
This content originally appeared on Level Up Coding - Medium and was authored by Konstantin Maliuga
When a single service handles all updates, ensuring data consistency is relatively straightforward: updates happen in a well-defined order, and there’s no ambiguity about state. But as systems scale and processing is distributed across threads, services or entire regions, guaranteeing that every component agrees on “what happened, and in what order” becomes a much harder challenge.
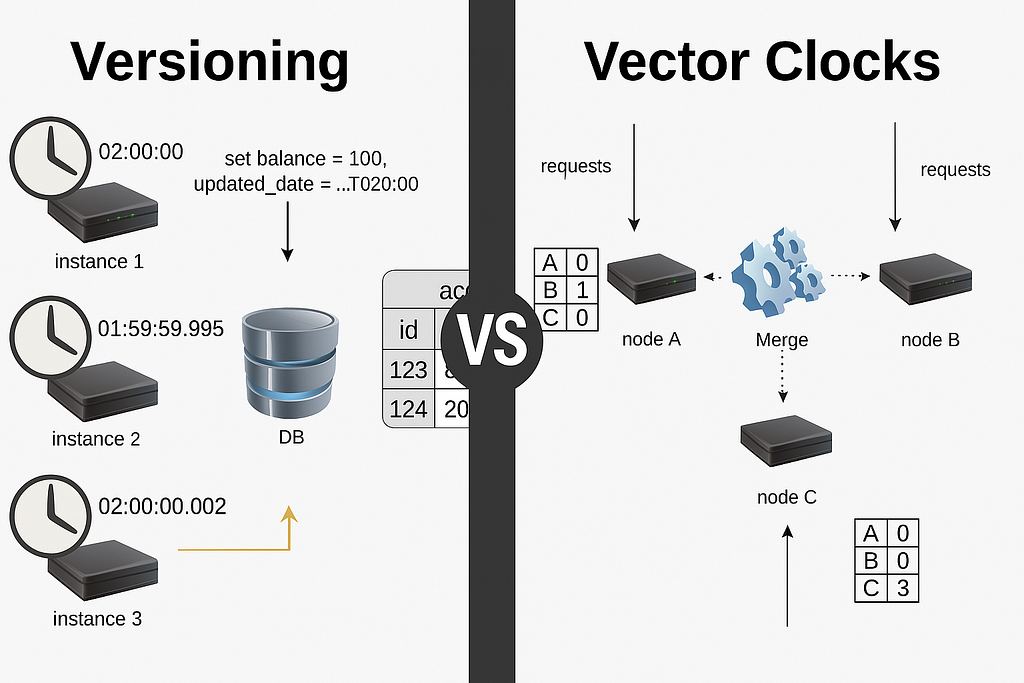
This is where tools like versioning and vector clocks come into play. Whilst both track changes over time, they serve very different roles in preserving consistency. Understanding their differences and applying them in the right context can help to scale systems without sacrificing correctness or reliability.
Versioning: A Simple Mechanism for Distributed Consistency
Versioning is about tracking changes. Whether it’s a document, a record, or a software component, versioning helps us know what changed, when, and what version we’re working with. It comes in several forms, each suited to different contexts:
- Monotonic numbers (e.g., version = 1, 2, 3...) are simple counters that increase with each update. They're widely used in databases and messaging systems to maintain order of operations.
- Timestamps (updated_at) are often used to record when something changed. They're easy to generate and useful for auditing and monitoring.
- Hashes (like Git commit SHAs) uniquely identify the content of a file or object based on its data. They’re commonly used in systems where integrity and immutability are important, like version control or distributed file systems.
- Semantic versioning (v1.2.3) is designed to convey the nature and impact of changes in a clear, predictable way—particularly important when managing dependencies between components or services.
Each of these versioning types plays a role in helping systems reason about change. Let’s see how some of them can be used for conflict detection or ordering in distributed environments.
There are two situations when versioning can help with parallel processing whilst maintaining consistency:
- Optimistic locking, when organising writes from multiple sources without losing concurrent updates,
- Event processing or projections, when reacting to changes or building a custom representation from them, to ensure all these changes are applied the correct order.
