
This content originally appeared on Level Up Coding - Medium and was authored by Jarek Orzel
Redis is often praised as one of the simplest yet most powerful databases. Its key-value model is blazing fast for direct lookups, but when it comes to querying by ranges, ranks, or sorting, Redis doesn’t give you much out of the box. Unless, of course, you know about ZSETs.
A ZSET (sorted set) is Redis’ answer to the question: “How do I efficiently query ordered data?” With ZSETs you can get things like top N players by score, all values between X and Y, or the rank of a specific member in logarithmic time. Under the hood, ZSETs are powered by a surprisingly elegant data structure: the skiplist.
This post breaks down how skiplists work, why Redis chose them, and how insertion, removal, and rank queries actually operate. By the end, you’ll understand why ZSETs can feel like magic when combined with normal Redis keys.
Skiplist Basics: A Tower of Linked Lists
At first glance, a skiplist looks like a bunch of linked lists stacked on top of each other. Each element (called a node) may appear in multiple levels. The higher the level, the fewer nodes exist there, acting like express lanes for fast searching.
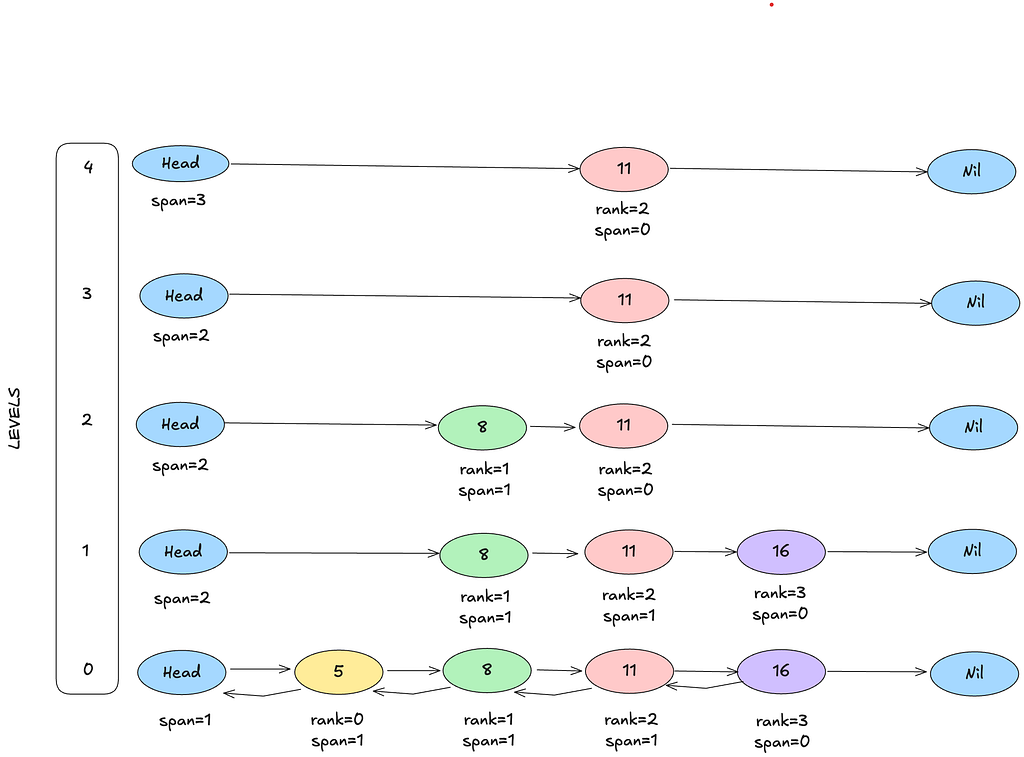
Here’s what makes a skiplist tick:
- Multilevel Nodes: Each node randomly decides how tall it is. Some are short, some are skyscrapers. Tall nodes act as shortcuts when searching.
- Probability p: This is the coin flip that determines how high a node grows. Redis uses p = 0.25. That means ~25% (0.25 * 100%) of nodes appear on level 2, ~6% (0.25 * 0.25 * 100%) on level 3, ~1.5% (0.25 * 0.25 * 0.25 * 100%) on level 4, etc.
