
This content originally appeared on DEV Community and was authored by Bamimore-Tomi
From exact search to in-exact search to phonetics, to change and edits in text, we use these algorithms on a daily basis. How about we explore how they really work?
We will be exploring one particular algorithm that was probably used by your device when you were searching for this post. You also use it every day when you text your family and friends. Sometimes, you blame it for mistakes in your spelling. Sit back and enjoy this ride.
The Levenshtein Distance.
This algorithm was designed in 1965 by a Russian Mathematician, Vladimir Levenshtein. It measures the minimum number of insertions, deletions, or replacements that are required to change one string to another. The higher the distance value, the greater the difference between the strings.
A simple example looks like this. The Levenshtein distance between the word “run” and “run” is 0 because both words are identical. No insertion, deletion, or replacement is needed. In contrast hand, the Levenshtein distance between the words “run” and “ran” is 1. We need one substitution to change the word “run” to “ran” i.e. “u” to “a”.
Implementation in Python
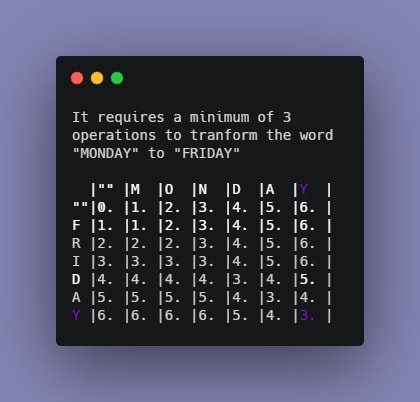
To check how many operations we need to transform the word MONDAY to FRIDAY, we will draw a dynamic programming table to visualize.
This is our initial table:
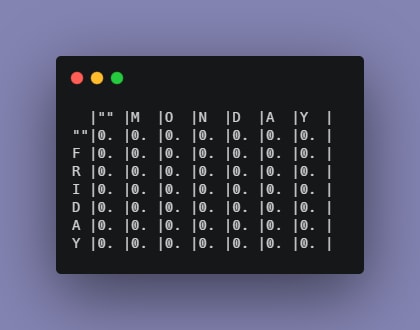
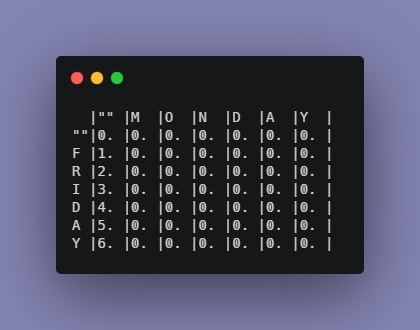
All values are currently initialized to zero. Notice some changes in the second column of the table.
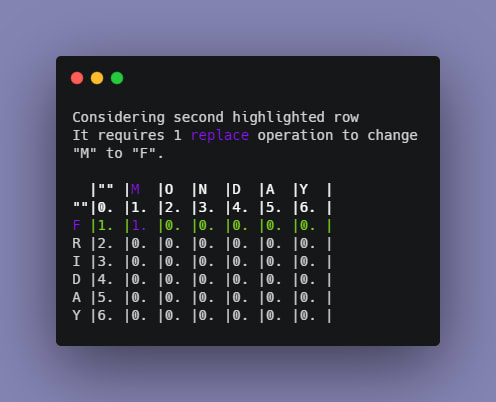
The reason for that will be explained using the second row because the same process occurs.