Optimistic locking
Imagine a system that updates account balances. There can be multiple application instances handling balance update requests that should be applied in a database (the database can actually be a set of shards that store a subset of accounts, but it’s not the point).
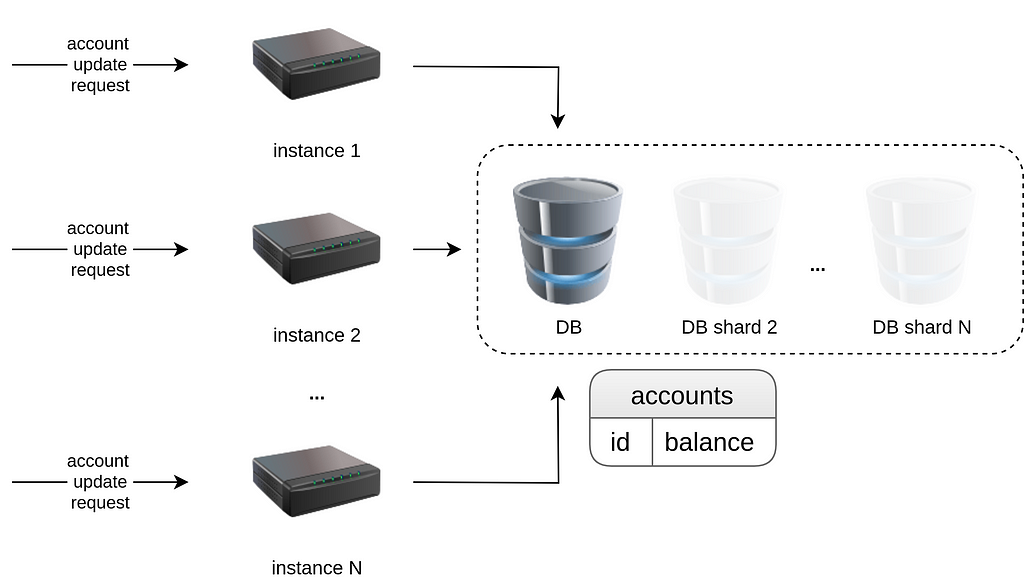
It’s a fairly scalable setup, but handling concurrent updates safely becomes crucial: what if balance updates to the same account are received in parallel on different nodes/threads. Then, if both requests are valid, one change should not overwrite the other. Otherwise, if only one of the changes can be applied (e.g. if having both operations would lead to overdraft) then one of the operations should fail consistently.
The traditional approach to preventing conflicting updates is pessimistic locking, which blocks the data until a transaction is finished:
BEGIN;
SELECT * FROM accounts WHERE id = 123 FOR UPDATE;
-- account 123 cannot be updated until the transaction is committed/rolled back- do verifications + calculations on the app side
UPDATE accounts SET balance = 100 WHERE id = 123;
COMMIT;
ℹ️ Before we continue, it’s worth noting that in the examples we directly set the account balance (balance = 100). Of course, in such cases deltas could be applied instead: incrementing or decrementing the balance by a certain amount. However, not all data models support additive updates, and direct assignment can be a useful abstraction for any state mutation where merge logic is non-trivial.
The row locking above guarantees that no other transaction can update the row until the current one is complete. It’s safe — but not cheap. Locks can lead to several issues that degrade performance:
- Overhead: The database must track and manage lock state, which increases CPU and memory usage, especially under high concurrency.
- Deadlocks: If two transactions each hold a lock and wait for the other’s resource, the system can deadlock, requiring a rollback of one transaction.
- Reduced parallelism granularity: While one transaction holds a lock, others are blocked (even if their operations could safely proceed) limiting system throughput and concurrency.
To avoid these performance penalties, many systems instead use optimistic locking. Rather than locking rows, the application checks that the data hasn’t changed since it was last read before attempting to write.
Let’s start with a common approach using timestamps.