- MaxLevel: The upper bound on how tall nodes can be. Redis picked 32. With billions of elements, you’re still safe from degenerating into O(n).
- Forward pointers: At each level, nodes point to the next node in order.
- Spans: Each forward pointer doesn’t just link to the next node, it also says how many nodes are being skipped at this level. That’s the secret sauce for rank queries.
- Backward pointer: At the lowest level, nodes also point back to their predecessor. This helps with reverse scans.
The result: searching, inserting, and deleting are all expected O(log n) operations. Unlike trees, skiplists achieve this with very simple code and without painful balancing logic. The trade-off is that performance is probabilistic, but the odds of a bad case are astronomically small.
In the next few paragraphs, I would like to show how skiplists work. I am going to keep the implementation as minimal as possible to avoid overloading readers (the codebase can be found in the repository).
How Random Levels Are Chosen
When inserting a new element, we don’t deterministically assign a level. Instead, we flip a weighted coin until it comes up tails.
- Start at level 0.
- While rand() < p, increase level.
- Stop when tails, or when maxLevel is reached.
rnd := rand.New(rand.NewSource(time.Now().UnixNano()))
// randomLevel generates a random level for a new node
// with probability p for each level
// the lower the p, the less likely to have high levels
func randomLevel() int {
lvl := 0
for lvl < maxLevel && rnd.Float64() < p {
lvl++
}
return lvl
}
This randomness ensures a geometric distribution of node heights. Most nodes are small, a few are tall, and a tiny handful become “towers” that accelerate searches. With p=0.25 and maxLevel=32, you expect fewer than one node out of 10^18 to hit the max.
Insert Member
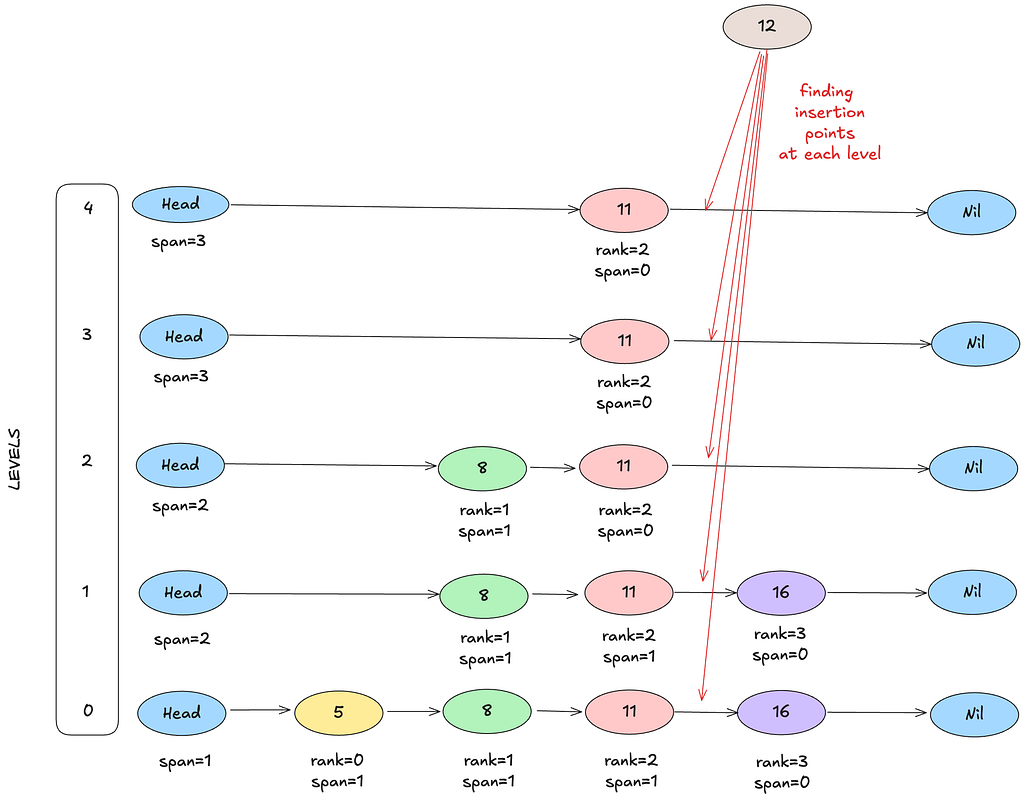
To insert (score, member):
- Start from the header (head) node (a sentinel that has no real value).
