
This content originally appeared on Level Up Coding - Medium and was authored by Yuval Mehta

Search engines and AI systems often rely on retrieval, fetching relevant documents, paragraphs, or passages from massive knowledge sources. But if retrieval alone were enough, every search would be perfect. In reality, the first results you get are often almost right, but not quite.
This is where rerankers step in, the secret sauce that takes raw search results and turns them into precisely what you’re looking for. In this blog, we’ll deep dive into rerankers, how they work, why they matter, and examples of practical improvements they bring.
What is a Reranker?
At a high level:
- Retriever → Quickly fetches a batch of candidate results (say, 50 documents) based on a query.
- Reranker → Scores these candidates and reorders them so the most relevant results appear at the top.
Think of it like this: a retriever is like a bartender who grabs your favorite drinks from the bar fast. A reranker is the sommelier who picks the best one for your taste.
Rerankers are now widely used in search, question-answering, and RAG (Retrieval-Augmented Generation) pipelines, because they provide the extra layer of contextual understanding missing in fast retrieval systems.

Why Not Just Use a Better Retriever?
Good question. Couldn’t we just make the retriever smarter?
- Retrievers are often optimized for speed. Vector search (like FAISS or Pinecone) can fetch thousands of candidates in milliseconds.
- But high-speed retrieval sacrifices fine-grained understanding of context and query intent.
Rerankers, especially cross-encoder models, read each candidate carefully in context with the query. This extra step dramatically improves accuracy, even if it costs a little time.
How Rerankers Work (Technically)
Most rerankers are pretrained transformer models (like BERT, RoBERTa, or cross-encoder variants). They work like this:
- Concatenate the query and candidate:
[CLS] query: "How to fine-tune BERT?" [SEP] document: "Fine-tuning BERT requires learning rate schedules…" [SEP]
- Feed it through a transformer → produce a relevance score.
- Rank candidates by score → top results are returned.
Example:
- Query: “Best AI libraries for NLP in 2025”
- Retriever top 5: Hugging Face Transformers, Spacy, NLTK, PyTorch, TensorFlow
- Reranker top 3: Hugging Face Transformers, PyTorch, Spacy
Notice how the reranker prioritizes libraries most relevant and up-to-date for the query.
Code Example
We’ll use Hugging Face’s cross-encoder/ms-marco-MiniLM-L-6-v2, a lightweight and fast reranker suitable for demonstration.
# Install dependencies (if not already installed)
# pip install sentence-transformers
from sentence_transformers import CrossEncoder
# Load a pretrained cross-encoder model
model = CrossEncoder('cross-encoder/ms-marco-MiniLM-L-6-v2')
# Define a query and candidate documents
query = "Best AI libraries for NLP in 2025"
documents = [
"Hugging Face Transformers provides state-of-the-art NLP models.",
"PyTorch is a versatile deep learning framework used for NLP and CV.",
"NLTK is an older library for text processing and simple NLP tasks.",
"TensorFlow is a deep learning framework often used for large models.",
"Spacy is optimized for industrial NLP pipelines."
]
# Prepare input pairs (query, document) for the reranker
pairs = [[query, doc] for doc in documents]
# Get relevance scores for each document
scores = model.predict(pairs)
# Combine documents and scores, then sort
ranked_docs = sorted(zip(documents, scores), key=lambda x: x[1], reverse=True)
# Print reranked results
print("Reranked Documents:")
for doc, score in ranked_docs:
print(f"{score:.4f} - {doc}")
What this does:
- The cross-encoder takes the query + each document pair.
- It outputs a relevance score for each document.
- Documents are then sorted by score, producing a reranked list.
Expected Output (example):
0.9123 - Hugging Face Transformers provides state-of-the-art NLP models.
0.8765 - PyTorch is a versatile deep learning framework used for NLP and CV.
0.8432 - Spacy is optimized for industrial NLP pipelines.
0.7012 - TensorFlow is a deep learning framework often used for large models.
0.6541 - NLTK is an older library for text processing and simple NLP tasks.
Here, the reranker correctly prioritizes the most relevant libraries for modern NLP workflows.
