
This content originally appeared on HackerNoon and was authored by Instancing
Table of Links
5 Experiments
Datasets: We conduct our experiments using the ScanNet200 [38] and Replica [40] datasets. Our analysis on ScanNet200 is based on its validation set, comprising 312 scenes. For the 3D instance segmentation task, we utilize the 200 predefined categories from the ScanNet200 annotations. ScanNet200 labels are categorized into three subsets—head (66 categories), common (68 categories), and tail (66 categories)—based on the frequency of labeled points in the training set. This categorization allows us to evaluate our method’s performance across the long-tail distribution, underscoring ScanNet200 as a suitable evaluation dataset. Additionally, to assess the generalizability of our approach, we conduct experiments on the Replica dataset, which has 48 categories. For the metrics, we follow the evaluation methodology in ScanNet [9] and report the average precision (AP) at two mask overlap thresholds: 50% and 25%, as well as the average across the overlap range of [0.5:0.95:0.05].
\ Implementation details: We use RGB-depth pairs from the ScanNet200 and Replica datasets, processing every 10th frame for ScanNet200 and all frames for Replica, maintaining the same settings as OpenMask3D for fair comparison. To create LG label maps, we use the YOLO-World [7] extra-large model for its real-time capability and high zero-shot performance. We use Mask3D [39] with non-maximum suppression to filter proposals similar to Open3DIS [34], and avoid DBSCAN [11] to prevent inference slowdowns. We use a single NVIDIA A100 40GB GPU for all experiments.
\
5.1 Results analysis
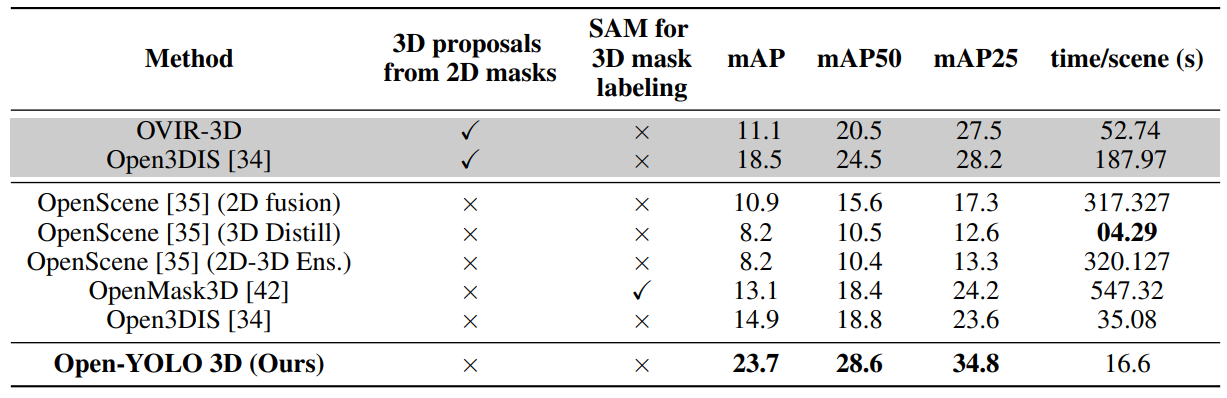
Open-Vocabulary 3D instance segmentation on ScanNet200: We compare our method’s performance against other approaches on the ScanNet200 dataset in Table 1. We indicate whether each
\
\

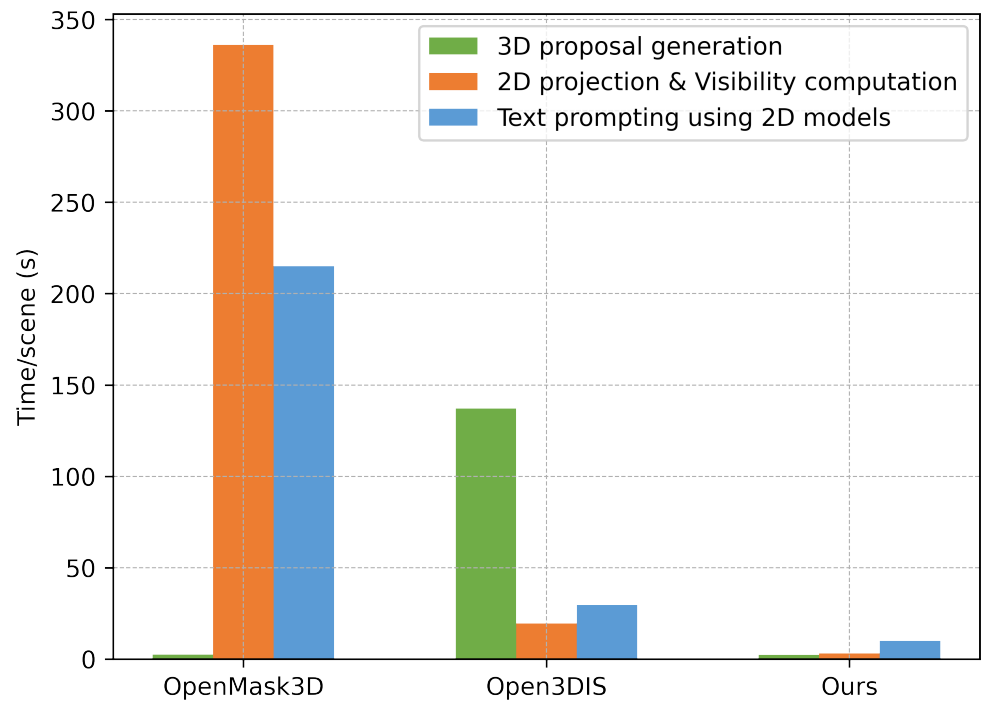
\ method uses 2D instances to generate 3D proposals and whether SAM is used for labeling the 3D masks. Our method achieves state-of-the-art performance with proposals from only a 3D instance segmentation network compared to methods from two settings (i) 3D mask proposals from only a 3D instance segmentation network (ii) using a combination of 3D mask proposals from a 3D network and 2D instances from a 2D segmentation model. Additionally, our method is ∼ 16× faster compared to state-of-the-art Open3DIS.