- At each level, move forward until you would overshoot the target.
- Keep track of these insertion points.
- Flip coins to decide the level of the new node.
- Splice it in by updating forward pointers and spans.
- Fix backward pointers.
func (s *Skiplist) Insert(score float64, member string) *node {
update := make([]*node, maxLevel)
rank := make([]int, maxLevel)
x := s.header
// 1) find update[] and rank[]
for i := s.level-1; i >= 0; i-- {
if i == s.level-1 {
rank[i] = 0
} else {
rank[i] = rank[i+1]
}
for x.forward[i] != nil && less(x.forward[i].score, x.forward[i].member, score, member) {
rank[i] += x.span[i]
x = x.forward[i]
}
update[i] = x
}
// 2) random level
lvl := s.randomLevel()
if lvl > s.level {
for i := s.level; i < lvl; i++ {
update[i] = s.header
update[i].span[i] = s.length
rank[i] = 0
}
s.level = lvl
}
// 3) create node and splice
x = newNode(lvl, score, member)
for i := 0; i < lvl; i++ {
x.forward[i] = update[i].forward[i]
update[i].forward[i] = x
// spans
x.span[i] = update[i].span[i] - (rank[0] - rank[i])
update[i].span[i] = (rank[0] - rank[i]) + 1
}
// 4) increment span for untouched levels
for i := lvl; i < s.level; i++ {
update[i].span[i]++
}
// 5) backward pointer + fix neighbor
if update[0] == s.header {
x.backward = nil
} else {
x.backward = update[0]
}
if x.forward[0] != nil {
x.forward[0].backward = x
}
s.length++
return x
}Because spans tell us how many nodes each jump covers, they are carefully adjusted during insertion.
Remove Member
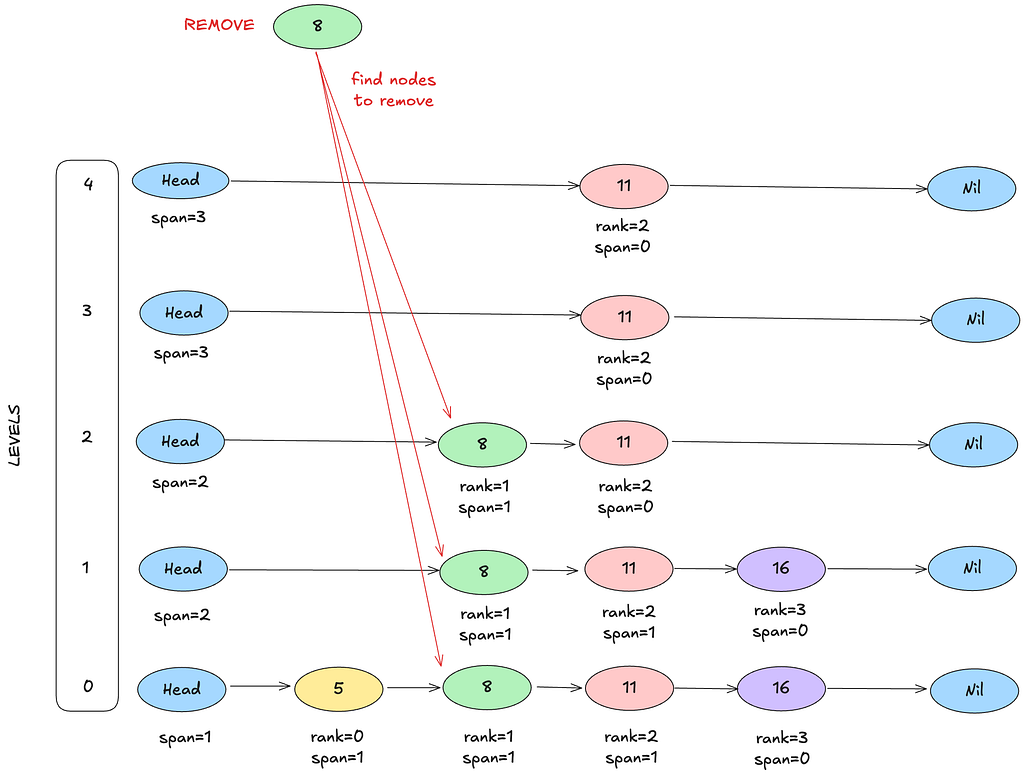
Removal is similar:
- Find the removal points at each level.
