
This content originally appeared on Level Up Coding - Medium and was authored by Muhammad Faisal Ishfaq
DeepSeek-OCR: The Vision Token Escape Hatch: How One Image-Based OCR Model Rewrites the Context Window Rulebook
When you watch an LLM devour a 100-page PDF, you assume it’s crunching thousands upon thousands of text tokens — the longer the context, the more the cost, the more the trade-offs. But what if the real shift wasn’t in scaling out tokens but in disappearing them entirely?
In a recent study, DeepSeek-AI unveiled a bold idea: convert the very text you’d feed into an LLM into a compact image, then let the model read that instead. The result? A context window escape hatch where thousands of text tokens map to a few hundred vision tokens — and yet the model can still reconstruct meaning with surprising fidelity.
This isn’t just another OCR story. It reframes a core assumption of large-language and vision models: it’s not just “how many tokens can I feed,” but “what kind of tokens should I feed?”.
The conventional cost trap
In most LLM or document-AI pipelines, you have something like this: image → OCR text tokens → text input to LLM.
Every line of text becomes a token. Every diagram becomes a burst of tokens. The cost grows roughly with text length (often quadratically). Developers say: “Long-document input? Good luck.”
Yet DeepSeek-OCR asks a different question: what if the model itself never sees the raw tokens, but rather an image that faithfully encodes them? The image becomes a compressed representation of thousands of tokens. Suddenly you’re trading token count for vision tokens — and vision tokens behave differently in context windows.

Understanding the compression engine
At the heart of DeepSeek-OCR are two components:
- DeepEncoder: a vision encoder designed to ingest high-resolution document images and output a small number of vision tokens, with exceptionally low activation cost.
- DeepSeek3B-MoE-A570M Decoder: a modular, mixture-of-experts decoder that treats the vision tokens as input and reconstructs or understands the full document context.
To understand the system, it helps to look at the model’s architecture.
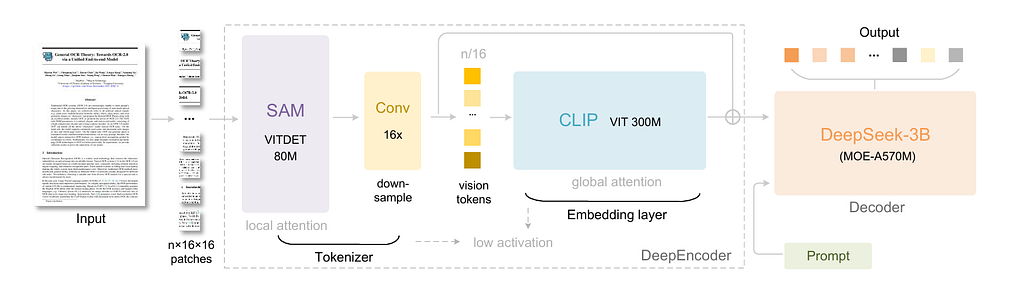
Here’s how it works in simple terms: you feed the entire document page into DeepEncoder. It processes layout, text, diagrams, and visual context — and compresses them into maybe 100–800 vision tokens depending on your budget. The decoder then acts as if those vision tokens were rich context, performing OCR, layout understanding, semantic parsing.
What the authors found is remarkable: when the compression ratio (text tokens : vision tokens) stays at under ~10×, reconstruction accuracy is about 97%. Even at ~20× compression, accuracy is still around 60%.

The experiment and benchmarks
To demonstrate its practicality, the study reports several experiments:
- On OmniDocBench, DeepSeek-OCR outperforms traditional OCR pipelines. For example, while GOT-OCR2.0 uses ~256 tokens per page, DeepSeek-OCR used as few as 100 vision tokens and still matched or exceeded accuracy.
- On MinerU2.0 (models previously using 6,000+ tokens per page on average) DeepSeek-OCR achieved competitive performance with fewer than 800 vision tokens.
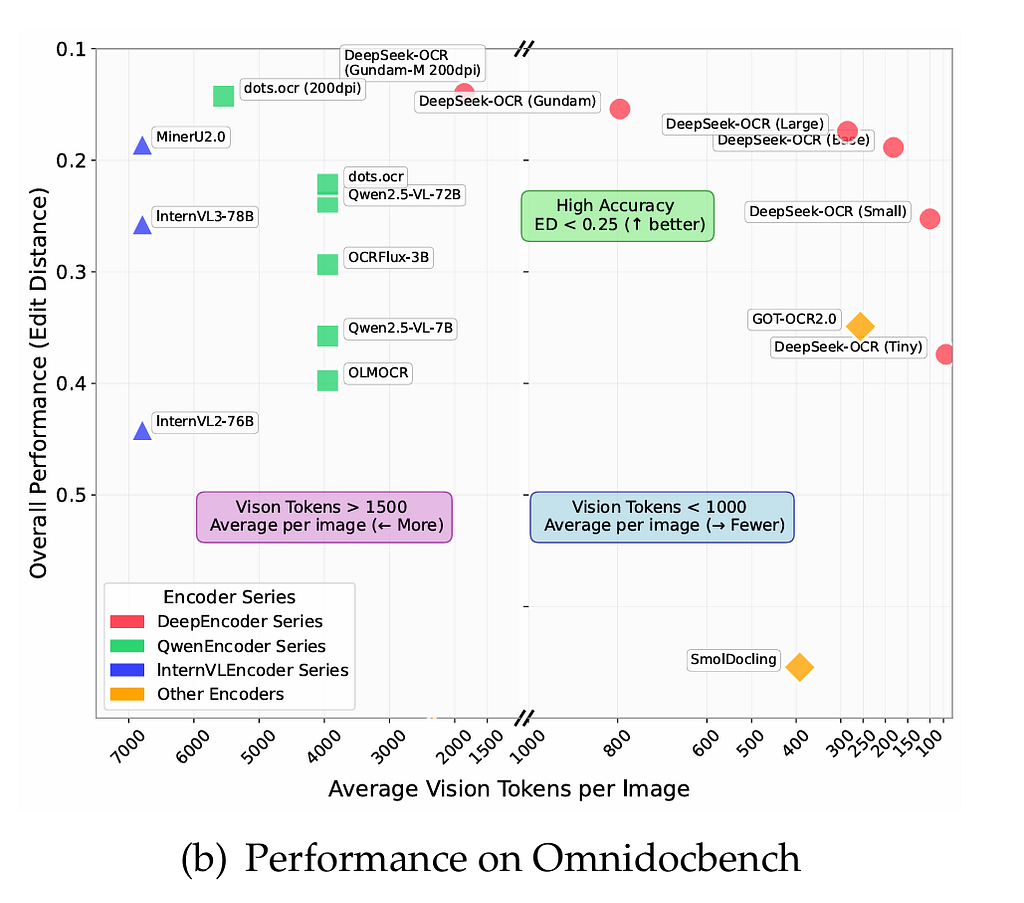