\ Generalizability test: To test the generalizability of our method, we use the 3D proposal network pre-trained on the ScanNet200 training set and evaluate on the Replica dataset; the results are shown in Table 2. Our method shows competitive performance with ∼ 11 × speedup against state-of-the-art models [34], which use CLIP features.
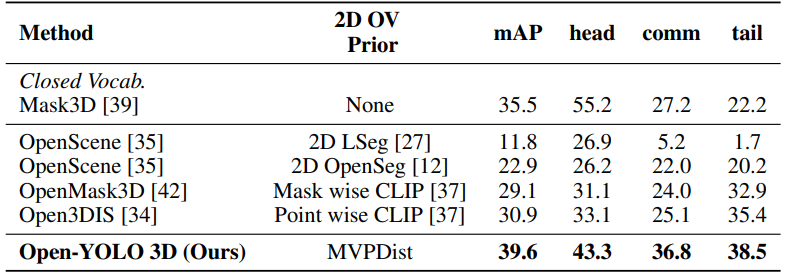
\ Performance with given 3D masks: We further test our method for 3D proposal prompting from text against existing methods in the literature in the case of ground truth 3D masks and report the results in Table 5. For Mask3D, oracle masks are assigned class predictions from matched predicted masks using Hungarian matching. For open-vocabulary methods, we use ground-truth masks as input proposals. We show the results in Table 5 that MVPDist can outperform CLIP-based approaches in retrieving the correct 3D proposal masks from text prompts, due to the high zero-shot performance achieved by state-of-the-art open-vocabulary 2D object detectors.
\
\
\

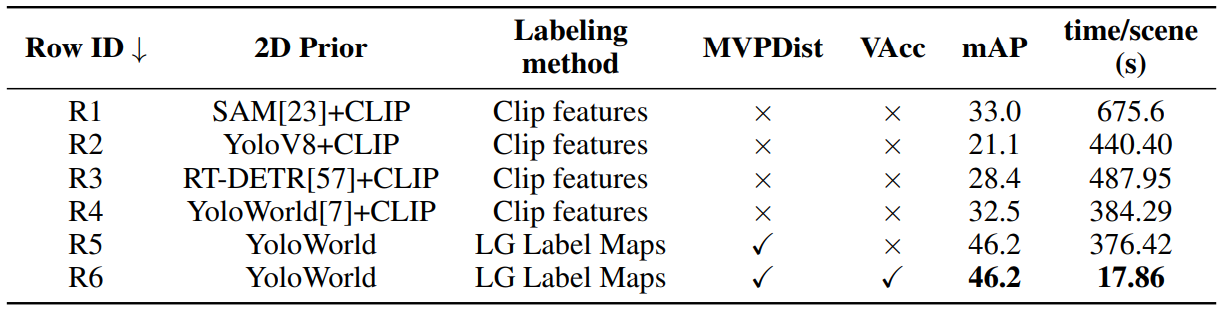
\ Ablation over Replica dataset: To test the ability of object detectors to replace SAM for generating crops for 3D CLIP feature aggregation, we conduct three experiments with different object detectors on the Replica dataset, using ground truth 3D mask proposals to compare our method’s labeling ability against others. The results are in Table 3, rows R2 to R4, with row R1 showing OpenMask3D [42] base code results. We generate class-agnostic bounding boxes with an object detector, then assign the highest IoU bounding box to each 3D instance as a crop, selecting the most visible views. For 3D CLIP feature aggregation, we follow OpenMask3D’s approach, aggregating features from multiple levels and views. These experiments show that YOLO-World can generate crops nearly as good as SAM but with significant speed improvements. Row R5 demonstrates YOLO-World’s better zero-shot performance using our proposed Multi-View Prompt Distribution with LG label maps. Row R6 shows speed improvements using the GPU for 3D mask visibility computation.