- Update their forward pointers to skip over the target (the node before node-to-remove should now point to noid-to-remove.forward.
- Adjust spans accordingly.
- Fix backward pointers.
func (s *Skiplist) Remove(score float64, member string) bool {
update := make([]*node, maxLevel)
x := s.header
for i := s.level-1; i >= 0; i-- {
for x.forward[i] != nil && less(x.forward[i].score, x.forward[i].member, score, member) {
x = x.forward[i]
}
update[i] = x
}
target := x.forward[0]
if target == nil || target.score != score || target.member != member {
return false // not found
}
for i := 0; i < s.level; i++ {
if update[i].forward[i] == target {
update[i].span[i] += target.span[i] - 1
update[i].forward[i] = target.forward[i]
} else {
update[i].span[i]--
}
}
if target.forward[0] != nil {
target.forward[0].backward = target.backward
}
for s.level > 1 && s.header.forward[s.level-1] == nil {
s.level--
}
s.length--
return true
}If the removed node was the tallest, the overall skiplist level may shrink.
Rank: Counting Skips (Spans)
Rank is where spans shine. Imagine asking: What’s the index of member X in sorted order?
During the search for (score, member):
- We start from the top level.
- Every time we move forward at level i (the condition to continue iteration on the level iis forward.score < score), we add that edge’s span[i] to a running total.
- When we finally land on the node, the accumulated total is its rank.
// GetRank returns the rank (0-based index) of the node with the given (score, member).
func (s *Skiplist) GetRank(score float64, member string) int {
x := s.header
rank := 0
for i := s.level - 1; i >= 0; i-- {
for x.forward[i] != nil && less(x.forward[i].score, x.forward[i].member, score, member) {
rank += x.span[i]
x = x.forward[i]
}
}
x = x.forward[0]
if x != nil && x.score == score && x.member == member {
return rank
}
return -1
}
That’s O(log n) rank calculation, something that would otherwise require walking the entire base linked list.
Case 1: GetRank(8, "8")
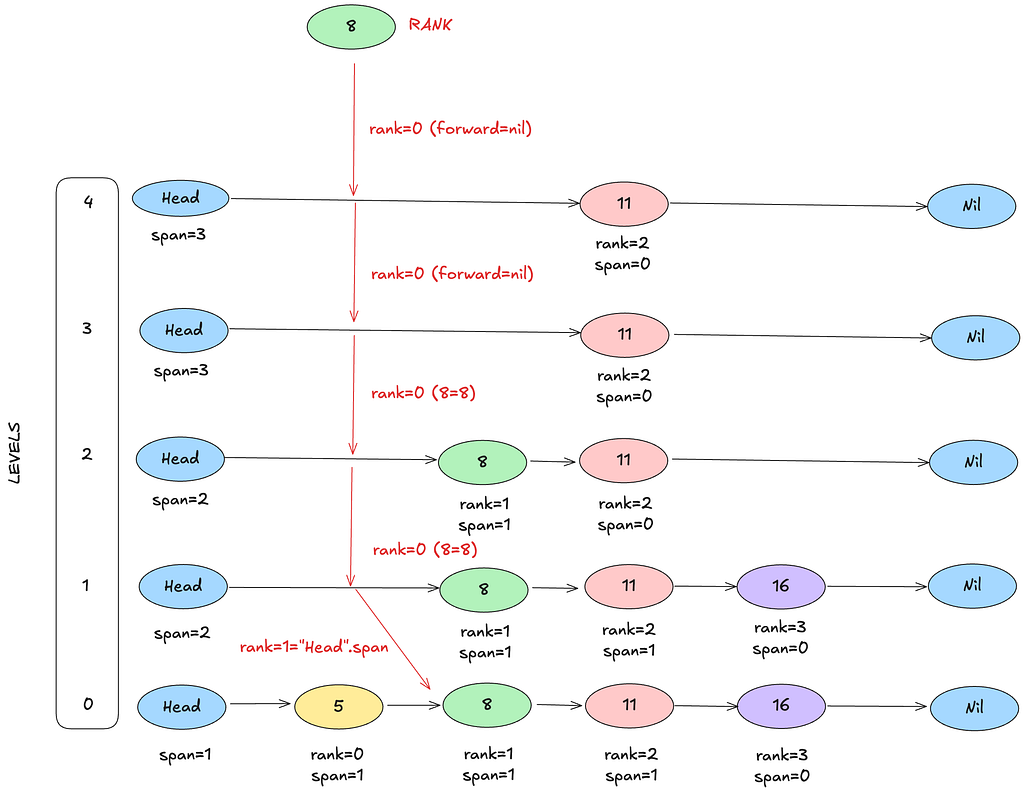
Start: x=head, rank=0.
