
This content originally appeared on HackerNoon and was authored by Web Fonts
Table of Links
1.1 Printing Press in Iraq and Iraqi Kurdistan
1.2 Challenges in Historical Documents
Related work and 2.1 Arabic/Persian
Method and 3.1 Data Collection
3.2 Data Preparation and 3.3 Preprocessing
3.4 Environment Setup, 3.5 Dataset Preparation, and 3.6 Evaluation
Experiments, Results, and Discussion and 4.1 Processed Data
5 Conclusion
The primary motivation for this study stems from the significant amounts of historical documents stored in libraries that still need to be processed. The lack of processing capabilities has led to exploring OCR technology for Kurdish, a low-resource language. Implementing OCR for extracting text from historical documents in Kurdish would greatly enhance available resources.
\ Extensive research was conducted to assess existing OCR systems for Kurdish and other languages worldwide. The investigation focused on previous work, accuracy, and underlying
\

\
\
\
\
\ technology. It was determined that Tesseract was a suitable option for this research.
\ Once the technology was identified, efforts were made to collect digital copies of historical documents printed before 1950. This task proved challenging, as locating documents and converting them into digital format presented additional hurdles. Fortunately, the Zheen Center for Documentation and Research in Sulaymaniyah, which specializes in archiving historical documents, provided some books in the form of digital copies.
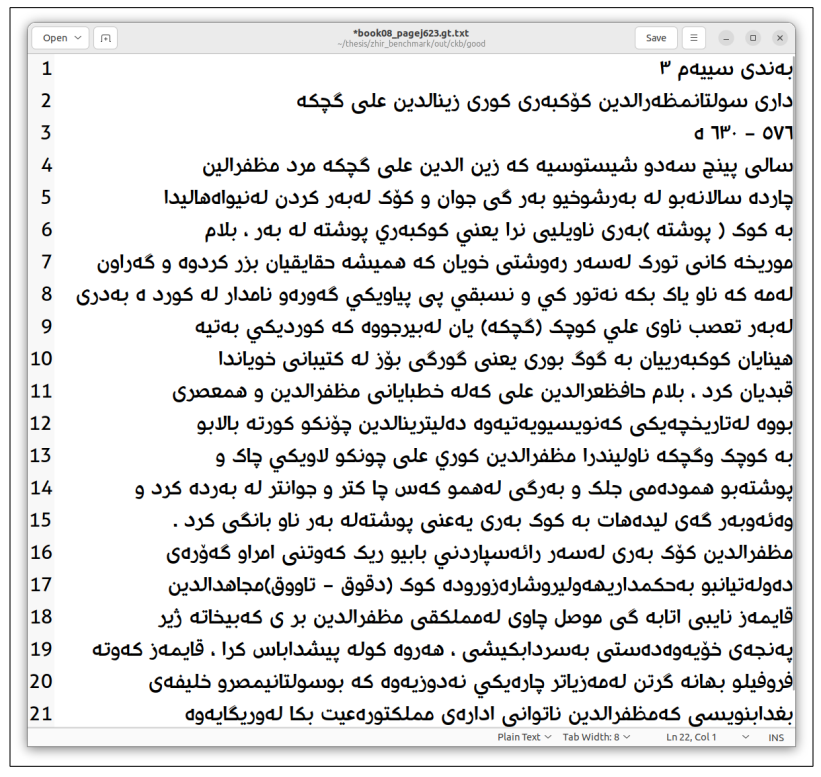
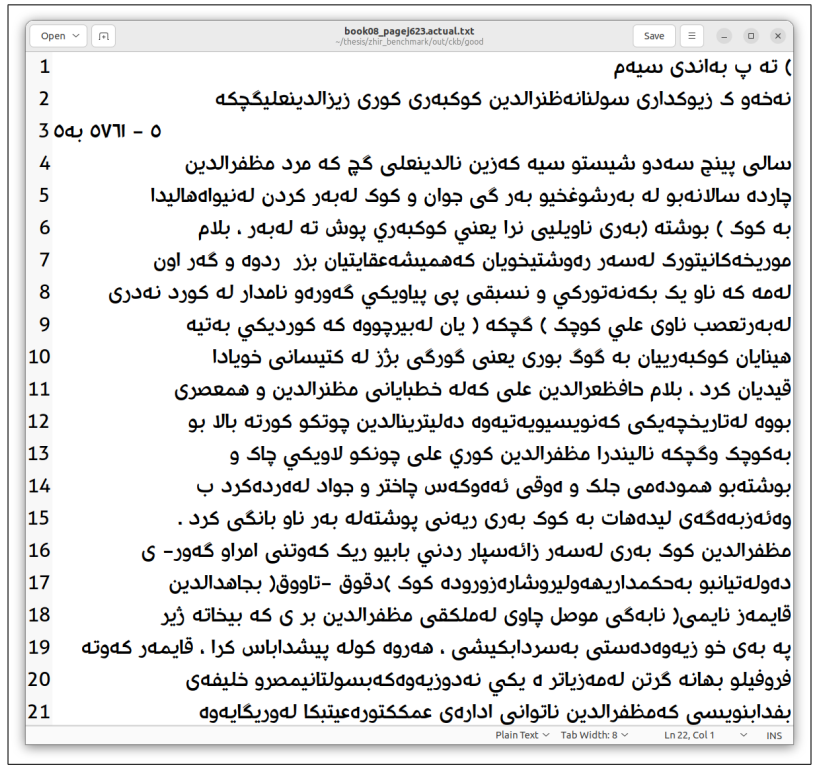
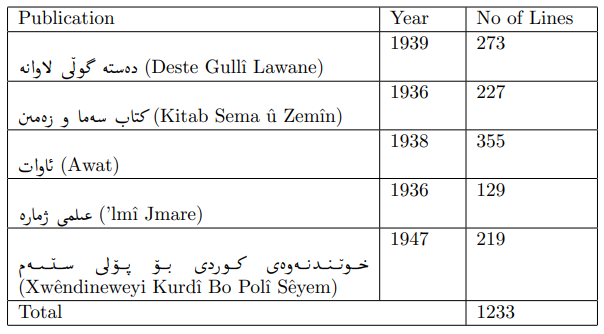