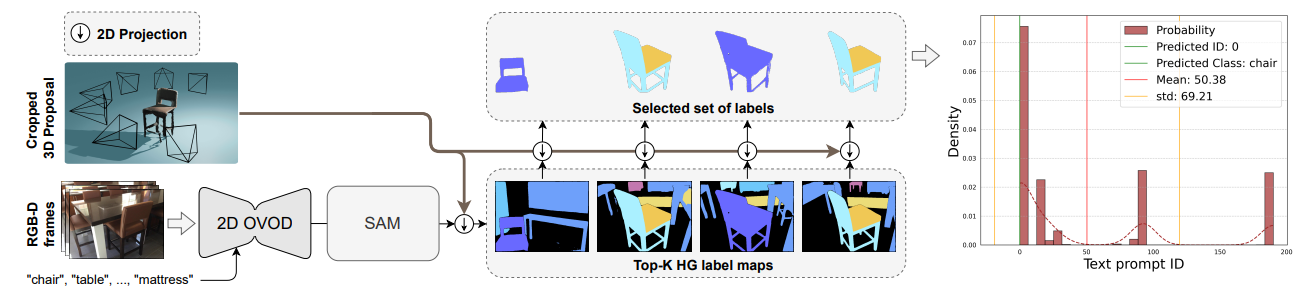
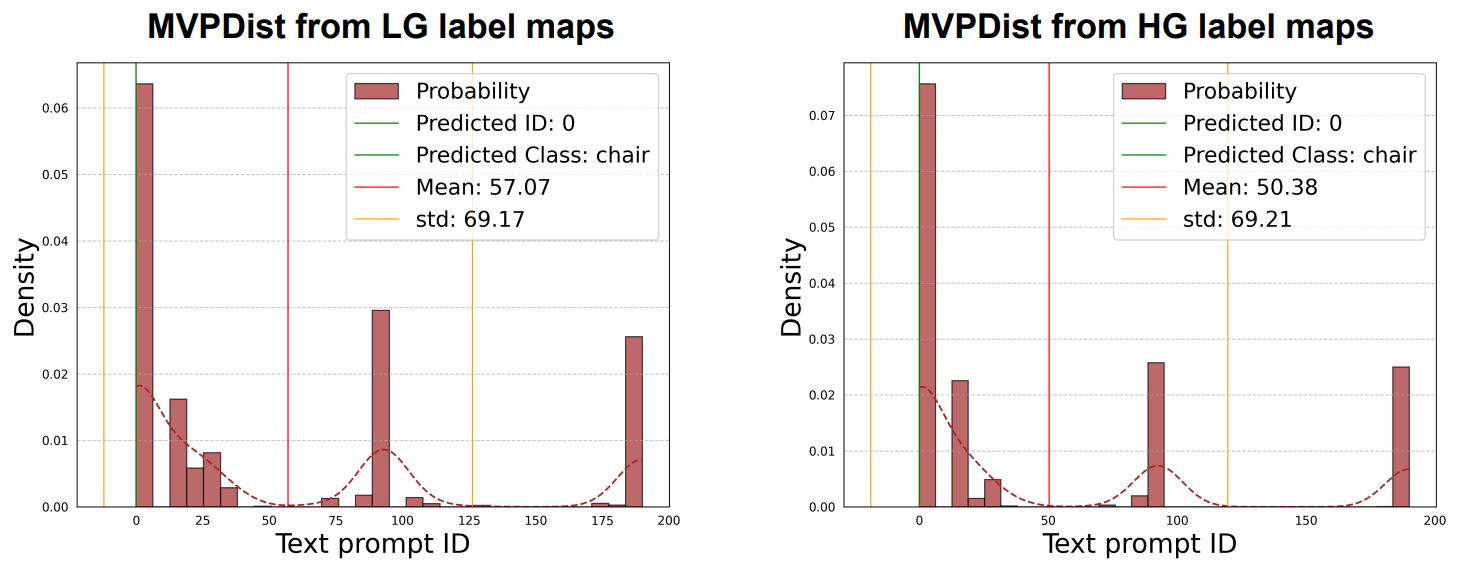
\ Top K analysis: We show in Table 4 that naively using YOLO-World with only one label-map with the highest visibility per 3D mask proposal results in sub-optimal results and using top-K label-maps can result in better predictions as the distribution can provide better estimate across multiple frames, since YOLO-World is also expected to make misclassifications in some views while generating correct ones in others. This approach assumes that YOLO-World makes a correct class prediction for the same 3D object in multiple views for it to be effective.