Level 4
- head.forward[4] = 11.
- Is 11 < 8? → no.
- Stay put.
Level 3
- Same check: 11 < 8? → no.
- Stay put.
Level 2
- head.forward[2] = 8.
- 8 < 8? → no.
- Stay put.
Level 1
- head.forward[1] = 8.
- 8 < 8? → no.
- Stay put.
Level 0
- head.forward[0] = 5.
- 5 < 8? → yes → take jump.
- rank += head.span[0] = 1
- rank = 1
- x = 5
- Next forward: x.forward[0] = 8 → 8 < 8? → no.
After loop: x = x.forward[0] = 8. Target matches → return rank = 1.
Case 2: GetRank(16, "16")
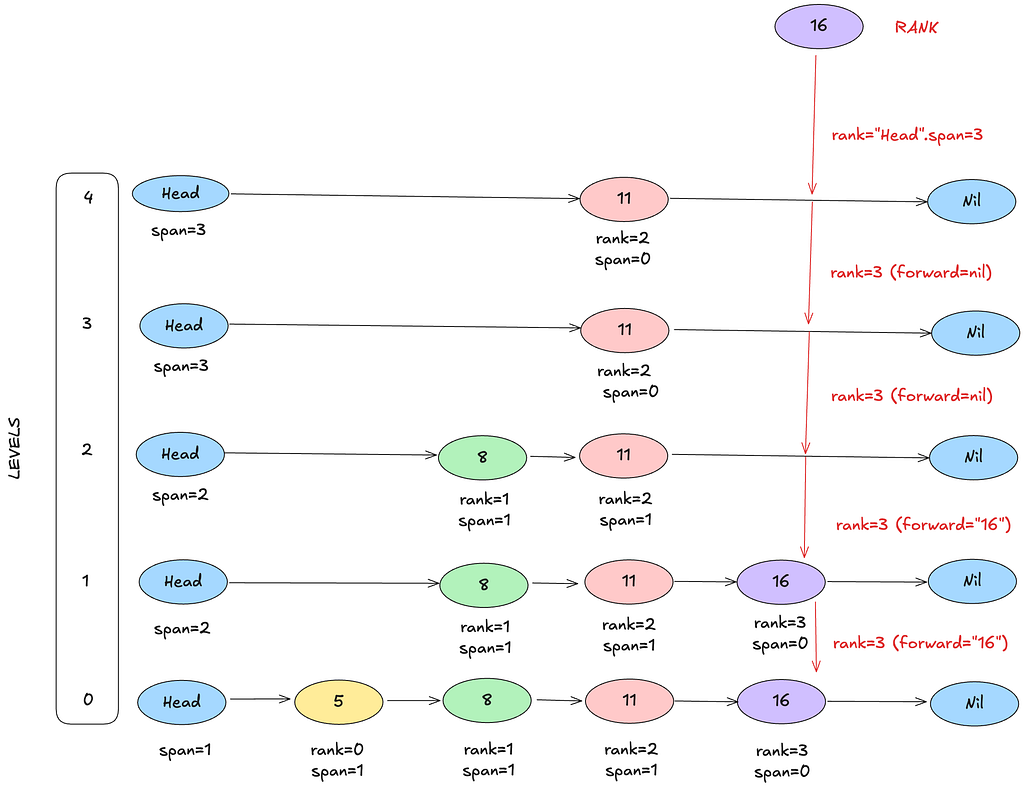
Start: x=head, rank=0.