One application instance reads the account first:
SELECT
balance, -- 0
updated_date -- '2024-01-01T12:00:00Z'
FROM accounts
WHERE id = 123;
It does some processing, then issues an update based on the updated_date it observed:
UPDATE accounts
SET
balance = 100,
updated_date = '2025-02-02T02:00:00Z' -- current time
WHERE id = 123 AND updated_date = '2024-01-01T01:00:00Z';
This will only apply if no one else changed the row in the meantime, because the WHERE clause ensures the update is executed only if the original updated_date matches, effectively acting as a lightweight consistency check without locking.
This mechanism can be extended across multiple operations in a single transaction. After each UPDATE, the application checks how many rows were affected. If all expected changes are applied successfully, the transaction can safely commit. But if even one update is skipped (due to a mismatch in the updated_date), the application can roll back the entire transaction to avoid leaving the system in a partial state.
BEGIN;
UPDATE accounts
SET balance = 100, updated_date = '2025-02-02T02:00:00Z'
WHERE id = 123 AND updated_date = '2024-01-01T01:00:00Z';
-- Check how many rows were updated. If 0, rollback
UPDATE transfers
SET status = 'COMPLETED', updated_date = '2025-02-02T02:00:00Z'
WHERE transaction_id = 'txn-789' AND updated_date = '2024-01-01T01:00:00Z';
-- Check how many rows were updated. If 0, rollback
COMMIT;
This approach tends to be efficient at scale, particularly when contention on individual records is low: a big number of accounts are being updated concurrently but independently. In such scenarios, optimistic locking ensures consistency without triggering frequent rollbacks or retries, because it’s rare for multiple processes to target the same record at the same time.
⚠️But here’s the catch when using timestamps for this approach. If the updated_date is set explicitly by the application (rather than relying on the database's NOW() or equivalent), then it can be affected by clock drift between instances. For example, if one instance's clock is slightly behind, it might set the new updated_date to a value that matches the current one in the database. Then, if another instance concurrently updates the row with a slightly more recent timestamp, it can silently override the earlier change.
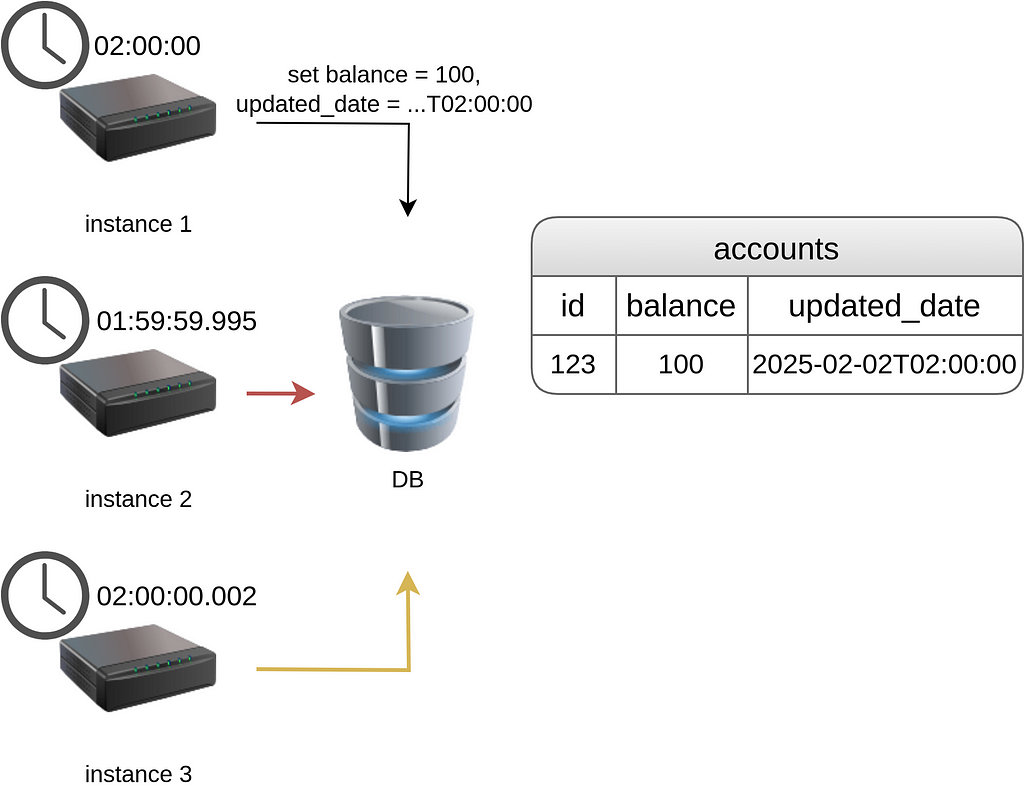
This kind of race condition leads to undetected data loss, as the timestamp no longer guarantees a clear “happened-before” relationship between changes.