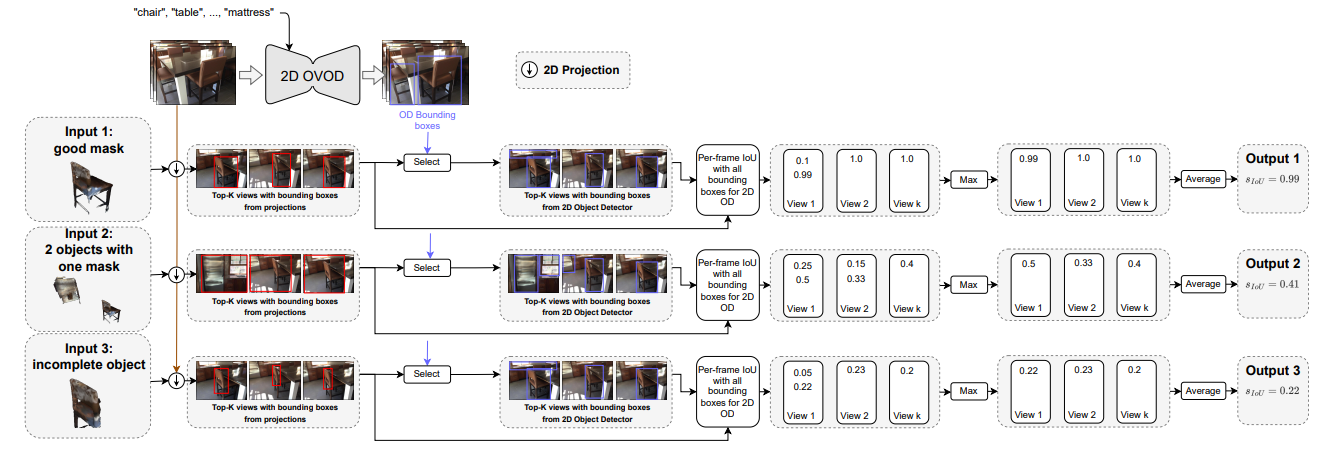
\ High-Granularity (HG) vs. Low-Granularity (LG): Table 4 shows that using SAM to generate HG label maps slightly reduces mAP, and slows down the inference by ∼ 5 times. This is due to the nature of projected 3D instances into 2D, where the projection already holds 2D instance information as shown in Figure 3, and SAM would just result in redundancy in the prediction.
