
This content originally appeared on Level Up Coding - Medium and was authored by Gedeón Domínguez Torán
A Playbook for Modernising Classic Utility Technology Stacks
A fictional but realistic scenario for a regulated utility that sells “Flux” refills for high‑capacity temporal temporal condensers installed in cars and cross‑epoch trains.

1. Business Context
Flux Corp is a pan‑European utility that delivers Flux — an exotic, highly‑regulated energy product used to recharge flux capacitors that propel our time‑travel cars and chrono‑locomotives. Revenue comes from two channels:
- Subscription plans (monthly quota of Flux credits, billed in advance).
- On‑demand top‑ups (pay‑as‑you‑go refills when quota is exhausted mid‑cycle).
Key drivers for the next two years:
- 🏁 Customer experience parity with digital‑native competitors.
- 📈 Hyper‑growth in IoT‑connected temporal condensers (10× more telemetry events expected by 2026).
- 🛡️ Regulatory audits under the EU’s Energy Digital Services Act (EDSA) requiring 7‑year retention of billing evidence and end‑to‑end traceability of adjustments.
2. Core Systems (“The Three Pillars”)

3. Legacy Integration Landscape (“Brownfield”)
The architecture grew organically over a decade, with each team optimising locally. The result is a spaghetti topology that looks lightweight on paper but collapses under load and change pressure.
3.1 Example — Top‑Up Execution Path
Mobile App
↓ HTTPS JSON
API Gateway (GraphQL)
↓ REST
Node.js BFF “BillingProxy”
↓ gRPC
Legacy Integration Gateway (Java 7, on Tomcat)
↓ JMS
RabbitMQ Cluster (single‑AZ)
↓ IDoc
SAP PI/PO (RFC → ABAP batch)
↓ Flat file on NFS share
C# Windows Service (nightly)
↓ SFTP
Custom Billing Engine (PowerBuilder)
Single top‑up touches 8 hops, crosses 5 protocols, and finishes T+45 min in the happy path. Error handling fans out into shadow tables with no correlation IDs, making incident debugging a forensic exercise.
3.2 Integration Anti‑Patterns Observed

4. Pain Points & Drivers for Change
- Data inconsistency to customer: The balance, consumption and invoice information displayed in the mobile app is frequently stale or inaccurate when compared with the authoritative records in Salesforce and SAP.
- Invisible top‑ups: Neither the customer nor the operations team can reliably determine whether a submitted top‑up request has been executed, partially executed, or silently failed.
- Scalability ceiling: Peak‑day top‑ups (end of fiscal quarter) saturate RabbitMQ and force capacity freezes.
- Change lead‑time: A one‑field change in subscription pricing takes ≈ 10 weeks from dev to prod because it triggers regression across ≥ 7 systems.
- Debugging cost: MTTR > 6 h; engineers manually stitch logs across ELK, SAP CCMS, Salesforce Shield.
- Compliance risk: No verifiable, immutable audit log that spans CRM ↔ Billing ↔ Payments.
Outcome required by the board: “90‑95‑90” by the board: “90‑95‑90”
- 90th percentile top‑up latency < 5 s.
- 95 % of incidents resolved within 30 min.
- 90 % reduction in integration maintenance OPEX within 18 months.
Next step: design a lightweight, traceable, domain‑aligned reference architecture that fulfils the 90‑95‑90 mandate while keeping regulatory auditors happy.
5. Technical North Star
The board has hired a dream team of architecture heavyweights — Samuel Neumann, Erik Evanston, and Martyn Fowler — to reset the engineering vision. Their first deliverable is a concise set of objectives that map technology choices to business outcomes:
- No unnecessary complexity — embrace the simplest design that can meet compliance and scale goals; postpone exotic patterns until the pain is proven.
- Explicit ownership boundaries — draw crisp limits around the four macro‑teams: SAP Core, Mobile App & BFF, Salesforce CRM, and Integration Platform.
- Observability as backbone — traces, metrics, and logs converge into a single Process Telemetry Plane. Every user‑initiated flow (e.g., Top‑Up, Change‑Plan, Pay‑Invoice) carries a process_id that becomes the primary join key for SLA dashboards and audits.
- Process‑centric view — the business process is the unit of value; systems expose start/end events, state transitions, and error codes so both tech & business can reason about flows, not tables.
- Minimise coordination tax — default to asynchronous contracts, semver‑controlled event schemas, and platform‑managed deploy pipelines so that a change in one domain rarely blocks another.
- Continuous compliance — embed immutability (append‑only logs), idempotent commands, and compensating actions into the design; auditors can replay any transaction for seven years without special exports.
These principles will guide the upcoming target architecture and migration roadmap.
6. Domain‑Driven Integration Scenarios
Below are three pragmatic patterns, each mapping the entities and processes described earlier to DDD integration relationships (Upstream/Downstream, Customer‑Supplier, Conformist, Shared Kernel, ACL). All keep Process Telemetry as a cross‑cutting backbone.
6.1 Scenario A — CRM Upstream, SAP Downstream