Practical Benefits of Rerankers
- Higher Precision at Top Results — Essential for QA, RAG, and enterprise search.
- Better Context Understanding — Detects subtle query-document mismatches.
- Plug-and-Play with Existing Systems — Works on top of vector search, Elasticsearch, or BM25.
Example in RAG (Retrieval-Augmented Generation):
- Retriever fetches 50 documents.
- Reranker narrows to 5 top documents.
- LLM uses these top 5 for answer generation → reduces hallucinations and improves factual accuracy.
Tradeoffs
While rerankers are powerful, they come with costs:
- Latency: Cross-encoder rerankers are slower than retrievers.
- Compute: Rerankers need GPU/CPU resources for scoring candidates.
The solution? Hybrid pipelines: fast retriever → light reranker (e.g., miniLM) → heavy reranker if needed. This provides a balance between speed and accuracy.
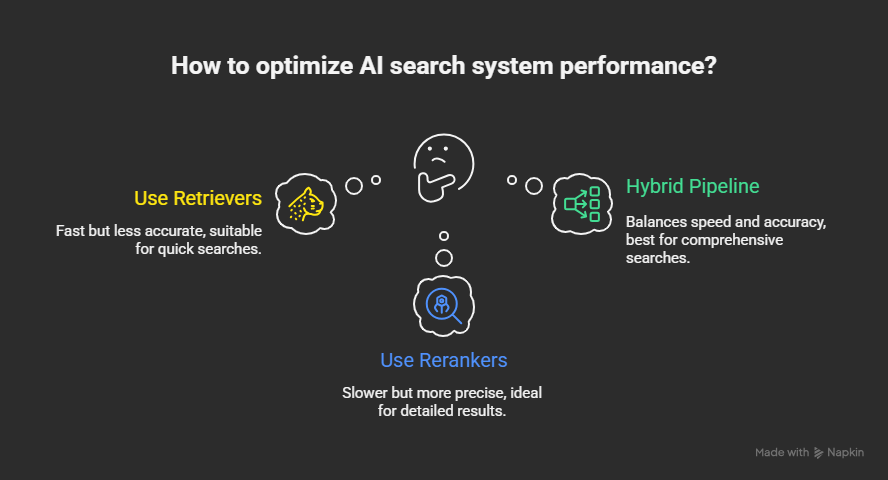
TL;DR
- Retrievers are fast but rough.
- Rerankers are slower but precise.
- Together, they unlock high-quality results in AI search systems.
Rerankers are why some search engines feel magical — results that just “click.” Without them, even the best retrievers leave gaps in relevance and accuracy.
Teaser for Next Blog
In my next blog, we’ll go deeper into “Retriever vs Reranker in RAG”:
- How these components split responsibilities in modern pipelines
- Real-world examples with code and benchmarks
- How to decide which reranker architecture fits your use case
Stay tuned if you want to truly master retrieval-augmented systems.
References
- Nogueira, R., & Cho, K. (2019). Passage Re-ranking with BERT. arXiv:1901.04085
- Lewis, P., et al. (2020). Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks. arXiv:2005.11401
- Reimers, N., & Gurevych, I. (2019). Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks. arXiv:1908.10084
- Hugging Face Cross-Encoder Documentation. https://huggingface.co/docs/transformers/model_doc/cross-encoder
- FAISS Library. https://github.com/facebookresearch/faiss
- Pinecone Vector DB. https://www.pinecone.io/
Why Rerankers Are the Secret Sauce in Modern Retrieval Systems was originally published in Level Up Coding on Medium, where people are continuing the conversation by highlighting and responding to this story.
This content originally appeared on Level Up Coding - Medium and was authored by Yuval Mehta
Yuval Mehta | Sciencx (2025-10-01T14:45:20+00:00) Why Rerankers Are the Secret Sauce in Modern Retrieval Systems. Retrieved from https://www.scien.cx/2025/10/01/why-rerankers-are-the-secret-sauce-in-modern-retrieval-systems/
Please log in to upload a file.
There are no updates yet.
Click the Upload button above to add an update.