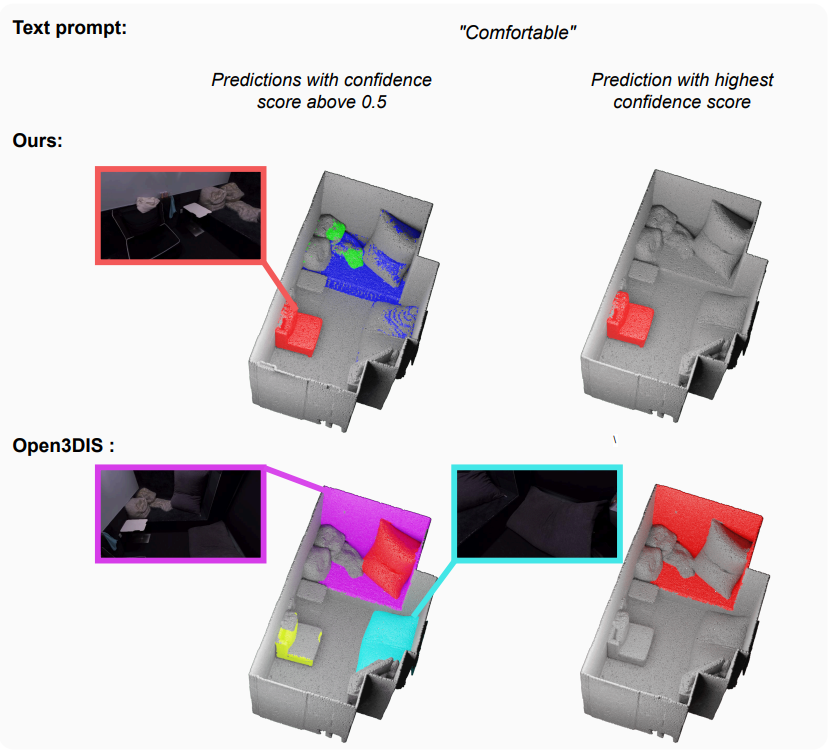
\ Qualitative results: We show qualitative results on the Replica dataset in Figure 4 and compare it to Open3DIS. Open3DIS shows good performance in recalling novel geometries that 3D proposal networks like Mask3D generally fail to capture (small-sized objects). However, it comes at the cost of very low precision due to the redundant masks with different class predictions.
\ Limitations: Our method makes use of a 3D proposal network only for proposal generation in order to reach high speed. Other proposal generation methods [32, 34] fuse 2D instance masks from a 2D instance segmentation methods to generate rich 3D proposals even for very small objects, which are generally overlooked by 3D proposal networks like Mask3D [39] due to low resolution in 3D. Thus, fast 2D instance segmentation models like FastSAM [56] can be used to generate 3D proposals from the 2D images, which might further improve the performance of our method.
\
6 Conclusion
We present Open-YOLO 3D, a novel and efficient open-vocabulary 3D instance segmentation method, which makes use of open-vocabulary 2D object detectors instead of heavy segmentation models. Our approach leverages a 2D object detector for class-labeled bounding boxes and a 3D instance segmentation network for class-agnostic masks. We propose to use MVPDist generated from multiview low granularity label maps to match text prompts to 3D class agnostic masks. Our proposed method outperforms existing techniques, with gains in mAP and inference speed. These results show a new direction toward more efficient open-vocabulary 3D instance segmentation models.
\
References
[1] S. Al Khatib, M. El Amine Boudjoghra, J. Lahoud, and F. S. Khan. 3d instance segmentation via enhanced spatial and semantic supervision. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 541–550, 2023.
\ [2] M. E. A. Boudjoghra, S. K. A. Khatib, J. Lahoud, H. Cholakkal, R. M. Anwer, S. Khan, and F. Khan. 3d indoor instance segmentation in an open-world. In Advances in Neural Information Processing Systems, 2023.
\ [3] M. Bucher, T.-H. Vu, M. Cord, and P. Pérez. Zero-shot semantic segmentation. Advances in Neural Information Processing Systems, 32, 2019.
\ [4] S. Chen, J. Fang, Q. Zhang, W. Liu, and X. Wang. Hierarchical aggregation for 3d instance segmentation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 15467–15476, 2021.
\ [5] B. Cheng, I. Misra, A. G. Schwing, A. Kirillov, and R. Girdhar. Masked-attention mask transformer for universal image segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 1290–1299, 2022.
\ [6] B. Cheng, A. Schwing, and A. Kirillov. Per-pixel classification is not all you need for semantic segmentation. Advances in Neural Information Processing Systems, 34:17864–17875, 2021.
\ [7] T. Cheng, L. Song, Y. Ge, W. Liu, X. Wang, and Y. Shan. Yolo-world: Real-time openvocabulary object detection. In Proc. IEEE Conf. Computer Vision and Pattern Recognition (CVPR), 2024.
\ [8] J. Chibane, F. Engelmann, T. Anh Tran, and G. Pons-Moll. Box2mask: Weakly supervised 3d semantic instance segmentation using bounding boxes. In Computer Vision–ECCV 2022: 17th European Conference, Tel Aviv, Israel, October 23–27, 2022, Proceedings, Part XXXI, pages 681–699. Springer, 2022.
\ [9] A. Dai, A. X. Chang, M. Savva, M. Halber, T. Funkhouser, and M. Nießner. Scannet: Richlyannotated 3d reconstructions of indoor scenes. In Proc. Computer Vision and Pattern Recognition (CVPR), IEEE, 2017.
