
This content originally appeared on Level Up Coding - Medium and was authored by Nikhilesh Pandey
Integrating AI into GSP Auctions to Balance Advertiser ROI, User Engagement, and Platform Growth

Introduction and Motivation
Search advertising is a key driver of revenue in the e-commerce ecosystem, helping platforms connect users with personalized, relevant content. The rise of big data and advances in AI, especially reinforcement learning (RL) open new possibilities for real-time ad optimization. Unlike traditional approaches that optimize revenue, cost, and relevance in isolation, RL enables systems to learn from user feedback and adapt dynamically.
Traditionally, ad ranking has been powered by Generalized Second-Price (GSP) auctions, which weigh advertiser bids and ad quality. While effective for simpler use cases, this static system struggles to keep pace with rapidly evolving user behavior and market dynamics.
This article explores how integrating RL into the GSP framework can help platforms balance three competing goals: maximizing revenue, improving advertiser’s cost-efficiency, and delivering more relevant ads to users. By modeling ad decisions as a sequential process, RL optimizes long-term outcomes based on key metrics like click-through rate (CTR), conversion rate (CVR), and gross merchandise volume (GMV).
To bridge the gap between theory and practice, a recent research paper proposes a hybrid training strategy that combines offline simulation with online evolutionary updates. This allows the system to train safely at scale while staying responsive to real-world changes like budget constraints and shifting user preferences.
What Is Search Advertising?
Search advertising is a type of digital marketing where businesses bid to have their ads appear in search engine results. When someone searches for a particular product or service, these ads show up alongside or above the organic results. Think of it like sponsored websites showing up on Google or promoted products displayed when you search on Amazon, it’s a way for brands to connect with people actively looking for what they offer.
Key Features of Search Ads:
- User Intent Alignment : Ads must match the user’s search intent, similar to organic search results, to ensure a positive experience.
- Pay-Per-Click (PPC) Model : Advertisers typically pay only when users click their ads (rather than per impression). This incentivizes platforms to prioritize relevance over just the highest bid, balancing profitability, advertiser ROI, and user experience.
- Auction-Based Delivery : Most platforms determine ad placement through a combination of bid amounts and ad relevance.
🔗 Learn more: Search advertising [6]
What’s the core problem we are trying to solve?
Imagine you’re scrolling through an e-commerce site (like Amazon or eBay). You search for “wireless headphones,” and you get some sponsored suggestions on search result. The platform must decide:
- Relevance: Which ads to show?
- Ranking: In what order?
- Pricing: How much should advertisers pay per click?
The challenge: Balancing three competing interests:
- Advertisers want maximum clicks at minimal cost.
- Users want relevant, useful ads.
- The platform (e.g., Amazon) wants to maximize revenue (RPM Revenue Per Mille/1000 impressions).
The research proposes using Reinforcement Learning + GSP auctions to optimize this trade-off dynamically.
What’s a GSP Auction, and Why Should You Care?
The Generalized Second-Price (GSP) auction is the behind-the-scenes engine that decides which ads you see when you search on platforms like Google.
- Advertisers place bids on keywords say, $2 per click for wireless headphones.
- It’s not just about who bids the most; ad quality also matters. Things like click-through rate (CTR) and relevance play a big role.
- The top spot goes to the advertiser with the best mix of bid and quality but here’s the twist: they don’t pay their own bid. Instead, they pay the amount the next-highest bidder offered (that’s where “second-price” comes in).
🔗 Learn more: GSP Auction Explained [5]
A sorting formula decides ad order based on:
- Bid (what the advertiser offers per click).
- CTR (Click-Through Rate — how often users click the ad).
- CVR (Conversion Rate — how often clicks lead to sales).
- Product price (higher-priced items may bring more profit).

- (s): The search context, representing the state or query environment.
- a = (a1, a2, …, a5): Parameters learned by the model to weigh different factors.
- (ad): The advertisement being evaluated.
- f : Feature function, where fₐᵢ = the i-th measurable attribute of ad parameter a that feeds into the ranking calculation.
