
This content originally appeared on DEV Community and was authored by Saksham
We all know that JS is a single-threaded non-blocking asynchronous concurrent language.
But what does this actually mean?
Let’s find out:
Suppose we have a function that calls another function that calls one more function, such as:
function add(a,b) {
return a+b;
}
function callAdd(a,b) {
return add(a,b);
}
function finalFunc(a,b) {
const addDigits = callAdd(a,b)
console.log(addDigits);
}
finalFunc(3,4); // Output: 7
We all know that finalFunc will call callAdd, callAdd will call add, and add will return the sum of these two numbers and we will get 7.
But what’s happening behind the scenes?

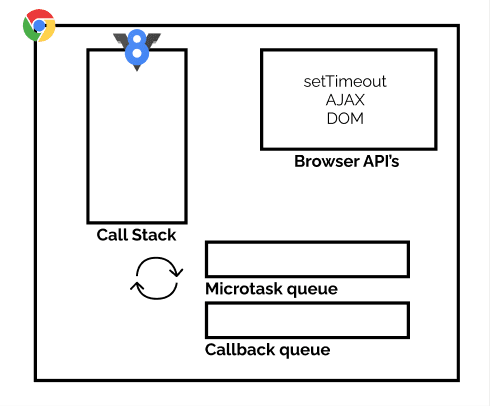
So, there is a thing called call stack in JavaScript which is a type of data structure that records basically where we are currently in our program.
It looks something like this:

And in here, this is how our program runs:
lets take a look at our code:
function add(a,b) {
return a+b;
}
function callAdd(a,b) {
return add(a,b);
}
function finalFunc(a,b) {
const addDigits = callAdd(a,b)
console.log(addDigits);
}
finalFunc(3,4); // Output: 7
Here when we called the finalFunc function, it was recorded in the call stack, and inside that we called another function which was then called and got recorded in the call stack again, which called the add function and it gets recorded as we can see in our diagram.
The return statement then gets executed and the function is removed from the call stack.
then the return statement of callAdd function gets executed and it gets removed from the stack and then the finalFunc then calls the console.log function and it gets executed and then the finalFunc is removed from the call stack and the program ends.

