
This content originally appeared on HackerNoon and was authored by Probabilistic
Table of Links
Harnessing Block-Based PC Parallelization
4.1. Fully Connected Sum Layers
4.2. Generalizing To Practical Sum Layers
Conclusion, Acknowledgements, Impact Statement, and References
B. Additional Technical Details
\
6.1. Faster Models with PyJuice
We first benchmark the runtime of PyJuice on four commonly used PC structures: PD (Poon & Domingos, 2011), RAT-SPN (Peharz et al., 2020b), HCLT (Liu & Van den Broeck, 2021), and HMM (Rabiner & Juang, 1986). For all models, we record the runtime to process 60,000 samples (including the forward pass, the backward pass, and mini-batch EM updates). We vary their structural hyperparameters and create five PCs for every structure with sizes (i.e., number of edges) ranging from 500K to 2B. We compare against four baselines: SPFlow (Molina et al., 2019), EiNet (Peharz et al., 2020a), Juice.jl (Dang et al., 2021), and Dynamax (Murphy et al., 2023). Dynamax is dedicated to State Space Models so it is only used to run HMMs; SPFlow and EiNet are excluded in the HMM results because we are unable to construct homogeneous HMMs with their frameworks due to the need to share the transition and emission parameters at different time steps. We describe how PyJuice implements PCs with tied parameters in Appendix A.3. All experiments in this subsection are carried out on an RTX 4090 GPU with 24GB memory.
\ Table 1 reports the runtime in seconds per epoch with minibatch EMs. PyJuice is orders of magnitude faster than all baselines in both small and large PCs. Further, we observe that most baselines exhaust 24GB of memory for larger PCs (indicated by “OOM” in the table), while PyJuice can still efficiently train these models. Additionally, in Appendix D.1,
\
![Figure 6. Comparison on memory efficiency. We take two PCs (i.e., an HCLT w/ 159M edges and an HMM w/ 130M edges) and record GPU memory usage under different block sizes.[7]](https://cdn.hackernoon.com/images/fWZa4tUiBGemnqQfBGgCPf9594N2-9r0322g.png)
\ we show the efficiency of the compilation process. For example, it takes only ∼8.7s to compile an HCLT with 159M edges. Note that we only compile the PC once and then reuse the compiled structure for training and inference.
\ In Figure 6, we take two PCs to show the GPU memory consumption with different batch sizes. The results demonstrate that PyJuice is more memory efficient than the baselines, especially in the case of large batch sizes (note that we always need a constant-size space to store the parameters).
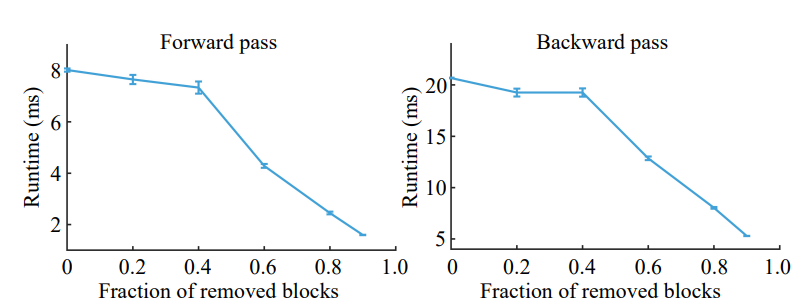
\ We move on to benchmark PyJuice on block-sparse PCs. We create a sum layer with 209M edges (see Appx. C.1 for details). We partition the sum and input product nodes in the layer into blocks of 32 nodes respectively. We randomly discard blocks of 32×32 edges, resulting in block-sparse layers. As shown in Figure 7, as the fraction of removed edge blocks increases, the runtime of both the forward and the backward pass decreases significantly. This motivates future work on PC modeling to focus on designing effective block-sparse PCs.