The next task is to start comparing substrings and calculate distances. To fill up the second row of the table, perform the following operations:

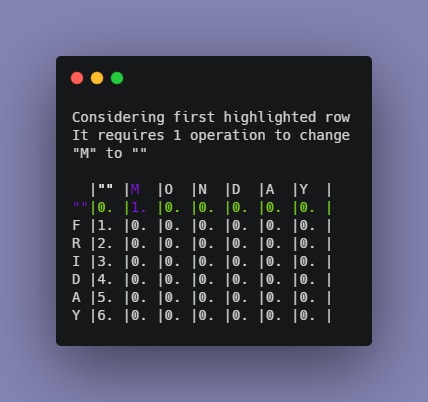
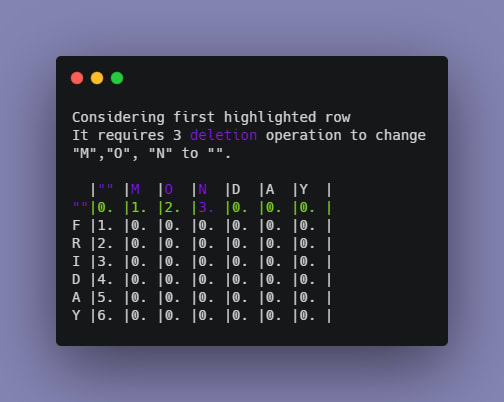
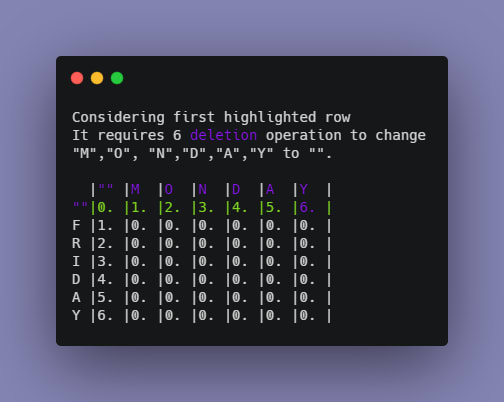
Notice the way the numbers and colors are changing for each element.
This key will be used as a reference when traversing the table.

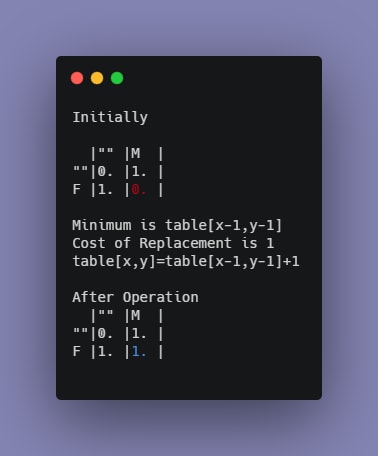
This means at any particular location table[x,y] where source[x]!=target[y], a replacement will cost table[x-1,y-1]+1, an insertion table[x,y-1]+1 and a deletion table[x-1,y] +1. The solution table[x,y] is the minumum of either of those values. When source[x]==target[y], table[x,y] will be min(table[x-1,y-1],table[x,y-1]+1,table[x-1,y] +1 ). The intuition behind previous statements will become clearer in the code and subsequent tables. See how to apply them in the table.
Intuition :
After all the iterations are completed, the global solution to the problem can be found at the bottom right coner of the table.
import numpy as np
def levenshtein(token_1,token_2):
len_token_1 =len(token_1) +1
len_token_2 = len(token_2) +1
matrix = np.zeros((len_token_1, len_token_2))
for i in range(len_token_1):
matrix[i,0] = i
for j in range(len_token_2):
matrix[0,j] = j
for x in range(1,len_token_1):
for y in range(1,len_token_2):
if token_1[x-1] == token_2[y-1]:
matrix [x,y] = min(
matrix[x-1,y-1],
matrix[x,y-1]+1,
matrix[x-1,y]+1
)
else:
matrix [x,y] = min(
matrix[x-1,y-1]+1,
matrix[x,y-1]+1,
matrix[x-1,y]+1
)
return matrix[len_token_1-1, len_token_2-1]
print(levenshtein("monday","friday"))
Time complexity : O(x*y)
Space complexity: O(x*y)
Dynamic programming helps us break big problems into smaller problems. There are other approaches to solving this problem. This algorithm can also be enhanced to give more information about the operation to be performed on either character.
If you have any questions, contact me @forthecode__. This can also help you understand better.
This content originally appeared on DEV Community and was authored by Bamimore-Tomi
Bamimore-Tomi | Sciencx (2021-04-26T01:26:19+00:00) Distance Measures: Levenshtein Distance. Retrieved from https://www.scien.cx/2021/04/26/distance-measures-levenshtein-distance/
Please log in to upload a file.
There are no updates yet.
Click the Upload button above to add an update.