\ [10] F. Engelmann, M. Bokeloh, A. Fathi, B. Leibe, and M. Nießner. 3d-mpa: Multi-proposal aggregation for 3d semantic instance segmentation. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 9031–9040, 2020.
\ [11] M. Ester, H.-P. Kriegel, J. Sander, and X. Xu. A density-based algorithm for discovering clusters in large spatial databases with noise. In Proceedings of the Second International Conference on Knowledge Discovery and Data Mining, KDD’96, page 226–231. AAAI Press, 1996.
\ [12] G. Ghiasi, X. Gu, Y. Cui, and T.-Y. Lin. Scaling open-vocabulary image segmentation with image-level labels. In European Conference on Computer Vision, pages 540–557. Springer, 2022.
\ [13] Q. Gu, A. Kuwajerwala, K. M. Jatavallabhula, B. Sen, A. Agarwal, C. Rivera, W. Paul, R. Chellappa, C. Gan, C. M. de Melo, et al. Conceptgraphs: Open-vocabulary 3d scene graphs for perception and planning. In 2nd Workshop on Language and Robot Learning: Language as Grounding, 2023.
\ [14] L. Han, T. Zheng, L. Xu, and L. Fang. Occuseg: Occupancy-aware 3d instance segmentation. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 2940–2949, 2020.
\ [15] T. He, C. Shen, and A. Van Den Hengel. Dyco3d: Robust instance segmentation of 3d point clouds through dynamic convolution. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 354–363, 2021.
\ [16] Y. Hong, C. Lin, Y. Du, Z. Chen, J. B. Tenenbaum, and C. Gan. 3d concept learning and reasoning from multi-view images. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 9202–9212, 2023.
\ [17] J. Hou, A. Dai, and M. Nießner. 3d-sis: 3d semantic instance segmentation of rgb-d scans. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 4421–4430, 2019.
\ [18] J. Hou, B. Graham, M. Nießner, and S. Xie. Exploring data-efficient 3d scene understanding with contrastive scene contexts. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 15587–15597, 2021.
\ [19] D. Huynh, J. Kuen, Z. Lin, J. Gu, and E. Elhamifar. Open-vocabulary instance segmentation via robust cross-modal pseudo-labeling. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 7020–7031, 2022.
\ [20] A. Jain, P. Katara, N. Gkanatsios, A. W. Harley, G. Sarch, K. Aggarwal, V. Chaudhary, and K. Fragkiadaki. Odin: A single model for 2d and 3d perception. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024.
\ [21] L. Jiang, H. Zhao, S. Shi, S. Liu, C.-W. Fu, and J. Jia. Pointgroup: Dual-set point grouping for 3d instance segmentation. In Proceedings of the IEEE/CVF conference on computer vision and Pattern recognition, pages 4867–4876, 2020.
\ [22] P. Kaul, W. Xie, and A. Zisserman. Multi-modal classifiers for open-vocabulary object detection. In International Conference on Machine Learning, 2023.
\ [23] A. Kirillov, E. Mintun, N. Ravi, H. Mao, C. Rolland, L. Gustafson, T. Xiao, S. Whitehead, A. C. Berg, W.-Y. Lo, et al. Segment anything. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 4015–4026, 2023.
\ [24] M. Kolodiazhnyi, A. Vorontsova, A. Konushin, and D. Rukhovich. Oneformer3d: One transformer for unified point cloud segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024.
\ [25] J. Lahoud, J. Cao, F. S. Khan, H. Cholakkal, R. M. Anwer, S. Khan, and M.-H. Yang. 3d vision with transformers: A survey, 2022.
\ [26] J. Lahoud, B. Ghanem, M. Pollefeys, and M. R. Oswald. 3d instance segmentation via multi-task metric learning. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 9256–9266, 2019.
\ [27] B. Li, K. Q. Weinberger, S. Belongie, V. Koltun, and R. Ranftl. Language-driven semantic segmentation. In International Conference on Learning Representations, 2021.
\ [28] F. Liang, B. Wu, X. Dai, K. Li, Y. Zhao, H. Zhang, P. Zhang, P. Vajda, and D. Marculescu. Openvocabulary semantic segmentation with mask-adapted clip. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 7061–7070, 2023.
\ [29] Z. Liang, Z. Li, S. Xu, M. Tan, and K. Jia. Instance segmentation in 3d scenes using semantic superpoint tree networks. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 2783–2792, 2021.
