
This content originally appeared on HackerNoon and was authored by Instancing
Table of Links
V. Conclusion, Acknowledgements, and References
\
III. METHOD
In our work, our objective is to construct a semantic map of the surrounding environment which also encompasses instance-level information and attribute information of objects. It is crucial to emphasize the inclusion of instance-level semantic information and object attributes in maps. This incorporation is vital for effectively processing linguistic commands commonly utilized in everyday language. In everyday life, robots commonly encounter commands like ”navigate to the fourth black chair across from the table”. Robots are required to identify ”which of the chair” both in terms of its sequence
\
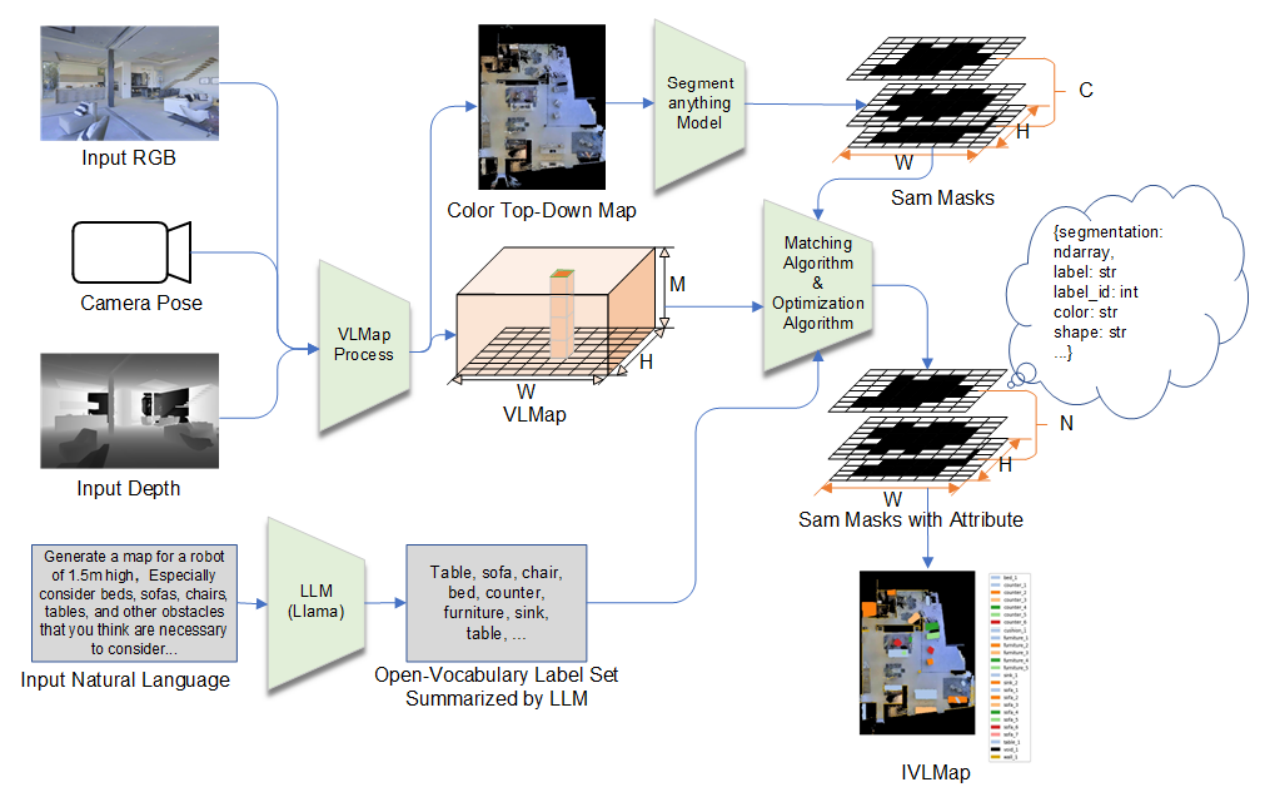
\ and attributes. Simultaneously, they are required to find ”where is the chair” by paying attention to the spatial relationship between the chair and the table. Our method is proposed based on VLMap [5]. In the following subsections, we describe (i) how to build IVLMap (Sec.III-A), (ii) how to use these maps to localize open-vocabulary landmarks (Sec.III-B), (iii) How to employ VLMaps in tandem with large language models (LLMs) to enable instance level object goal navigation using natural language commands (sec.III-C). Our pipeline is visualized in Fig.2.
\ A. IVLMap Creation
\