These are not simply micro-benchmarks. In production, the authors claim:
“We can process over 200k pages per day on a single A100–40G.”
This matters for long-document, enterprise, archival, multilingual workflows where cost and context length are big blockers.
Beyond OCR: Why this really matters
Why did this compression idea take off? Because it flips a core challenge of long-context LLMs on its head.
- Token budget explosion: Feeding multiple pages into an LLM text-token stream is expensive and inefficient.
- Layout + semantics: Classic OCR loses layout, diagrams, tables, complexities.
- Vision-text coupling: By treating the document as an image, layout is preserved implicitly, and semantics can still be decoded via the vision-token-to-decoder path.

Here, the visualization depicts how a page’s layout flows through the encoder into a compressed vision-token space, then into the decoder. You can “see” the flow of meaning preserved even as the data size shrinks drastically.
In essence, the model says: “Give me fewer tokens, if those tokens hold richer signals.” And DeepSeek-OCR shows that this is not just theoretical — it works.
Trade-offs, limitations and architecture choices
No model is perfect, and the paper is honest about trade-offs:
- High compression → accuracy drop: The accuracy stays high for ~10× compression, but when pushed toward ~20×, it falls significantly (~60%). That’s still impressive but signals caution.
- Document quality matters: High-resolution input, clean scans, consistent typography all help. Low-quality scans or unusual layouts degrade performance.
- Decoder complexity: The MoE decoder is non-trivial; real-world deployment still needs engineering care.
- Domain specificity: The benchmarks are strong, but extreme cases (complex formulas, heavy diagrams, non-Latinate scripts) may still challenge the system.
The new paradigm of “optical context”
What makes DeepSeek-OCR more than just a faster OCR tool is its framing of documents as “optical contexts”.
We’ve moved from thinking “image → text → model” to “image → vision tokens → model.” The document becomes a first-class input, not just a source of extracted text.
That shift matters for multiple domains:
- Legal/financial with 500-page contracts
- Scientific/academic with many tables, diagrams
- Multilingual/vertical archives with exotic scripts


The narrative changes from “How many text tokens can we afford?” to “How few vision tokens can we use while retaining meaning?”
In so doing, DeepSeek-OCR suggests that token efficiency and context handling might be the next frontier beyond “more parameters”.
Reflection: Compressing context, not capabilities
At its core, this is not just about OCR. It is about how we represent, feed and reason over information in large models.
By showing that a page of text, diagrams, layout and semantics can be compressed into a few hundred tokens — and still understood by an LLM — the DeepSeek-OCR paper opens a door into a new way of thinking:
We don’t just scale contexts. We transform them.
For developers, engineers and researchers, the implication is profound. Our models become powerful not only when they get more data, but when we make their inputs more efficient. When we shrink the context window without shrinking meaning.
In the age where context is king, DeepSeek-OCR says: sometimes the king rides in the smallest carriage.
DeepSeek-OCR: The Vision Token Escape Hatch: How One Image-Based OCR Model Rewrites the Context… was originally published in Level Up Coding on Medium, where people are continuing the conversation by highlighting and responding to this story.
This content originally appeared on Level Up Coding - Medium and was authored by Muhammad Faisal Ishfaq
Muhammad Faisal Ishfaq | Sciencx (2025-11-03T03:09:38+00:00) DeepSeek-OCR: The Vision Token Escape Hatch: How One Image-Based OCR Model Rewrites the Context…. Retrieved from https://www.scien.cx/2025/11/03/deepseek-ocr-the-vision-token-escape-hatch-how-one-image-based-ocr-model-rewrites-the-context/
Please log in to upload a file.
There are no updates yet.
Click the Upload button above to add an update.