- Balancing Interests : Parameters (a2) and (a4) act as adjustment weights to balance user satisfaction and purchase benefits against pure revenue considerations. This ensures that the sorting formula is not solely profit-driven but also aligns with delivering relevant ads that users are likely to engage with, fostering a sustainable advertising ecosystem.
Ranking and Pricing Mechanism
Using the sorting formula, ads are ranked by their calculated scores 𝝓, reflecting a combined measure of bid value and predicted user interaction metrics. The pricing for each ad is derived from the Generalized Second-Price (GSP) auction model, adjusted by the sorting formula’s components to fairly charge advertisers based on the value each ad provides.
We use ad, ad’ to represent advertisements ranked between two adjacent positions. According to GSP’s deduction calculation method, the current click deduction can be calculated as:

Problem: GSP alone doesn’t adapt to changing user behavior or market conditions. That’s where Reinforcement Learning comes in!
Reinforcement Learning Integration
The research paper[1] highlights the relevance of Reinforcement Learning in the advertising domain due to its ability to model sequential decision-making and optimize policies based on real-time user interaction feedback.
The parameters (a) in the click_price formula are not fixed but learned dynamically through reinforcement learning methods, such as Deep Deterministic Policy Gradient (DDPG) [2] and Evolution Strategies (ES). These approaches enable the system to adapt to changing user behaviors and market conditions by maximizing a reward function based on metrics like revenue per mille (RPM), CTR, conversion rate, and gross merchandise value (GMV). The learning process spans global user sequences, aiming to maximize long-term cumulative rewards rather than immediate outcomes.
System Architecture
The proposed system architecture is structured into three main components:
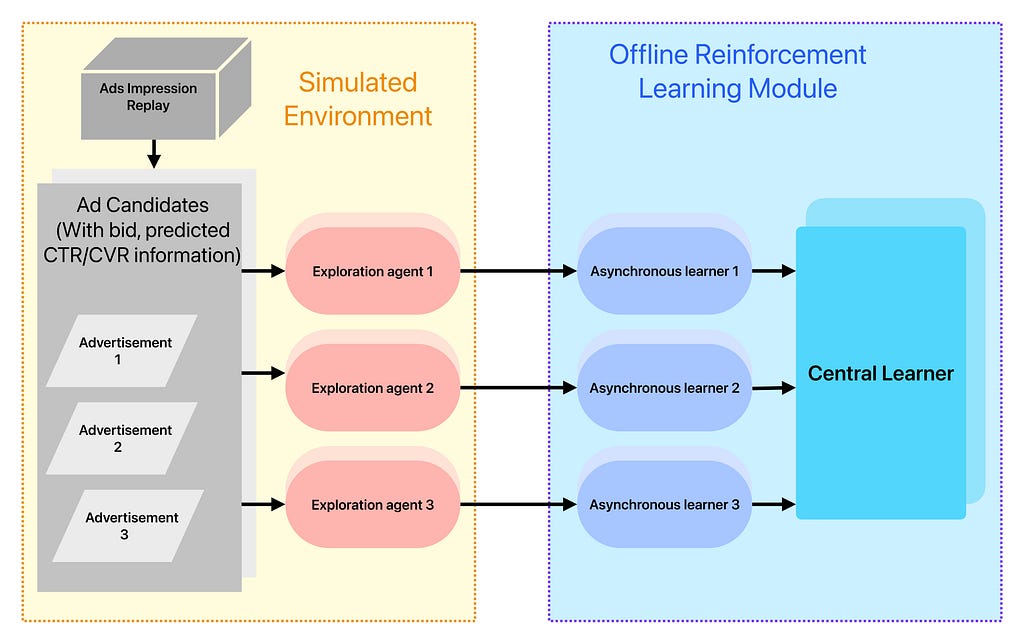
- Offline Search Advertising Simulation
The first module simulates a search advertising environment by mimicking user behaviors and ranking outcomes in an offline setting. This simulation generates a large volume of synthetic interaction data, including ad views and clicks, which helps train reinforcement learning models without impacting real users or platform revenue. By replicating complex real-world dynamics, the simulation provides a safe and efficient foundation for exploring various bidding and ranking strategies. - Offline Reinforcement Learning
Using data from the simulated environment, the second module trains policy models through reinforcement learning. The research paper employs the Deep Deterministic Policy Gradient (DDPG) algorithm, an off-policy, model-free approach well-suited to continuous action spaces. The architecture leverages actor-critic networks and embedding layers for feature representation, along with asynchronous multi-agent learning to accelerate convergence and improve stability. This component is responsible for optimizing strategies such as bid adjustments and ad placements to maximize long-term reward. - Online Strategy Optimization
After offline training, the learned model is further refined in a live environment. The algorithm adopts an Evolution Strategy (ES) approach for this phase. ES introduces stochastic perturbations (Gaussian noise) to model parameters and uses cumulative reward signals to guide updates without requiring gradient computations. This approach enables scalable, distributed optimization while minimizing communication overhead. Additionally, ES allows the evaluation of entire user sessions (episodes), which helps mitigate the challenges of sparse or delayed rewards.
