
This content originally appeared on HackerNoon and was authored by Writings, Papers and Blogs on Text Models
Table of Links
- Background and Motivation
- PowerInfer-2 Overview
- Neuron-Aware Runtime Inference
- Execution Plan Generation
- Implementation
- Evaluation
- Related Work
- Conclusion and References
3 PowerInfer-2 Overview
Traditional LLM inference typically depends on matrix computations as the basic unit of inference, a method that introduces significant computational and I/O overhead in the heterogeneous hardware environments of smartphones. Such coarse-grained computations do not effectively leverage the flexible computational capabilities of XPUs. Worse, if a segment of the matrix weights is stored on the storage device, there must be a delay for these weights to be loaded into memory before matrix computations can begin, leading to considerable I/O wait times.
\
\ This paper introduces PowerInfer-2, a high-speed LLM inference framework specifically designed for smartphones. Its design achieves three goals: 1) Low inference latency: minimizing the inference delay during both the prefill stage (TTFT) and the decoding phase (TBT); 2) Low memory footprint: reducing memory usage during inference, enabling low-latency inference of LLMs even when the model size exceeds the device’s memory limit; 3) Flexibility: ensuring the design can be seamlessly adapted to smartphones with varying computational, memory, and storage capacities.
\
3.1 Neuron Cluster and Architecture
In this paper, we propose a computational abstraction called neuron cluster, which is specifically designed for LLM inference in heterogeneous computing scenarios. PowerInfer-2 performs computation and I/O operations in the granularity of a neuron cluster which can be dynamically composed of multiple activated neurons during computation, with the number of neurons determined by the computational power of the computing unit. For example, during the decoding phase, when computation is performed by the CPU core, the size of neuron clusters assigned to each CPU core is smaller than those handled during NPU computation in the prefill phase. By using this abstraction, PowerInfer-2 can fully utilize XPUs with different computing capabilities. effectively hide the I/O overhead.
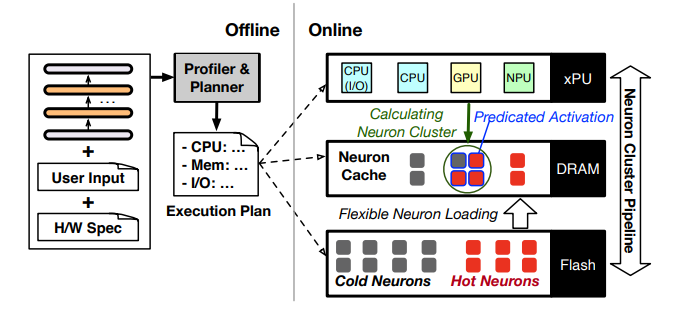
\ Fig.2 illustrates the overall architecture of PowerInfer-2, which is structured into online (the right part) and offline (the left part) procedures. The online part serves the inference at the neuron cluster granularity and includes four collaborative components: the polymorphic neuron engine (§4.1), the in-memory neuron cache (§4.2), flexible neuron loading (§4.3), and neuron-cluster-level I/O pipeline (§4.4).
\ The polymorphic neuron engine uses completely different computation patterns for the prefill and decoding phases. For the prefill phase, the neuron cluster contains all neurons from the weight matrix and relies primarily on the NPU due to its efficiency in handling large matrix-matrix multiplications. For the decoding phase, it invokes a predictor to identify which neurons will be activated before initiating computations. The engine then merges these activated neurons into a small neuron cluster and utilizes a CPU core to dynamically calculate the neuron cluster, thereby drastically reducing computational demands and memory usage during runtime.
\ Before beginning computations for inference, the computing engine retrieves neuron weights from the neuron cache, which is optimized to exploit the locality of neuron-level access observed in LLM inference. In the event of a cache miss, PowerInfer-2 initiates an I/O command to fetch uncached neuron weights from storage. To mitigate I/O latency, PowerInfer-2 introduces a novel pipeline mechanism that concurrently processes neuron cluster and I/O operations. Additionally, PowerInfer-2 minimizes I/O overhead by adaptively bundling and loading neurons, which is determined by the model’s quantization.
\ To automatically adapt to different models or smartphones, the offline procedure is conducted once for each model initially served on a new smartphone before the online inference begins. This process involves receiving three types of inputs: model weights, user inputs, and hardware specifications. It outputs an execution plan that describes the configurations for each component involved in the online inference and guides the online procedure.
\ Specifically, an offline planner outputs configurations for computing, memory, and I/O. For computing, the planner determines the proportionate use of CPU and NPU during different phases or layers based on their computational strengths. In terms of memory configuration, to achieve a balance between memory usage and inference performance, the planner enables users to set a desired inference speed prior to running PowerInfer-2. Based on this speed setting, PowerInfer-2 calculates the optimal cache size needed. For I/O configuration, the planner triggers a profiler to measure the sparsity of the model and the distribution of hot and cold neurons.
\
:::info Authors:
(1) Zhenliang Xue, Co-first author from Institute of Parallel and Distributed Systems (IPADS), Shanghai Jiao Tong University;
(2) Yixin Song, Co-first author from Institute of Parallel and Distributed Systems (IPADS), Shanghai Jiao Tong University;
(3) Zeyu Mi, Institute of Parallel and Distributed Systems (IPADS), Shanghai Jiao Tong University (yzmizeyu@sjtu.edu.cn);
(4) Le Chen, Institute of Parallel and Distributed Systems (IPADS), Shanghai Jiao Tong University;
(5) Yubin Xia, Institute of Parallel and Distributed Systems (IPADS), Shanghai Jiao Tong University;
(6) Haibo Chen, Institute of Parallel and Distributed Systems (IPADS), Shanghai Jiao Tong University.
:::
:::info This paper is available on arxiv under CC BY 4.0 license.
:::
\
This content originally appeared on HackerNoon and was authored by Writings, Papers and Blogs on Text Models
Writings, Papers and Blogs on Text Models | Sciencx (2025-08-26T15:23:55+00:00) The Conductor in Your Pocket: How PowerInfer-2 Orchestrates Smartphone Hardware for LLM Inference. Retrieved from https://www.scien.cx/2025/08/26/the-conductor-in-your-pocket-how-powerinfer-2-orchestrates-smartphone-hardware-for-llm-inference/
Please log in to upload a file.
There are no updates yet.
Click the Upload button above to add an update.