\ [30] S. Liu, Z. Zeng, T. Ren, F. Li, H. Zhang, J. Yang, C. Li, J. Yang, H. Su, J. Zhu, et al. Grounding dino: Marrying dino with grounded pre-training for open-set object detection. arXiv preprint arXiv:2303.05499, 2023.
\ [31] S.-H. Liu, S.-Y. Yu, S.-C. Wu, H.-T. Chen, and T.-L. Liu. Learning gaussian instance segmentation in point clouds. arXiv preprint arXiv:2007.09860, 2020.
\ [32] S. Lu, H. Chang, E. P. Jing, A. Boularias, and K. Bekris. Ovir-3d: Open-vocabulary 3d instance retrieval without training on 3d data. In Conference on Robot Learning, pages 1610–1620. PMLR, 2023.
\ [33] C. Ma, Y. Yuhuan, C. Ju, F. Zhang, Y. Zhang, and Y. Wang. Open-vocabulary semantic segmentation via attribute decomposition-aggregation. Advances in Neural Information Processing Systems, 36, 2024.
\ [34] P. D. Nguyen, T. D. Ngo, C. Gan, E. Kalogerakis, A. Tran, C. Pham, and K. Nguyen. Open3dis: Open-vocabulary 3d instance segmentation with 2d mask guidance. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024.
\ [35] S. Peng, K. Genova, C. Jiang, A. Tagliasacchi, M. Pollefeys, T. Funkhouser, et al. Openscene: 3d scene understanding with open vocabularies. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 815–824, 2023.
\ [36] C. Pham, T. Vu, and K. Nguyen. Lp-ovod: Open-vocabulary object detection by linear probing. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, pages 779–788, 2024.
\ [37] A. Radford, J. W. Kim, C. Hallacy, A. Ramesh, G. Goh, S. Agarwal, G. Sastry, A. Askell, P. Mishkin, J. Clark, et al. Learning transferable visual models from natural language supervision. In International conference on machine learning, pages 8748–8763. PMLR, 2021.
\ [38] D. Rozenberszki, O. Litany, and A. Dai. Language-grounded indoor 3d semantic segmentation in the wild. In Proceedings of the European Conference on Computer Vision (ECCV), 2022.
\ [39] J. Schult, F. Engelmann, A. Hermans, O. Litany, S. Tang, and B. Leibe. Mask3D: Mask Transformer for 3D Semantic Instance Segmentation. In International Conference on Robotics and Automation (ICRA), 2023.
\ [40] J. Straub, T. Whelan, L. Ma, Y. Chen, E. Wijmans, S. Green, J. J. Engel, R. Mur-Artal, C. Ren, S. Verma, A. Clarkson, M. Yan, B. Budge, Y. Yan, X. Pan, J. Yon, Y. Zou, K. Leon, N. Carter, J. Briales, T. Gillingham, E. Mueggler, L. Pesqueira, M. Savva, D. Batra, H. M. Strasdat, R. D. Nardi, M. Goesele, S. Lovegrove, and R. Newcombe. The replica dataset: A digital replica of indoor spaces, 2019.
\ [41] J. Sun, C. Qing, J. Tan, and X. Xu. Superpoint transformer for 3d scene instance segmentation. In Proceedings of the AAAI Conference on Artificial Intelligence, 2023.
\ [42] A. Takmaz, E. Fedele, R. Sumner, M. Pollefeys, F. Tombari, and F. Engelmann. Openmask3d: Open-vocabulary 3d instance segmentation. Advances in Neural Information Processing Systems, 36, 2023.
\ [43] A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, Ł. Kaiser, and I. Polosukhin. Attention is all you need. Advances in neural information processing systems, 30, 2017.
\ [44] V. VS, N. Yu, C. Xing, C. Qin, M. Gao, J. C. Niebles, V. M. Patel, and R. Xu. Mask-free ovis: Open-vocabulary instance segmentation without manual mask annotations. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 23539–23549, 2023.
\ [45] L. Wang, Y. Liu, P. Du, Z. Ding, Y. Liao, Q. Qi, B. Chen, and S. Liu. Object-aware distillation pyramid for open-vocabulary object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 11186–11196, 2023.
\ [46] W. Wang, R. Yu, Q. Huang, and U. Neumann. Sgpn: Similarity group proposal network for 3d point cloud instance segmentation. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 2569–2578, 2018.