Reward Function Design
A critical aspect of the methodology is the reward function that drives the learning process. The function aims to strike a balance between platform revenue and user engagement. It is defined as:

Where:
- CTR is the click-through rate,
- click_price represents the advertiser’s cost per click,
- δ is a tunable factor to balance the emphasis between click value and volume.
This formulation encourages strategies that generate both high engagement (via clicks) and financial return (via click price), aligning the interests of platforms, advertisers, and users.
Online Model Optimization
Despite effective offline policy exploration, the simulation model cannot capture all real-world environmental factors, such as advertiser budgets and bid variability. To address this, the online learning module uses Evolution Strategy, a derivative-free optimization method that perturbs model parameters with Gaussian noise and updates them based on observed rewards. This approach reduces computational complexity and communication overhead in distributed settings and effectively manages sparse reward signals.
What’s Evolution Strategy (ES) Doing Here?
Imagine tuning a guitar by randomly adjusting knobs and keeping what sounds best, that’s ES!
- Instead of gradients (like in DDPG), ES adds noise to model weights.
- If noise improves RPM/CTR → Keep changes!
- Handles sparse rewards (not every ad click gives clear feedback).
- Works well in real-time (less computational overhead).
Algorithm: Asynchronous DDPG Learning
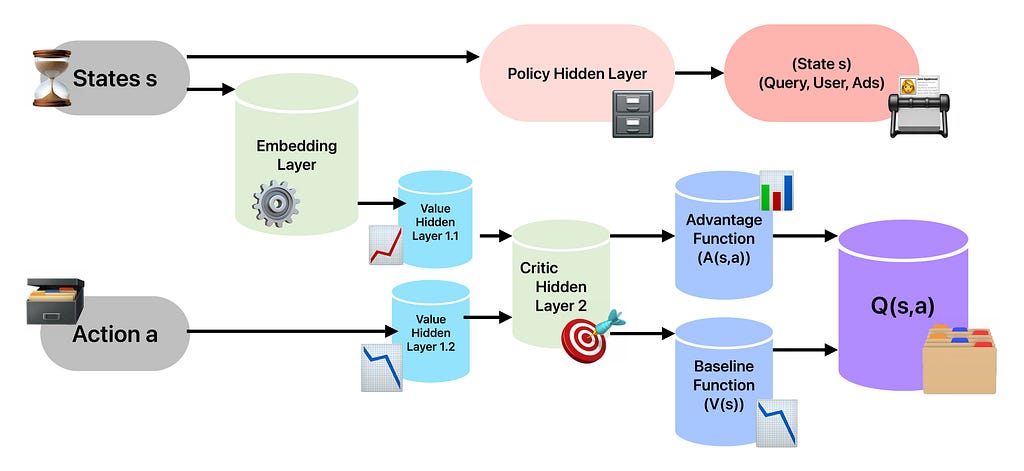
An asynchronous DDPG learning algorithm is applied, involving: initializing critic and actor networks, sampling simulated transitions, computing critic loss and gradients, updating network parameters via gradient descent, and slowly updating target networks until convergence. This process allows stable and effective reinforcement learning on the offline simulation data.
Example: Imagine 10 workers simulating ad placements simultaneously, sharing insights to improve the global ranking strategy!
