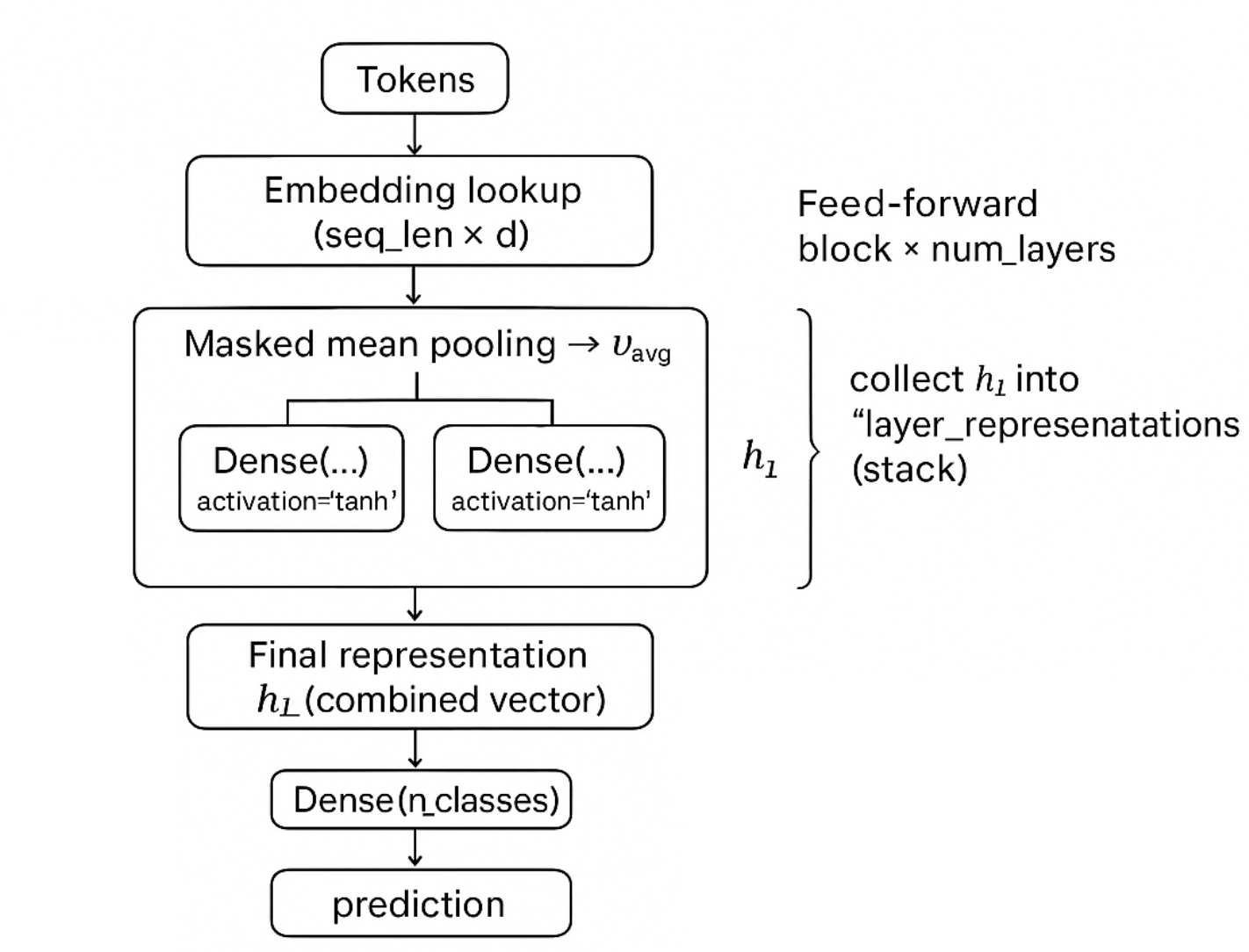
\n
Gated Recurrent Units:
To set up Gated Recurrent Units let us understand some basic differences from Long Short Term Memory. GRUs do not use the forget and input gate as in the LSTMs and actually merges them to a single update gate. Multiple transformations happen over many layers in a GRU. But, typically 2-3 layers are considered good as adding more layers diminishes the outcome and also slows the training.
