
This content originally appeared on HackerNoon and was authored by Instancing
Table of Links
Related Work
2.1 Open-world Video Instance Segmentation
2.2 Dense Video Object Captioning and 2.3 Contrastive Loss for Object Queries
2.4 Generalized Video Understanding and 2.5 Closed-World Video Instance Segmentation
\ Supplementary Material
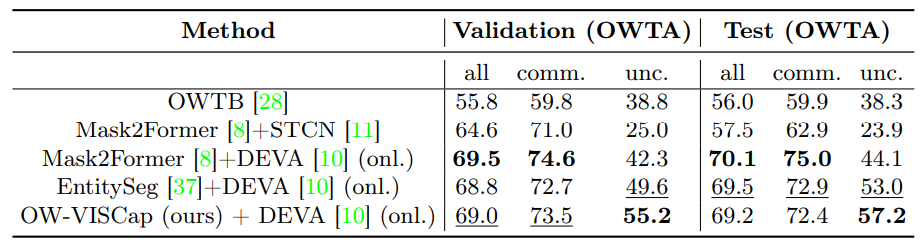
3 Approach
Given a video, our goal is to jointly detect, segment and caption object instances present in the video. Importantly, note that object instance categories may not be part of the training set (e.g., the parachutes shown in Fig. 3 (top row)), placing our goal in an open-world setting. To achieve this goal, a given video is first broken into short clips, each consisting of T frames. Each clip is processed using our approach OW-VISCap. We discuss merging of the results of each clip in Sec. 4.
\ We provide an overview of OW-VISCap to process each clip in Sec. 3.1. We then discuss our contributions: (a) introduction of open-world object queries in Sec. 3.2, (b) use of masked attention for object-centric captioning in Sec. 3.3, and (c) use of inter-query contrastive loss to ensure that the object qeries are different from each other in Sec. 3.4. In Sec. 3.5, we discuss the final training objective.
3.1 Overview

\ Both open- and closed-world object queries are processed by our specifically designed captioning head which yields an object-centric caption, a classification head which yields a category label, and a detection head which yields either a segmentation mask or a bounding-box.
\

\ We introduce an inter-query contrastive loss to ensure that the object queries are encouraged to differ from each other. We provide details in Sec. 3.4. For closed world objects, this loss helps in removing highly overlapping false positives. For open-world objects, it helps in the discovery of new objects.
\ Finally, we provide the full training objective in Sec. 3.5.
\
3.2 Open-World Object Queries

\

\

\ We first match the ground truth objects with the open-world predictions by minimizing a matching cost using the Hungarian algorithm [34]. The optimal matching is then used to calculate the final open-world loss.
\

\
3.3 Captioning Head

\

\
3.4 Inter-Query Contrastive Loss
\

\
3.5 Training
Our total training loss is

\
\
![Table 2: Dense video object captioning results on the VidSTG [57] dataset. Off. indicates offline methods and onl. refers to online methods.](https://cdn.hackernoon.com/images/null-0v3336a.png)
\
:::info Authors:
(1) Anwesa Choudhuri, University of Illinois at Urbana-Champaign (anwesac2@illinois.edu);
(2) Girish Chowdhary, University of Illinois at Urbana-Champaign (girishc@illinois.edu);
(3) Alexander G. Schwing, University of Illinois at Urbana-Champaign (aschwing@illinois.edu).
:::
:::info This paper is available on arxiv under CC by 4.0 Deed (Attribution 4.0 International) license.
:::
\
This content originally appeared on HackerNoon and was authored by Instancing
Instancing | Sciencx (2025-11-04T09:46:04+00:00) Teaching AI to See and Speak: Inside the OW‑VISCap Approach. Retrieved from https://www.scien.cx/2025/11/04/teaching-ai-to-see-and-speak-inside-the-ow%e2%80%91viscap-approach/
Please log in to upload a file.
There are no updates yet.
Click the Upload button above to add an update.