Pros: minimal new domains; leverages existing data gravity. Cons: tight coupling — any CRM outage stops subscriptions.
▶ Top‑Up Flow (Scenario A)

6.2 Scenario B — Subscription Core Domain
Create an independent Subscription Service that owns Quota, Balance, and Top‑Up logic.

Pros: isolates fast‑changing quota logic; decouples SAP downtime from top‑up. Cons: introduces a new data source of truth; migration complexity.
▶ Top‑Up Flow (Scenario B)

6.3 Scenario C — Process Orchestrator Domain
Fuse orchestration logic into a dedicated Flux Process Manager (camunda, Temporal.io) that runs sagas for Top‑Up, Plan Change, Payment.
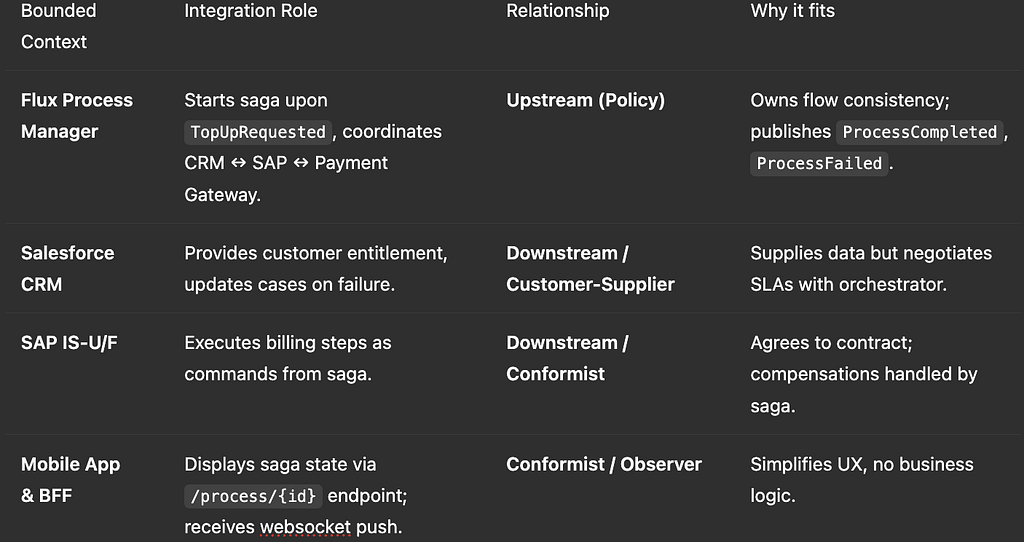
Pros: central view of process; easier observability & SLAs. Cons: single point of orchestration can become bottleneck; heavier runtime.
▶ Top‑Up Flow (Scenario C)

Process Ownership & Coordination Patterns

Observation: Process ownership clarity increases from A → C, while day‑to‑day meeting load tends to decrease — at the cost of a more sophisticated orchestrator platform in C.
Choosing a Scenario

Start with a brown‑field friendly option (A) for quick wins, or invest in (B) if balance logic is the growth hotspot. Choose © if auditability and complex multi‑step flows dominate.
7. Architects’ Recommendation
After a joint workshop, Samuel Neumann, Erik Evanston, and Martyn Fowler converge on a two‑stage strategy:
- Stabilise → Scenario A (0‑6 months)
- Replace the legacy Integration Gateway with a managed Event Mesh to cut rabbit‑MQ bottlenecks.
- Add uniform OpenTelemetry ingestion across CRM, SAP PI/PO, and the BFF.
- Outcome: latency P90 < 15 s, correlated traces for audit, no database sharing.
- Evolve → Scenario B (6‑18 months)
- Carve out a Subscription Service as the Core Domain for quota & balance.
- Decompose SAP quota logic via strangler events; SAP becomes pure ledger.
- Gradually switch Mobile App to hit /top‑ups directly, retiring the GraphQL façade.
Why not jump straight to Scenario C?
- “Avoid over‑engineering” — a temporal orchestrator adds operational weight (DB, workers, DSL) before the team has solid event discipline.
- Process observability goal is met in Scenario B thanks to process‑ID‑carrying events and a single balance source.
- Coordination tax remains acceptable: one dedicated Subscription squad can iterate fast; BPMN governance councils are deferred.
Success Criteria the trio will track