Level 4
- head.forward[4] = 11.
- 11 < 16? → yes → take jump.
- rank += head.span[4] = 3
- rank = 3
- x = 11
- Next forward: x.forward[4] = nil → stop inner loop.
Level 3
- From x=11, x.forward[3] = nil. → stay.
Level 2
- From x=11, x.forward[2] = nil. → stay.
Level 1
- From x=11, x.forward[1] = 16.
- 16 < 16? → no. → stay.
Level 0
- From x=11, x.forward[0] = 16.
- 16 < 16? → no.
After loop: x = x.forward[0] = 16. Target matches → return rank = 3.
Redis’ Trick
Redis doesn’t just use a skiplist. It combines:
- A dict (hash table): member → node, for O(1) direct lookups.
- A skiplist: keeps members ordered by score and member name for O(log n) range queries and rank calculations.
This hybrid gives the best of both worlds. Combining those two structures allows us to easily implement basic zset operations like: ZAdd, ZRem, ZRank and ZRange.
import "github.com/jorzel/skiplist/skiplist"
type Zset struct {
sl skiplist.Skiplist
dict map[string]float64
}
// Add or update member
// ZAdd https://redis.io/docs/latest/commands/zadd/
func (z *Zset) Add(score float64, member string) {
if n, ok := z.dict[member]; ok {
z.sl.Remove(n.score, member)
}
n := z.sl.Insert(score, member)
z.dict[member] = n
}
// Remove member
// ZRem https://redis.io/docs/latest/commands/zadd/
func (z *Zset) Remove(member string) bool {
n, ok := z.dict[member]
if !ok {
return false
}
ok = z.sl.Remove(n.score, member)
if ok {
delete(z.dict, member)
}
return ok
}
// Rank Member returns zero-based rank, or -1 if not present
// ZRank https://redis.io/docs/latest/commands/zrank/
func (z *ZSet) Rank(member string) int {
score, ok := z.dict[member]
if !ok { return -1 }
return z.sl.GetRank(score, member)
}
// Range Members by rank inclusive [start,stop], supports negative indices like Redis
// ZRange https://redis.io/docs/latest/commands/zrank/
func (z *ZSet) Range(start, stop int) []string {
n := z.sl.length
if n == 0 { return nil }
// normalize negative indices
if start < 0 { start = n + start }
if stop < 0 { stop = n + stop }
if start < 0 { start = 0 }
if stop < 0 { return nil }
if start > stop || start >= n { return nil }
if stop >= n { stop = n-1 }
results := make([]string, 0, stop-start+1)
node := z.sl.GetByRank(start)
for i := start; i <= stop && node != nil; i++ {
results = append(results, node.member)
node = node.forward[0]
}
return results
}
This mirrors how Redis’ ZSET is implemented in C: dict + zskiplist.
Conclusion
ZSETs are surprisingly versatile once you know what powers them:
- Leaderboards (players ranked by score).
- Time-series queries (timestamps as scores).
- Priority queues (scores as priorities).
- Secondary indexes (scores encode derived values).
Even though Redis doesn’t give you SQL-like querying, a clever combination of keys + ZSETs makes it possible to implement efficient searching patterns.
Redis ZSETs look simple on the surface, but under the hood, they rely on a beautifully clever data structure: the skiplist. With random levels, forward pointers, spans, and a hybrid design that pairs a dict with the skiplist, Redis achieves fast lookups, inserts, deletes, and rank queries — all in O(log n).
Compared to balanced trees, skiplists are easier to code, almost as fast, and probabilistically robust. That’s why Redis chose them. And now, hopefully, you see why ZSET is one of the most powerful features in Redis: it turns a plain key-value store into a fast, query-capable data structure.
Once again, the skiplist implementation can be found here.
Redis and the Magic of ZSET was originally published in Level Up Coding on Medium, where people are continuing the conversation by highlighting and responding to this story.
This content originally appeared on Level Up Coding - Medium and was authored by Jarek Orzel
Jarek Orzel | Sciencx (2025-10-06T14:29:47+00:00) Redis and the Magic of ZSET. Retrieved from https://www.scien.cx/2025/10/06/redis-and-the-magic-of-zset/
Please log in to upload a file.
There are no updates yet.
Click the Upload button above to add an update.