\
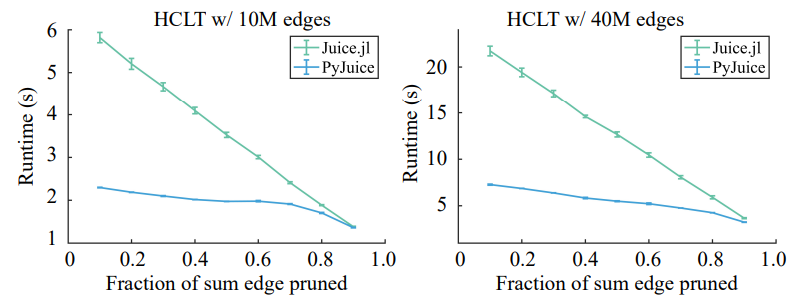
\ Finally, we proceed to evaluate the runtime of sparse PCs. We adopt the PC pruning algorithm proposed by Dang et al. (2022) to prune two HCLTs with 10M and 40M edges, respectively. We only compare against Juice.jl since all other implementations do not support sparse PCs. As shown in Figure 8, PyJuice is consistently faster than Juice.jl, despite the diminishing gap when over 90% edges are pruned. Note that with sparse PCs, PyJuice cannot fully benefit from the block-based parallelization strategy described in Section 4, yet it can still outperform the baseline.
\
\
6.2. Better PCs At Scale
This section demonstrates the ability of PyJuice to improve the state of the art by simply using larger PCs and training for more epochs thanks to its speed and memory efficiency. Specifically, we take the HMM language model proposed by Zhang et al. (2023) and the image model introduced by Liu et al. (2023c) as two examples.
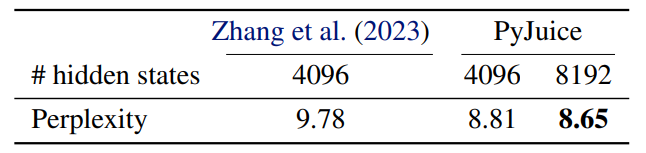
\ HMM language models. Zhang et al. (2023) use the Latent Variable Distillation (LVD) (Liu et al., 2023a) technique to train an HMM with 4096 hidden states on sequences of 32 word tokens. Specifically, LVD is used to obtain a set of “good” initial parameters for the HMM from deep generative models. The HMM language model is then fine-tuned on the CommonGen dataset (Lin et al., 2020), and is subsequently used to control the generation process of (large) language models for constrained generation tasks. Following the same procedure, we use PyJuice to fine-tune two HMMs with hidden sizes 4096 and 8192, respectively.
\ As shown in Table 2, by using the same HMM with 4096 hidden states, PyJuice improved the perplexity by ∼1.0 by running many more epochs in less time compared to the original model. We also train a larger HMM with 8192 hidden states and further improved the perplexity by a further 0.16. We refer the reader to Appendix C.2 for more details.
\ Sparse Image Models. Liu et al. (2023c) design a PC learning algorithm that targets image data by separately training two sets of PCs: a set of sparse patch-level PCs (e.g., 4×4 patches) and a top-level PC that aggregates outputs of the patch-level PC. In the final training step, the PCs are supposed to be assembled and jointly fine-tuned. However, due to the huge memory consumption of the PC (with over 10M nodes), only the top-level model is fine-tuned in the original paper. With PyJuice, we can fit the entire model in 24GB of memory and fine-tune the entire model. For the PC trained on the ImageNet32 dataset (Deng et al., 2009), this
\
\
\ \ fine-tuning step leads to an improvement from 4.06 to 4.04 bits-per-dimension. See Appendix C.3 for more details.
\ \
:::info Authors:
(1) Anji Liu, Department of Computer Science, University of California, Los Angeles, USA (liuanji@cs.ucla.edu);
(2) Kareem Ahmed, Department of Computer Science, University of California, Los Angeles, USA;
(3) Guy Van den Broeck, Department of Computer Science, University of California, Los Angeles, USA;
:::
:::info This paper is available on arxiv under CC BY 4.0 DEED license.
:::
[7] In the adopted HMM, running Dynamax with batch size ≥128 leads to internal errors, and thus the results are not reported.
This content originally appeared on HackerNoon and was authored by Probabilistic
Probabilistic | Sciencx (2025-08-24T23:11:21+00:00) PyJuice Pushes HMMs and Image Models Beyond State-of-the-Art. Retrieved from https://www.scien.cx/2025/08/24/pyjuice-pushes-hmms-and-image-models-beyond-state-of-the-art/
Please log in to upload a file.
There are no updates yet.
Click the Upload button above to add an update.