To avoid this, either the database should be responsible for setting the timestamp (e.g., using NOW() or CURRENT_TIMESTAMP) to ensure consistency across updates, or systems should use a sequential version number:
UPDATE accounts
SET balance = 100, version = 6
WHERE id = 123 AND version = 5;
If someone else already updated the row and bumped the version to 6, the current update won’t apply. The system can re-fetch the latest state, reassess the logic, and retry with the new version.
Sequential versions avoid clock drift issues and make the intent explicit: every update must be based on the known previous state, and if anything changed in the meantime, new writes will always be rejected.
Event Processing and Projections
Versioning also helps when reacting to changes in different parts of a distributed system or building projections (read-optimised views built from write-focused data structures).
Let’s say we track accounts with assigned currencies: when a user opens an Account — the system needs to track which currencies are associated with the user. This can be useful for triggering notifications specific to currency holders.
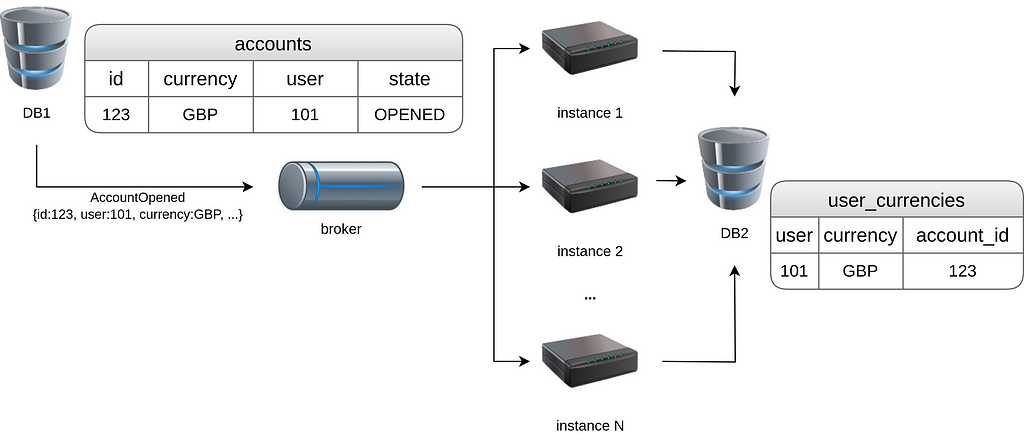
The projection building service might receive the following events: AccountOpened{user,currency} and AccountClosed{user,currency}.
To improve processing throughput, multiple application instances process these events in parallel, as events related to the same user or account are relatively rare. This processing parallelisation reduces latency for the updates queue and increases system scalability.
We’ll look at how the system might process a case when a user opened and closed an account in a short period of time, producing the following:
- AccountOpened{user:101,currency:GBP}
- AccountClosed{user:101,currency:GBP}
If there’s any delay in delivering the first event, this sequence can lead to a problem: the projection could incorrectly reflect that the account was closed when it was never opened. This leads to an invalid domain state.
To resolve this, we introduce a sequential version number in the event payload:
- AccountClosed{user:101,currency:GBP,version:3}
- AccountOpened{user:101,currency:GBP,version:3}
When the projection logic encounters the version: 3 event, it checks whether it is the next expected version to process, in this case version: 2. Since it recognises that the event has arrived out of order, it is postponed and requeued for future reprocessing.