\ Upon receiving the digitized copies, a dataset was created to train the Tesseract model. Text lines were extracted from the pages, transcribed individually, and subjected to preprocessing to prepare the dataset.
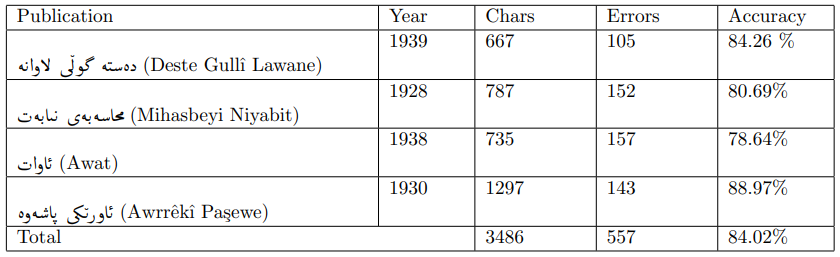
\ With a dataset of 1233 lines, the model was trained based on the Arabic model. Following the training, the model’s performance was evaluated using various methods. Tesseract’s built-in evaluator lstmeval indicated a CER of 0.755%. Additionally, Ocreval demonstrated an average character accuracy of 84.02%. Finally, an in-house web application was developed to provide an easy-to-use interface for end-users, allowing them to interact with the model by inputting an image of a page and extracting the text.
\ This model could be a valuable tool for libraries and centers, enabling them to extract text from historical documents and perform further processing effectively.
\
:::info Authors:
(1) Blnd Yaseen, University of Kurdistan Howler, Kurdistan Region - Iraq (blnd.yaseen@ukh.edu.krd);
(2) Hossein Hassani University of Kurdistan Howler Kurdistan Region - Iraq (hosseinh@ukh.edu.krd).
:::
:::info This paper is available on arxiv under ATTRIBUTION-NONCOMMERCIAL-NODERIVS 4.0 INTERNATIONAL license.
:::
\
This content originally appeared on HackerNoon and was authored by Web Fonts
Web Fonts | Sciencx (2025-08-20T07:00:03+00:00) Training Tesseract for Low-Resource Languages. Retrieved from https://www.scien.cx/2025/08/20/training-tesseract-for-low-resource-languages/
Please log in to upload a file.
There are no updates yet.
Click the Upload button above to add an update.