So this is how our program actually runs inside JavaScript.
Correction: The code in this video is a bit incorrect, the actual code is the one written above.
Waiting for Callbacks and SetTimeout
Let us assume that callbacks and setTimeout are synchronous and we call them in our program. Then what do you think will happen?
The call stack waits until the processing of the current is done. So, yes, the call stack will have to wait till the timeout ends. Till then we won't be able to do any task.
And suppose there is one callback that never returns. Then what?
Your code will be stuck forever. That’s why being asynchronous is important.
We did the normal function call in JS. But now let's try setTimeout in our program. FYI setTimeout and callbacks are not part of the JS engine. They are part of browser API.
And now setTimeouts are something that waits to perform a particular action. But as we said JavaScript is a non-blocking language. Then where does this waiting go?
So what happens behind the scenes, in the case of timeouts, is that when a timeout is called it is shifted to a special place called callback queue or task queue.
The role of the callback queue is to hold the timeouts when they are complete and send it to the call stack when it's empty.
But who checks if the call stack is empty or not?
This is where the event loop comes into play. The event loop keeps on checking if the queue and call stack are empty or not, if the task queue is not empty it checks if the call stack is empty or not, if the call stack is empty then it sends the timeouts to call stack one by one.
Something like this:
function add(a,b) {
return a+b;
}
let a = add(2,3);
console.log(a);
setTimeout(() => {
console.log("hello world");
}, 1000)
function callAdd() {
console.log("callAdd");
}
callAdd();
// Output:
//5
// callAdd
//hello world
This is how a browser looks and as we can see that JS engine is not the only thing that is present in the browser.
If we look at the above code, initially the call stack is empty, when the code starts running, first the console.log() function will come in the call stack and it will call the add function. The add function will execute and is removed from the stack, then console.log is executed and removed from the stack.
Next comes the settimeout, function that comes to the call stack but then it is moved to the browserAPI section and waits till the timer is up, and is moved to the task queue, till then callAdd function is called to the call stack, and is executed, then console.log function is called inside the call stack and is executed and removed and then callAdd function is removed.
And in between that the event loop keeps on checking if the call stack is empty or not, now as our call stack is empty, the event loop sends the setTimeout function from the task queue to the call stack which then calls the console.log() function which executes and removed from the call stack and finally setTimeout is removed from the stack and the program ends.
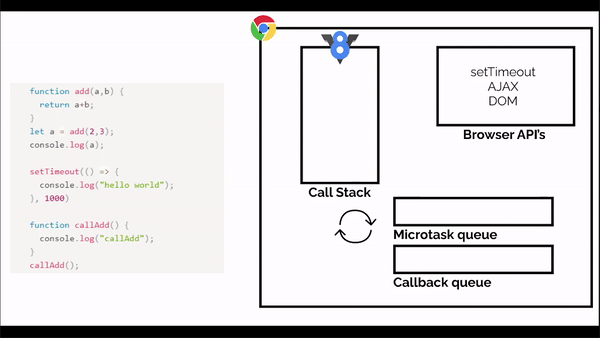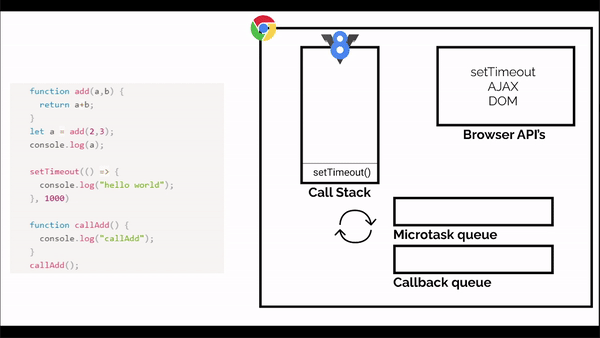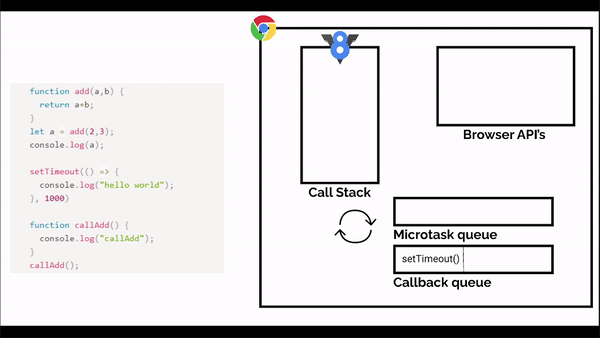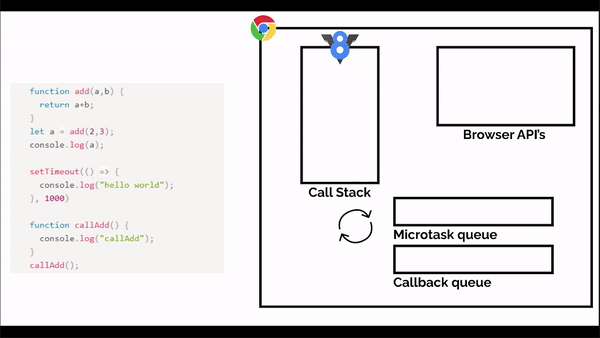
Now you must be wondering what this microtask queue is?
Well, it's exactly the same as a callback queue except that all the callbacks functions are stored here and the Microtask queue has a higher priority over the callback queue. which means that if there is anything inside the microtask queue it doesn't matter if the callback queue is full.
Until the microtask queue is not empty callback queue will not run.
If we made a callback function, then that is stored in the browser api till it gets resolved, it is then sent to the microtask queue and the event loop waits till the call stack is empty and then sends the callback function to the call stack and it executes.
So this was all about how async JS works. And yes, JS doesn’t like to wait so thanks to the event loop and the queues for the hard work.
This content originally appeared on DEV Community and was authored by Saksham
Saksham | Sciencx (2022-01-14T19:18:16+00:00) The story behind JS: how async works. Retrieved from https://www.scien.cx/2022/01/14/the-story-behind-js-how-async-works/
Please log in to upload a file.
There are no updates yet.
Click the Upload button above to add an update.