We can use inbuilt frameworks from Tensorflow or Pytorch to implement a GRU and modify the return sequences parameter to True and use tanh as the activation function.
\n
To compare the above to networks we use certain probing tasks such as sentiment analysis.
\n
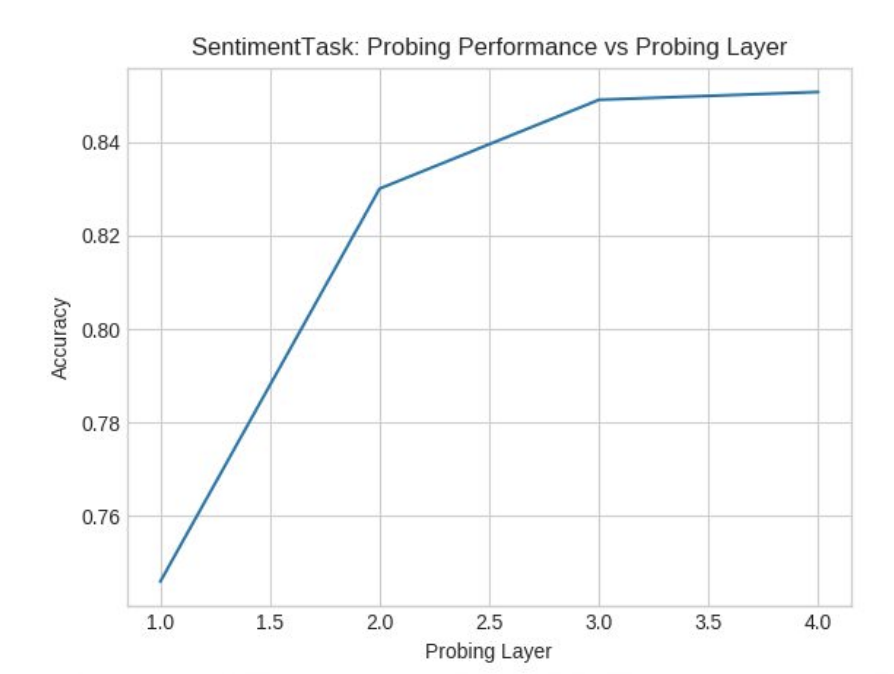
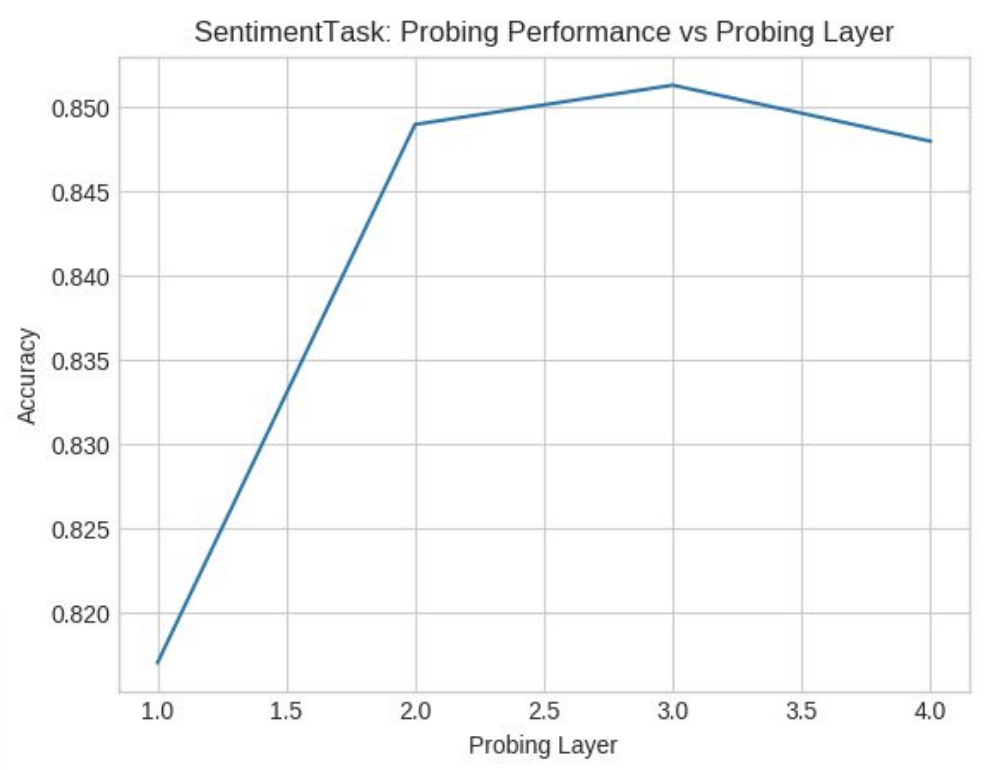
We won’t go into the details of the dataset but for a standard sentiment analysis dataset we observed DAN gave an accuracy of around 84.5%. We observed that with increase in the number of layers in DAN the accuracy increased as it should because more the number of feedforward networks, the more logistic regression like action we do and better the performance.