Neumann’s microservices pragmatism, Evanston’s domain focus, and Fowler’s pattern minimalism all align behind Scenario B as the end‑state, preceded by a controlled stabilisation phase using Scenario A as the stepping stone.
8. Eventual‑Consistency UX Strategies
Even with the future Subscription Service in place, absolute real‑time consistency across Mobile App, Salesforce, and SAP is unattainable. The architects therefore frame two complementary strategies that the product team can adopt.
8.1 Strategy α — Optimistic UX
“Everything works unless we discover otherwise.”

8.2 Strategy β — Progressive Consistency UX
“Explicitly communicate pending states to the user.”

8.3 Common Backend Building Blocks
- Outbox & Inbox patterns — Guarantee at‑least‑once event propagation without duplicate side‑effects.
- CQRS Read Models — Materialise balance and invoice view optimised for mobile queries; refresh idempotently from event stream.
- Process Telemetry Plane — All events carry process_id, customer_id, ttl_ms, and source_system. Dashboards correlate front‑end latency with backend lag.
- Compensating Actions Library — Standardise rollback semantics (e.g., UndoQuotaDebit) so UX can map failures to user‑friendly messages.
8.4 Decision Matrix
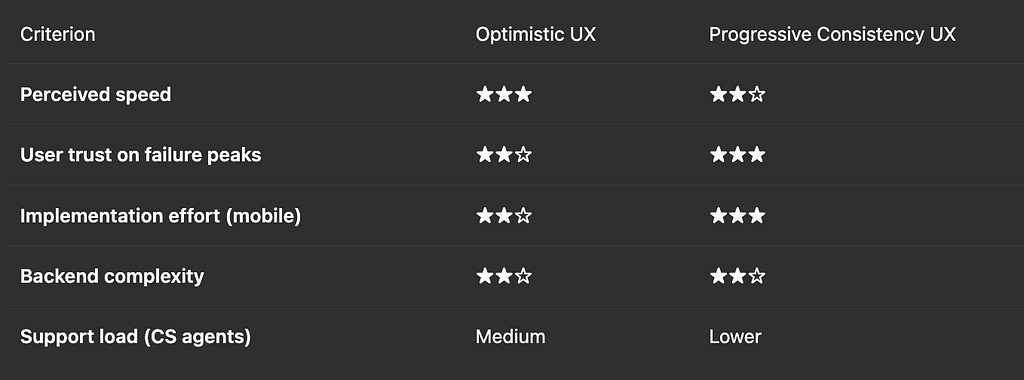
Recommendation: Start with Progressive Consistency UX for Top‑Up and Payment flows where money is at stake, and adopt Optimistic UX for low‑risk interactions (profile changes, chat, preference updates). Instrument both with the same process_id contract to allow A/B comparison.
9. Durably Accepting Top‑Ups During Core Outages
CEO mandate: “A customer’s top‑up must never vanish — even if Salesforce, SAP, or the Subscription Service are offline for hours.”
9.1 Challenge Restated
- No data loss: Once the mobile app sends the request, the company owns it.
- Graceful degradation: Customers should be able to issue top‑ups while back‑end systems are down, and see a clear status.
- Automatic replay: When systems recover, stored commands must be processed exactly once in the original order.
9.2 Architectural Response

9.3 End‑to‑End Flow (Outage Scenario)
1 Mobile App POST /top-ups (idempotency_key=abc)
2 API Gateway ⇢ Persist to DCS (state=queued, process_id=123)
3 API Gateway ⇢ 202 Accepted + process_id=123 (UI shows "Queued")
4 Subscription Service ⇠ (offline) <-- Replay Worker waits...
5 Core Systems recover (SAP/SF online)
6 Replay Worker ⇢ Deliver command to Subscription Service
7 Subscription Service ⇢ Debit balance, emit BalanceDebited
8 Mobile App ⇠ Websocket push "Confirmed"
9.4 UX Impact

9.5 Failure Handling & Back‑Pressure
- Long outage (> threshold) → Auto‑switch mobile app to Maintenance banner; new commands still queued.
- Replay backlog > N commands → Throttle mobile intake (HTTP 429) and show expected wait time.
- Poison message → Move to dead_letter topic, alert SRE, surface Failed in UX with process_id for support.
9.6 Trade‑Offs