Sequential version numbers are again preferred here in comparison with timestamps. Imagine you’re processing balance update events for an account, and each event carries a delta:
- BalanceUpdated{user:101,date:"00-01",amount:+£100}
- BalanceUpdated{user:101,date:"00-02",amount:+£50}
- BalanceUpdated{user:101,date:"00-03",amount:-£20}
If the third event arrives first and gets applied to an initial balance of £0, the projection might incorrectly show a balance of -£20, since all the other events from before will be rejected: there's just no reliable way to detect that two earlier updates are missing, because the timestamp doesn't indicate sequence.
In some cases, like simple view projections, it might be possible to include the final state directly in the event payload (such as the total balance after applying the update). That way, even if earlier deltas are missed, the projection can still be corrected to reflect the final known value: BalanceUpdated{user:101,date:"00:03",amount:-£20,total:130}.
However, if it’s essential to apply all intermediate steps as they were originally registered, missing events can’t simply be overwritten by the latest snapshot. Then using version number helps to immediately recognise that previous updates haven’t arrived yet. In the example above this enables the system to defer applying version 3 until the prior events are received and processed, preventing the projection from drifting into an invalid state.
Vector Clocks: Making Sense of Concurrent Updates
Versioning provides a great deal of help when there’s a single source of truth. One producer. One writer. What if updates come from multiple services e.g multiple regions? What if the sources are not even aware of each other?
In many distributed systems, multiple nodes can produce writes to the same data independently. And when they later sync up, the system needs to figure out what exactly happened.
Vector clocks are one of the tools that help systems reconcile independently generated changes across distributed nodes.
Here’s how it works:
Each node maintains a counter representing the number of updates it has performed. It also tracks what it knows about other nodes’ counters. Let’s look at a setup with three nodes:
- Node A: {A: 2, B: 0, C: 0} — it has made 2 updates and has seen none from B or C.
- Node B: {A: 0, B: 1, C: 0} — it has made 1 update and has seen none from A or C.
- Node C: {A: 0, B: 0, C: 3} — it has made 3 updates independently.
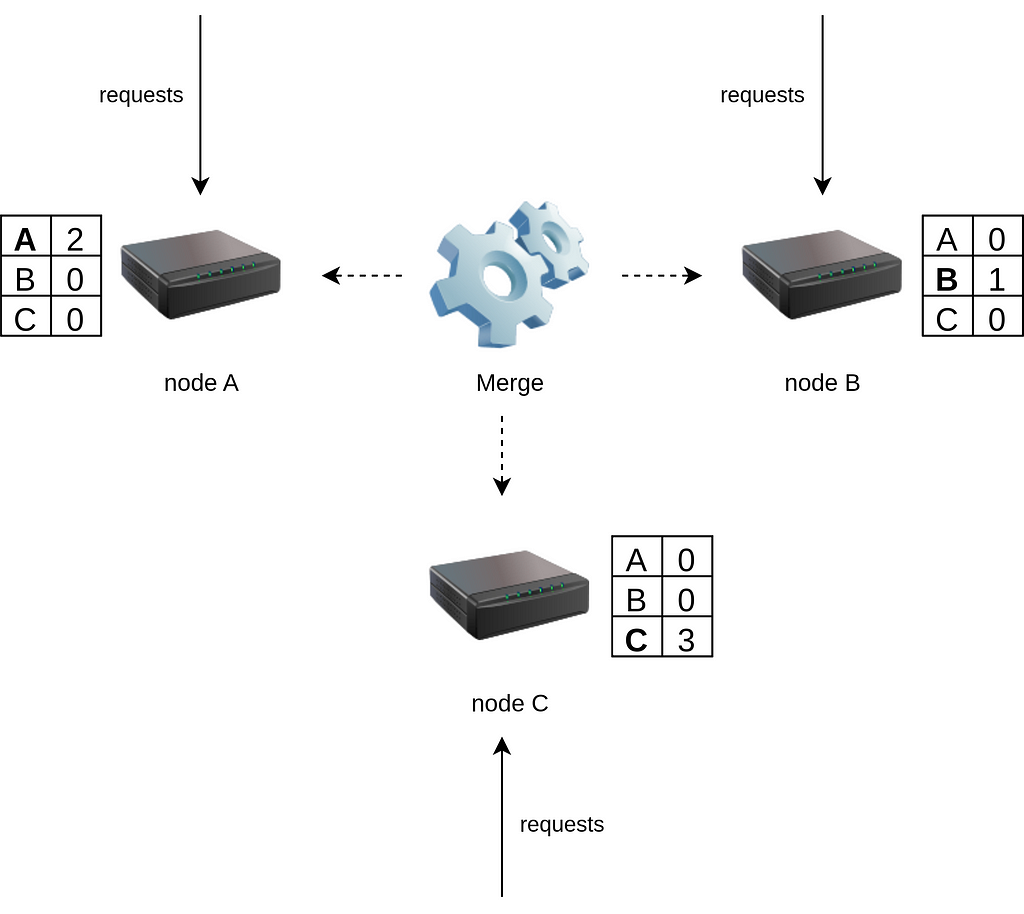
When these nodes synchronise, they compare their vector clocks with others and merge updates.