\ \ In order to get the 3D Reconstruction Map in Bird’s-Eye View, we, in line with the approach employed by VLMaps, obtain the corresponding coordinates of each pixel u in the RGB-D data frame within the grid map by formula
\
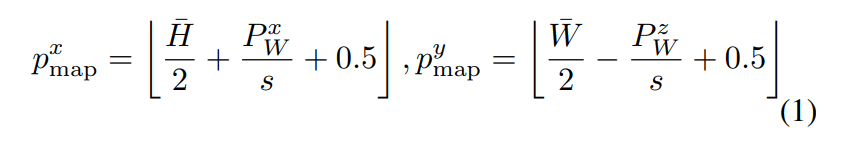
\

\

\

\

\

\
\

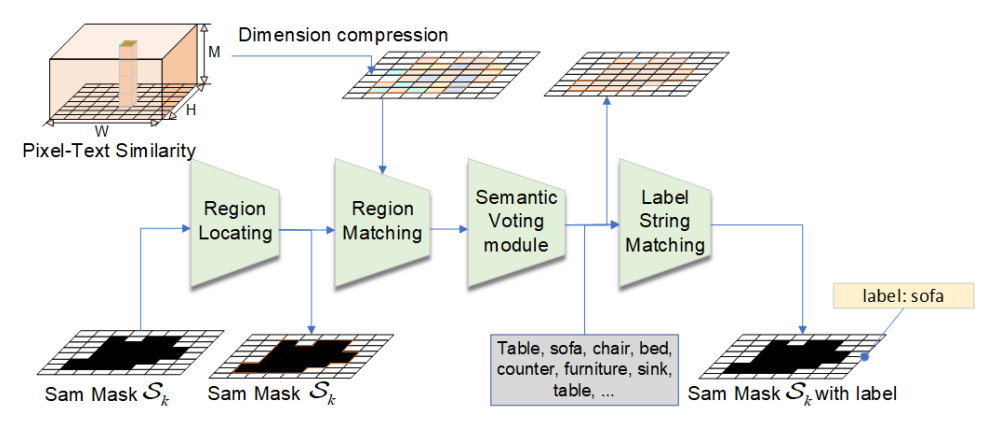
\ B. Localizing Open-Vocabulary Landmarks
\

\ C. Zero-Shot Instance Level Object Goal Navigation from Natural Language
\ In this chapter, we discuss the implementation of instance-level object goal navigation based on natural language, given a set of landmark descriptions specified by natural language instructions such as
\

\ There are numerous outstanding works in the field of zeroshot navigation, such as CoW [30], LM-Nav [4], VLMap [5]. Unlike their approaches, IVLMap enables navigation to instances of objects with specific attributes, such as ”the third chair on the left” or ”the nearest black sofa”. Particularly, we employ a large language model (LLM) to interpret the given natural language commands and decompose them into subgoals with attributes including object name, object instance information, object color [4], [5], [31], [32]. We have established a comprehensive set of advanced function libraries tailored for IVLMap. Building upon the understanding of natural language commands by the LLM, these libraries are invoked to generate executable Python robot code [25], [33]. Additional mathematical computations may be performed if required. Below are snippets showcasing some commands and the Python code generated by the model(input command in blue, output Python code in black), the full prompt can be referred to in Appendix B.
\ Additionally, numerous large language models have emerged recently. Apart from utilizing the ChatGPT API for navigation tasks, we also achieved similar results using opensource models. We employ Llama2 [29], an advanced opensource artificial intelligence model, to accomplish this task. We utilized the Llama-2-13b-chat-hf3 model from the Hugging Face repository. This model is fine-tuned for dialogue use cases and optimized for the Hugging Face Transformers format. To accelerate the model’s inference speed, we employed GPTQ [34], a one-shot weight quantization method based on approximate second-order information, to quantize the model from 8 bits to 4 bits. The experiments demonstrate an average improvement of around 30% in the inference speed after quantization.
\

\
:::info Authors:
(1) Jiacui Huang, Senior, IEEE;
(2) Hongtao Zhang, Senior, IEEE;
(3) Mingbo Zhao, Senior, IEEE;
(4) Wu Zhou, Senior, IEEE.
:::
:::info This paper is available on arxiv under CC by 4.0 Deed (Attribution 4.0 International) license.
:::
[1] The argmax operation in PyTorch returns the index of the maximum value along a specified axis in a tensor.
\ [2] The numpy unique method efficiently identifies and returns the unique elements of an array along with the count of occurrences for each unique element, preserving their original order.
\ [3] https://huggingface.co/meta-llama/Llama-2-13b-chat-hf
This content originally appeared on HackerNoon and was authored by Instancing
Instancing | Sciencx (2025-11-10T11:40:54+00:00) The Llama 2-IVLMap Combination Delivering Smarter Robot Control. Retrieved from https://www.scien.cx/2025/11/10/the-llama-2-ivlmap-combination-delivering-smarter-robot-control/
Please log in to upload a file.
There are no updates yet.
Click the Upload button above to add an update.