Whereas, GRU gave an accuracy of around 85.5% Accuracy increased with the number of layers till 3 but then it decreased as it should have. This is because more layers diminishes GRU performance.
To have a parallel comparison we plotted the bigram and observe that GRU performs better as it remembers the ordering of sequences and uses layered stacks.
\n
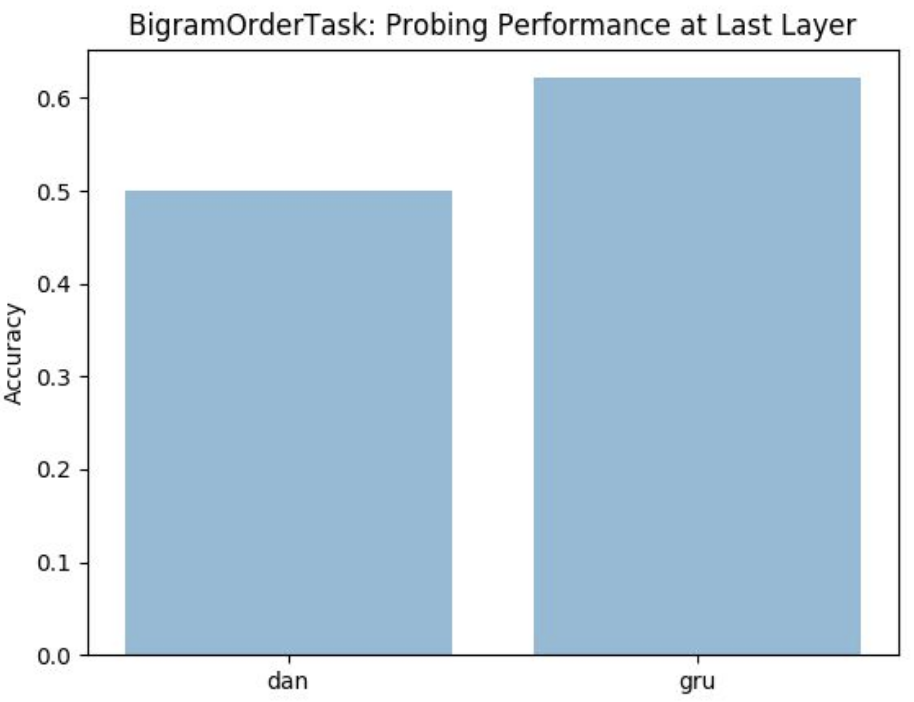
But for simpler tasks such as binary sentiment classification we observed DAN performing better than GRU as GRU is not good for learning simple languages as it cannot perform unbound counting.
If you’re interested more in analyzing these networks then performing perturbation analysis could provide more insights into these networks. Although, these networks are simpler compared to today’s complex LLMs but these are still some of the most effective networks capable of maintaining a balance between performance and efficiency and also allowing transparent interpretability.
This content originally appeared on HackerNoon and was authored by hackernoon
hackernoon | Sciencx (2025-08-20T06:23:54+00:00) The AI Building Block You’ve Never Heard Of (But Use Every Day). Retrieved from https://www.scien.cx/2025/08/20/the-ai-building-block-youve-never-heard-of-but-use-every-day-2/
Please log in to upload a file.
There are no updates yet.
Click the Upload button above to add an update.