After synchronisation, all nodes will incorporate the updates from the others:
- Node A: {A: 2, B: 1, C: 3}
- Node B: {A: 2, B: 1, C: 3}
- Node C: {A: 2, B: 1, C: 3}
This reflects a fully synchronised state, where each node has applied all the updates performed across the cluster.
If updates happened concurrently on multiple nodes, the clocks will help determine whether nodes had seen each other’s changes at the time, and those changes are considered concurrent updates, for which conflict resolution strategies must be applied.
Balance reconciliation
Let’s take an example, looking at a system that processes balance updates from a third-party that we’ll call WISA. For simplicity it will be only two nodes (A&B) that process transactions involving WISA and both of those are initially synchronised with balance on WISA account equal to £1:
- Node A: {A: 2, B: 1}
- Node B: {A: 2, B: 1}

There are a few updates processed on these nodes at the same time:
- A processes +£2, then -£1. A’s clock: {A: 4, B: 1}. Balance = £2
- B processes +£4. B’s clock: {A: 2, B: 2}. Balance = £5
When they sync, both apply each other’s updates: A applies update 2(+£4) from B, and B applies updates 3(+£2) and 4(-£1) from A. The final balance becomes synchronised on each node: £6, and clock become synchronised on each node: {A: 4, B: 2}. If a new node C is added to the system then either A or B would exchange their vector clock with it, allowing C to quickly catch up to the consistent state of the cluster.
The vector clocks for WISA might also change on other operations, such as communication log with the third party, a number of corrections etc. In all these cases conflicts resolution works failry straightforward, since these changes are still mergeable. Vector clocks help detect when updates conflict, allowing the system to apply the appropriate resolution strategy.
If it is not possible to simply merge data, vector clocks conflicts can be solved with alternative strategies:
- Last Write Wins, which should be considered if updates loss is acceptable.
- Domain-specific logic, such as preferring updates with a higher priority, monetary value, or based on contextual business rules.
- Manual resolution, where both versions are returned and the application or user chooses the correct one.
Ultimately, vector clocks surface the conflict, but your domain defines how to resolve it.
The Takeaway
Versioning and vector clocks are both essential tools in distributed systems, but they serve different purposes:
- Versioning is ideal when changes originate from a single source. It provides a simple, effective way to ensure reliable concurrency control and maintain ordered event processing for things like projections and reactions.
- Vector clocks can be helpful when multiple nodes can generate updates independently. They help detect concurrency and offer a way to reconcile divergent states across distributed actors.
Used appropriately, both tools can help systems scale while preserving data consistency, even in highly concurrent, distributed environments.
How to Keep Distributed Systems Consistent: Versioning vs Vector Clocks was originally published in Level Up Coding on Medium, where people are continuing the conversation by highlighting and responding to this story.
This content originally appeared on Level Up Coding - Medium and was authored by Konstantin Maliuga
Konstantin Maliuga | Sciencx (2025-04-14T00:34:30+00:00) How to Keep Distributed Systems Consistent: Versioning vs Vector Clocks. Retrieved from https://www.scien.cx/2025/04/14/how-to-keep-distributed-systems-consistent-versioning-vs-vector-clocks/
Please log in to upload a file.
There are no updates yet.
Click the Upload button above to add an update.