Why Use Asynchronous DDPG?
- Faster Learning: Parallel workers explore more data.
- Stability: Target networks prevent sudden bad updates.
- Scalability: Works for complex tasks (like ad auctions).
Algorithm :

Experiment Analysis and Discussion
The study addresses three critical research questions to evaluate the effectiveness of the proposed reinforcement learning framework for ad ranking optimization:
1. Model Convergence
Objective: Determine whether the RL model converges to an optimal solution.
Methodology:
- Used a simplified input setup, starting with only query IDs to establish a performance baseline.
- Allowed the model to explore a range of parameter configurations, progressively incorporating more complex features.
- Compared the results with those obtained using Deep Deterministic Policy Gradient (DDPG) to benchmark convergence.
Findings:
- The RL model reliably converged to near-optimal parameter values, validating its effectiveness in the ad ranking context.
- Incorporating dueling network architectures, which separately estimate value and advantage functions significantly improved both convergence speed and training stability.
2. Impact of Network Architecture and Parameter Design
Objective: Assess how model architecture choices and parameter configurations affect training performance.
Methodology:
- Compared standard neural networks with dueling architectures.
- Tested various batch sizes to examine their effect on convergence stability.
- Evaluated fixed learning rates versus decaying schedules.
Findings:
- Dueling architectures consistently outperformed standard networks by more effectively separating state value from action advantage estimation, leading to faster and more stable convergence.
- Larger batch sizes (e.g., 50 million samples) combined with L2 regularization reduced loss fluctuations and improved training consistency.
- Learning rate decay strategies achieved stronger final performance than fixed rates, balancing rapid early training progress with controlled fine-tuning.
3. Benefits of Online Updating
Objective: Quantify the advantages of continuous, real-time policy adaptation.
Methodology:
- Deployed the model in a live environment using an Evolution Strategy–based online updating mechanism.
- Monitored system performance over a 30-day period.
Findings:

- The platform achieved a peak revenue increase of 4.45%, a peak click-through rate rise of 3.1%, and a peak advertiser cost reduction of 2.0%, demonstrating improvements in both user engagement and advertiser ROI.
- Continuous adaptation allowed the system to respond effectively to shifting user preferences and market dynamics, sustaining performance gains throughout the test period.
Conclusion
The integration of reinforcement learning with GSP auction models significantly enhances search advertising strategies, balancing the needs of advertisers, users, and platforms while optimizing revenue and user satisfaction. Future work will explore adapting the model to diverse digital advertising environments, refining learning algorithms, and addressing challenges related to data quality and dynamic market conditions to create more autonomous and efficient advertising systems.
References
- [1] Chang Zhou, Yang Zhao, Jin Cao, Yi Shen, Xiaoling Cui, Chiyu Cheng, https://arxiv.org/abs/2405.13381
- [2] Deep Deterministic Policy Gradients (DDPG) Explained, https://towardsdatascience.com/deep-deterministic-policy-gradients-explained-4643c1f71b2e/
- [3] Asynchronous Methods for Deep Reinforcement Learning, https://arxiv.org/abs/1602.01783
- [4] Policy Gradient Algorithms: DDPG, https://lilianweng.github.io/posts/2018-04-08-policy-gradient/#ddpg
- [5] Generalized second-price auction, https://en.wikipedia.org/wiki/Generalized_second-price_auction
- [6] Search advertising, https://en.wikipedia.org/wiki/Search_advertising
Beyond Static Bidding: AI-Driven Dynamic Optimization for Search Advertising was originally published in Level Up Coding on Medium, where people are continuing the conversation by highlighting and responding to this story.
This content originally appeared on Level Up Coding - Medium and was authored by Nikhilesh Pandey
Nikhilesh Pandey | Sciencx (2025-08-27T14:36:52+00:00) Beyond Static Bidding: AI-Driven Dynamic Optimization for Search Advertising. Retrieved from https://www.scien.cx/2025/08/27/beyond-static-bidding-ai-driven-dynamic-optimization-for-search-advertising/
Please log in to upload a file.
There are no updates yet.
Click the Upload button above to add an update.