Decision: Implement Edge Outbox + Replay Worker now; upgrade to Full Command Sourcing only if TPS > 2 k/s or regulatory auditors demand immutable raw logs beyond 90 days.
10. Reducing Salesforce API & Event Footprint
A late volumetric review shows that our initial forecast for Salesforce API calls (REST/Composite) and Platform Events was understated by ≈ 4×, threatening cost overruns. Salesforce remains the source of truth for customer and entitlement data, but we must slash traffic while preserving data freshness for the Mobile App.
10.1 Guiding Constraints
- No silent data drift: The information displayed to the customer must either be fresh or explicitly marked as “Syncing”.
- Keep write path intact: Contract‑critical updates (e.g. lead conversion, case creation) still land in Salesforce first.
- Minimise incremental complexity: Re‑use existing building blocks (Event Mesh, Outbox) where possible.
10.2 Strategy ☘ — Read‑Optimised Projections
Pros: Immediate traffic drop, leverages existing Event Mesh, minimal schema work. Cons: Added operational surface (read DB), eventual consistency lag (seconds to minutes).
10.3 Strategy ⚡ — Write‑Behind Cache

Pros: Converts many small API writes into batched ones, cheap in API quota. Cons: Slight delay before user sees change reflected (seconds‑tens); conflict resolution needed.
10.4 Strategy 🥑 — Edge ETag & TTL (Quick Win)

10.5 Comparative View

10.6 Recommendation of the Architects
- Short‑term (≤ 4 weeks): Deploy Edge ETag & TTL to shave low‑hanging fruit and stay within current budget envelope.
- Mid‑term (≤ 3 months): Implement Read‑Optimised Projections for high‑traffic mobile reads (balance, last invoices, entitlements). Target 80 % fewer GET calls.
- Long‑term (optional): Add Write‑Behind Cache if write traffic grows beyond threshold or user‑initiated updates become quota‑heavy.
All strategies integrate cleanly with the existing Durable Command Store and Process Telemetry Plane: each projection or batch write re‑uses the same process_id, ensuring trace continuity.
Concise “North-Star” Architecture
Flux Corp’s end-state is a domain-aligned, event-driven platform centred on a single Subscription Core Domain that owns quota, balance and top-up logic. Integration is through a cloud Event Mesh; SAP is reduced to an immutable ledger, Salesforce to customer authority, and the mobile BFF becomes a thin façade. All services emit OpenTelemetry spans with a shared process_id key so operations, audit and business analytics converge on the same trace. Edge durability is guaranteed by an Outbox + Replay Worker, allowing top-ups to queue safely during core outages. In short:
“A lean, event-centric architecture where ownership is explicit, commands are durable, and every flow is observable by design.”
Reflecting on Decisions of This Magnitude

Closing Thought
Architectures at this scale are never “finished.” The article’s strength lies in making the trade-offs explicit — cost vs latency, simplicity vs future optionality — and tying every technical move to a measurable business outcome (“90–95–90”). Keep that habit. When the context changes (regulation, traffic, org chart), the architecture should evolve just enough — no more, no less.
Broader Decision-Making Heuristics
- Risk-Adjusted YAGNI
Use Architecture Fitness Functions (Bass et al.) to track latency, MTTR and OPEX weekly. When a KPI drifts, re-evaluate whether “temporal orchestrator” or “event sourcing” has crossed the pain-is-proven threshold. - Cognitive Load Budgets
Rely on Team Cognitive Load metrics (Skelton & Pais). A Core Domain that looks elegant on a whiteboard can overload a single squad once edge-case logic and compliance rules pile up. - Trade-off Records Over Slides
Capture every pivotal choice in a two-page ADR: context → decision → consequences. Revisiting the rationale avoids “architectural archaeology” when leadership changes. - Socio-Technical Symmetry
Conway’s and Inverse Conway’s: the moment SAP integrators and mobile engineers sit in separate cost centres, any “shared kernel” promise weakens. Budget for interface friction. - Scenario-Based Stress Tests
Before committing to Scenario B, run a Game Day with a simulated SAP outage and 10× telemetry spike. Observe how the Durable Command Store, Event Mesh and process_id tracing behave under real pressure.
Case Study: Modernising the Flux Utility Platform was originally published in Level Up Coding on Medium, where people are continuing the conversation by highlighting and responding to this story.
This content originally appeared on Level Up Coding - Medium and was authored by Gedeón Domínguez Torán
Gedeón Domínguez Torán | Sciencx (2025-06-16T01:19:41+00:00) Case Study: Modernising the Flux Utility Platform. Retrieved from https://www.scien.cx/2025/06/16/case-study-modernising-the-flux-utility-platform/
Please log in to upload a file.
There are no updates yet.
Click the Upload button above to add an update.