\ [47] S. Xie, J. Gu, D. Guo, C. R. Qi, L. Guibas, and O. Litany. Pointcontrast: Unsupervised pretraining for 3d point cloud understanding. In Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, August 23–28, 2020, Proceedings, Part III 16, pages 574–591. Springer, 2020.
\ [48] J. Xu, S. De Mello, S. Liu, W. Byeon, T. Breuel, J. Kautz, and X. Wang. Groupvit: Semantic segmentation emerges from text supervision. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 18134–18144, 2022.
\ [49] B. Yang, J. Wang, R. Clark, Q. Hu, S. Wang, A. Markham, and N. Trigoni. Learning object bounding boxes for 3d instance segmentation on point clouds. Advances in neural information processing systems, 32, 2019.
\ [50] Y. Yang, X. Wu, T. He, H. Zhao, and X. Liu. Sam3d: Segment anything in 3d scenes, 2023.
\ [51] L. Yao, J. Han, X. Liang, D. Xu, W. Zhang, Z. Li, and H. Xu. Detclipv2: Scalable openvocabulary object detection pre-training via word-region alignment. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 23497–23506, 2023.
\ [52] L. Yi, W. Zhao, H. Wang, M. Sung, and L. J. Guibas. Gspn: Generative shape proposal network for 3d instance segmentation in point cloud. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 3947–3956, 2019.
\ [53] Y. Zang, W. Li, K. Zhou, C. Huang, and C. C. Loy. Open-vocabulary detr with conditional matching. In European Conference on Computer Vision, pages 106–122. Springer, 2022.
\ [54] B. Zhang and P. Wonka. Point cloud instance segmentation using probabilistic embeddings. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 8883–8892, 2021.
\ [55] J. Zhang, R. Dong, and K. Ma. Clip-fo3d: Learning free open-world 3d scene representations from 2d dense clip. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 2048–2059, 2023.
\ [56] X. Zhao, W. Ding, Y. An, Y. Du, T. Yu, M. Li, M. Tang, and J. Wang. Fast segment anything. arXiv preprint arXiv:2306.12156, 2023.
\ [57] Y. Zhao, W. Lv, S. Xu, J. Wei, G. Wang, Q. Dang, Y. Liu, and J. Chen. Detrs beat yolos on real-time object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2024.
\ [58] Y. Zhong, J. Yang, P. Zhang, C. Li, N. Codella, L. H. Li, L. Zhou, X. Dai, L. Yuan, Y. Li, et al. Regionclip: Region-based language-image pretraining. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 16793–16803, 2022.
\
A Appendix
\
\
\
\
\

\

\

\

\

\

\

\

\

\

\

\
:::info Authors:
(1) Mohamed El Amine Boudjoghra, Mohamed Bin Zayed University of Artificial Intelligence (MBZUAI) (mohamed.boudjoghra@mbzuai.ac.ae);
(2) Angela Dai, Technical University of Munich (TUM) (angela.dai@tum.de);
(3) Jean Lahoud, Mohamed Bin Zayed University of Artificial Intelligence (MBZUAI) ( jean.lahoud@mbzuai.ac.ae);
(4) Hisham Cholakkal, Mohamed Bin Zayed University of Artificial Intelligence (MBZUAI) (hisham.cholakkal@mbzuai.ac.ae);
(5) Rao Muhammad Anwer, Mohamed Bin Zayed University of Artificial Intelligence (MBZUAI) and Aalto University (rao.anwer@mbzuai.ac.ae);
(6) Salman Khan, Mohamed Bin Zayed University of Artificial Intelligence (MBZUAI) and Australian National University (salman.khan@mbzuai.ac.ae);
(7) Fahad Shahbaz Khan, Mohamed Bin Zayed University of Artificial Intelligence (MBZUAI) and Australian National University (fahad.khan@mbzuai.ac.ae).
:::
:::info This paper is available on arxiv under CC BY-NC-SA 4.0 Deed (Attribution-Noncommercial-Sharelike 4.0 International) license.
:::
\
This content originally appeared on HackerNoon and was authored by Instancing
Instancing | Sciencx (2025-08-26T08:36:43+00:00) A New Approach to 3D Scene Understanding: Replacing Heavy Segmentation Models for a 16x Speedup. Retrieved from https://www.scien.cx/2025/08/26/a-new-approach-to-3d-scene-understanding-replacing-heavy-segmentation-models-for-a-16x-speedup/
Please log in to upload a file.
There are no updates yet.
Click the Upload button above to add an update.